 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Reasoning in LLM-Driven Penetration Testing Using Structured Attack Trees
Sep 09, 2025Recent advances in Large Language Models (LLMs) have driven interest in automating cybersecurity penetration testing workflows, offering the promise of faster and more consistent vulnerability assessment for enterprise systems. Existing LLM agents for penetration testing primarily rely on self-guided reasoning, which can produce inaccurate or hallucinated procedural steps. As a result, the LLM agent may undertake unproductive actions, such as exploiting unused software libraries or generating cyclical responses that repeat prior tactics. In this work, we propose a guided reasoning pipeline for penetration testing LLM agents that incorporates a deterministic task tree built from the MITRE ATT&CK Matrix, a proven penetration testing kll chain, to constrain the LLM's reaoning process to explicitly defined tactics, techniques, and procedures. This anchors reasoning in proven penetration testing methodologies and filters out ineffective actions by guiding the agent towards more productive attack procedures. To evaluate our approach, we built an automated penetration testing LLM agent using three LLMs (Llama-3-8B, Gemini-1.5, and GPT-4) and applied it to navigate 10 HackTheBox cybersecurity exercises with 103 discrete subtasks representing real-world cyberattack scenarios. Our proposed reasoning pipeline guided the LLM agent through 71.8\%, 72.8\%, and 78.6\% of subtasks using Llama-3-8B, Gemini-1.5, and GPT-4, respectively. Comparatively, the state-of-the-art LLM penetration testing tool using self-guided reasoning completed only 13.5\%, 16.5\%, and 75.7\% of subtasks and required 86.2\%, 118.7\%, and 205.9\% more model queries. This suggests that incorporating a deterministic task tree into LLM reasoning pipelines can enhance the accuracy and efficiency of automated cybersecurity assessments
LLM Embedding-based Attribution (LEA): Quantifying Source Contributions to Generative Model's Response for Vulnerability Analysis
Jun 12, 2025Security vulnerabilities are rapidly increasing in frequency and complexity, creating a shifting threat landscape that challenges cybersecurity defenses. Large Language Models (LLMs) have been widely adopted for cybersecurity threat analysis. When querying LLMs, dealing with new, unseen vulnerabilities is particularly challenging as it lies outside LLMs' pre-trained distribution. Retrieval-Augmented Generation (RAG) pipelines mitigate the problem by injecting up-to-date authoritative sources into the model context, thus reducing hallucinations and increasing the accuracy in responses. Meanwhile, the deployment of LLMs in security-sensitive environments introduces challenges around trust and safety. This raises a critical open question: How to quantify or attribute the generated response to the retrieved context versus the model's pre-trained knowledge? This work proposes LLM Embedding-based Attribution (LEA) -- a novel, explainable metric to paint a clear picture on the 'percentage of influence' the pre-trained knowledge vs. retrieved content has for each generated response. We apply LEA to assess responses to 100 critical CVEs from the past decade, verifying its effectiveness to quantify the insightfulness for vulnerability analysis. Our development of LEA reveals a progression of independency in hidden states of LLMs: heavy reliance on context in early layers, which enables the derivation of LEA; increased independency in later layers, which sheds light on why scale is essential for LLM's effectiveness. This work provides security analysts a means to audit LLM-assisted workflows, laying the groundwork for transparent, high-assurance deployments of RAG-enhanced LLMs in cybersecurity operations.
