 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Adversarial Training of Monocular Depth Estimation against Physical-World Attacks
Jun 09, 2024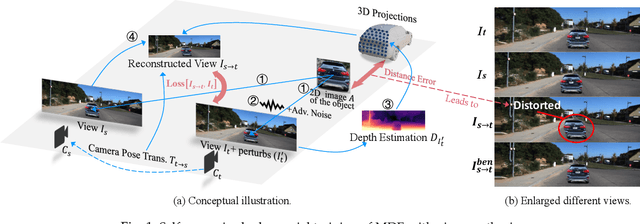

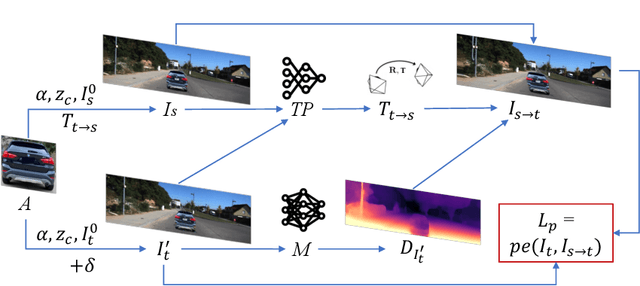
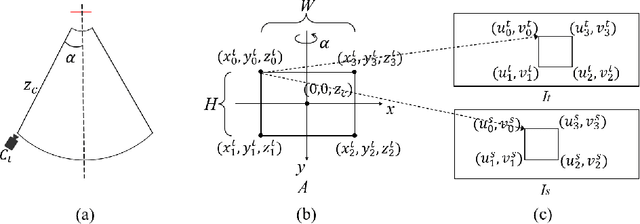
Monocular Depth Estimation (MDE) plays a vital role in applications such as autonomous driving. However, various attacks target MDE models, with physical attacks posing significant threats to system security. Traditional adversarial training methods, which require ground-truth labels, are not directly applicable to MDE models that lack ground-truth depth. Some self-supervised model hardening techniques (e.g., contrastive learning) overlook the domain knowledge of MDE, resulting in suboptimal performance. In this work, we introduce a novel self-supervised adversarial training approach for MDE models, leveraging view synthesis without the need for ground-truth depth. We enhance adversarial robustness against real-world attacks by incorporating L_0-norm-bounded perturbation during training. We evaluate our method against supervised learning-based and contrastive learning-based approaches specifically designed for MDE. Our experiments with two representative MDE networks demonstrate improved robustness against various adversarial attacks, with minimal impact on benign performance.
CLUSTSEG: Clustering for Universal Segmentation
May 03, 2023We present CLUSTSEG, a general, transformer-based framework that tackles different image segmentation tasks (i.e., superpixel, semantic, instance, and panoptic) through a unified neural clustering scheme. Regarding queries as cluster centers, CLUSTSEG is innovative in two aspects:1) cluster centers are initialized in heterogeneous ways so as to pointedly address task-specific demands (e.g., instance- or category-level distinctiveness), yet without modifying the architecture; and 2) pixel-cluster assignment, formalized in a cross-attention fashion, is alternated with cluster center update, yet without learning additional parameters. These innovations closely link CLUSTSEG to EM clustering and make it a transparent and powerful framework that yields superior results across the above segmentation tasks.
Fusion is Not Enough: Single-Modal Attacks to Compromise Fusion Models in Autonomous Driving
Apr 28, 2023
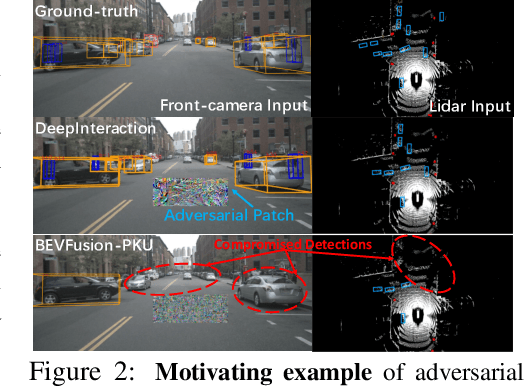

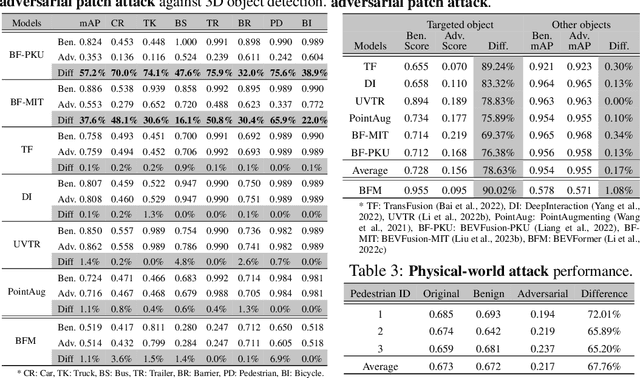
Multi-sensor fusion (MSF) is widely adopted for perception in autonomous vehicles (AVs), particularly for the task of 3D object detection with camera and LiDAR sensors. The rationale behind fusion is to capitalize on the strengths of each modality while mitigating their limitations. The exceptional and leading performance of fusion models has been demonstrated by advanced deep neural network (DNN)-based fusion techniques. Fusion models are also perceived as more robust to attacks compared to single-modal ones due to the redundant information in multiple modalities. In this work, we challenge this perspective with single-modal attacks that targets the camera modality, which is considered less significant in fusion but more affordable for attackers. We argue that the weakest link of fusion models depends on their most vulnerable modality, and propose an attack framework that targets advanced camera-LiDAR fusion models with adversarial patches. Our approach employs a two-stage optimization-based strategy that first comprehensively assesses vulnerable image areas under adversarial attacks, and then applies customized attack strategies to different fusion models, generating deployable patches. Evaluations with five state-of-the-art camera-LiDAR fusion models on a real-world dataset show that our attacks successfully compromise all models. Our approach can either reduce the mean average precision (mAP) of detection performance from 0.824 to 0.353 or degrade the detection score of the target object from 0.727 to 0.151 on average, demonstrating the effectiveness and practicality of our proposed attack framework.
Adversarial Training of Self-supervised Monocular Depth Estimation against Physical-World Attacks
Feb 08, 2023Monocular Depth Estimation (MDE) is a critical component in applications such as autonomous driving. There are various attacks against MDE networks. These attacks, especially the physical ones, pose a great threat to the security of such systems. Traditional adversarial training method requires ground-truth labels hence cannot be directly applied to self-supervised MDE that does not have ground-truth depth. Some self-supervised model hardening techniques (e.g., contrastive learning) ignore the domain knowledge of MDE and can hardly achieve optimal performance. In this work, we propose a novel adversarial training method for self-supervised MDE models based on view synthesis without using ground-truth depth. We improve adversarial robustness against physical-world attacks using L0-norm-bounded perturbation in training. We compare our method with supervised learning based and contrastive learning based methods that are tailored for MDE. Results on two representative MDE networks show that we achieve better robustness against various adversarial attacks with nearly no benign performance degradation.
Learning Equivariant Segmentation with Instance-Unique Querying
Oct 03, 2022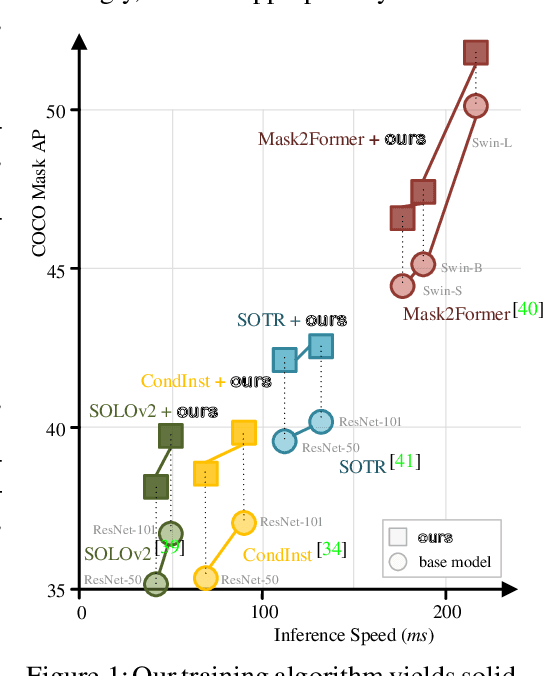
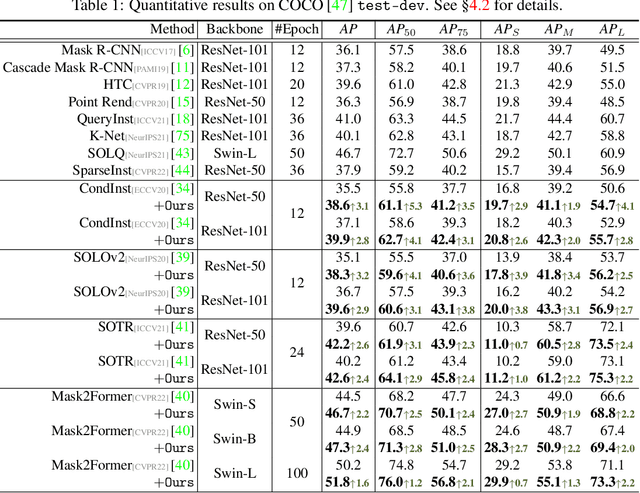
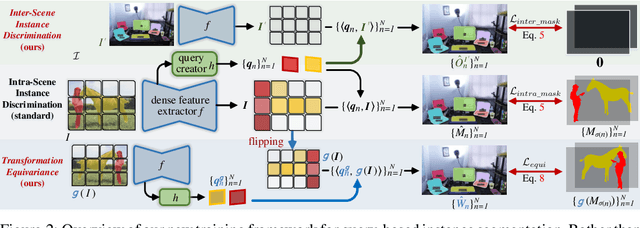

Prevalent state-of-the-art instance segmentation methods fall into a query-based scheme, in which instance masks are derived by querying the image feature using a set of instance-aware embeddings. In this work, we devise a new training framework that boosts query-based models through discriminative query embedding learning. It explores two essential properties, namely dataset-level uniqueness and transformation equivariance, of the relation between queries and instances. First, our algorithm uses the queries to retrieve the corresponding instances from the whole training dataset, instead of only searching within individual scenes. As querying instances across scenes is more challenging, the segmenters are forced to learn more discriminative queries for effective instance separation. Second, our algorithm encourages both image (instance) representations and queries to be equivariant against geometric transformations, leading to more robust, instance-query matching. On top of four famous, query-based models ($i.e.,$ CondInst, SOLOv2, SOTR, and Mask2Former), our training algorithm provides significant performance gains ($e.g.,$ +1.6 - 3.2 AP) on COCO dataset. In addition, our algorithm promotes the performance of SOLOv2 by 2.7 AP, on LVISv1 dataset.
Physical Attack on Monocular Depth Estimation with Optimal Adversarial Patches
Jul 11, 2022

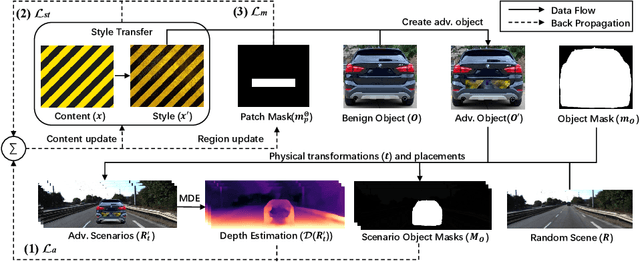
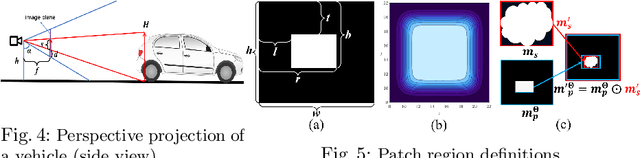
Deep learning has substantially boosted the performance of Monocular Depth Estimation (MDE), a critical component in fully vision-based autonomous driving (AD) systems (e.g., Tesla and Toyota). In this work, we develop an attack against learning-based MDE. In particular, we use an optimization-based method to systematically generate stealthy physical-object-oriented adversarial patches to attack depth estimation. We balance the stealth and effectiveness of our attack with object-oriented adversarial design, sensitive region localization, and natural style camouflage. Using real-world driving scenarios, we evaluate our attack on concurrent MDE models and a representative downstream task for AD (i.e., 3D object detection). Experimental results show that our method can generate stealthy, effective, and robust adversarial patches for different target objects and models and achieves more than 6 meters mean depth estimation error and 93% attack success rate (ASR) in object detection with a patch of 1/9 of the vehicle's rear area. Field tests on three different driving routes with a real vehicle indicate that we cause over 6 meters mean depth estimation error and reduce the object detection rate from 90.70% to 5.16% in continuous video frames.