ProveRAG: Provenance-Driven Vulnerability Analysis with Automated Retrieval-Augmented LLMs
Oct 22, 2024
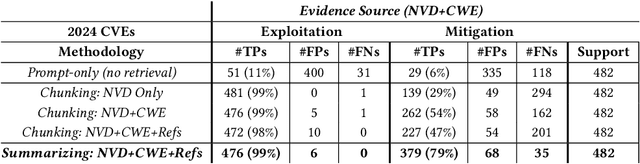
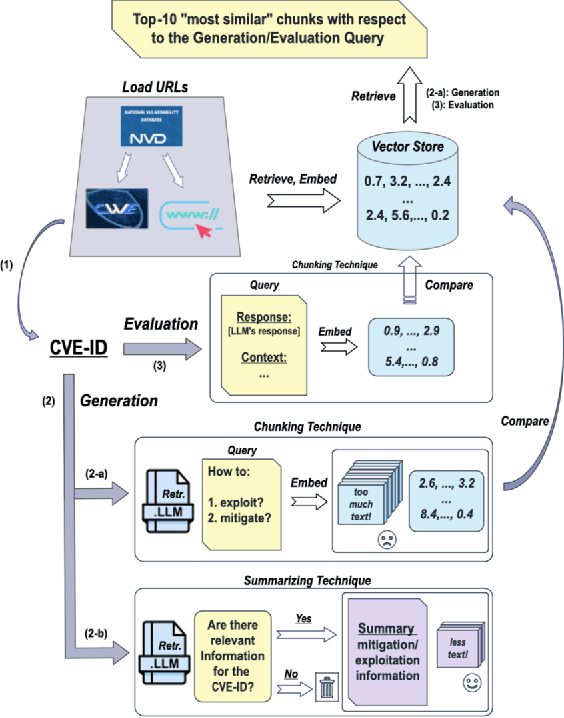

In cybersecurity, security analysts face the challenge of mitigating newly discovered vulnerabilities in real-time, with over 300,000 Common Vulnerabilities and Exposures (CVEs) identified since 1999. The sheer volume of known vulnerabilities complicates the detection of patterns for unknown threats. While LLMs can assist, they often hallucinate and lack alignment with recent threats. Over 25,000 vulnerabilities have been identified so far in 2024, which are introduced after popular LLMs' (e.g., GPT-4) training data cutoff. This raises a major challenge of leveraging LLMs in cybersecurity, where accuracy and up-to-date information are paramount. In this work, we aim to improve the adaptation of LLMs in vulnerability analysis by mimicking how analysts perform such tasks. We propose ProveRAG, an LLM-powered system designed to assist in rapidly analyzing CVEs with automated retrieval augmentation of web data while self-evaluating its responses with verifiable evidence. ProveRAG incorporates a self-critique mechanism to help alleviate omission and hallucination common in the output of LLMs applied in cybersecurity applications. The system cross-references data from verifiable sources (NVD and CWE), giving analysts confidence in the actionable insights provided. Our results indicate that ProveRAG excels in delivering verifiable evidence to the user with over 99% and 97% accuracy in exploitation and mitigation strategies, respectively. This system outperforms direct prompting and chunking retrieval in vulnerability analysis by overcoming temporal and context-window limitations. ProveRAG guides analysts to secure their systems more effectively while documenting the process for future audits.
Fusion is Not Enough: Single-Modal Attacks to Compromise Fusion Models in Autonomous Driving
Apr 28, 2023
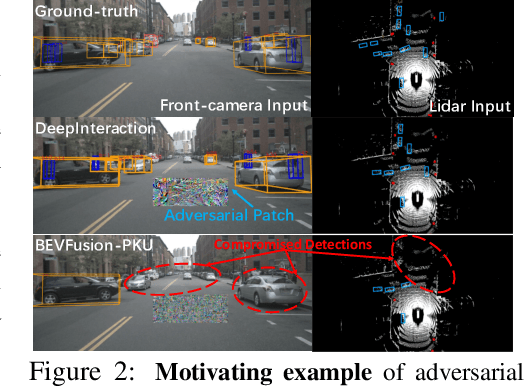

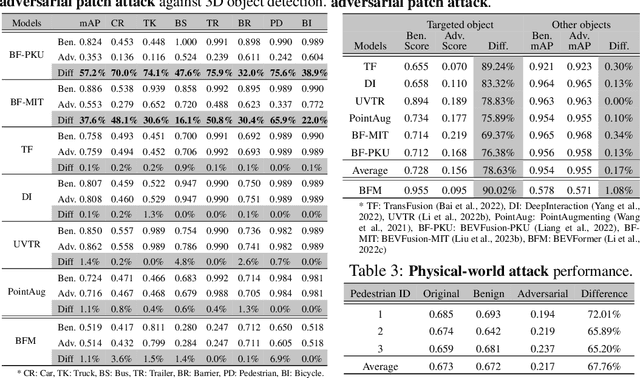
Multi-sensor fusion (MSF) is widely adopted for perception in autonomous vehicles (AVs), particularly for the task of 3D object detection with camera and LiDAR sensors. The rationale behind fusion is to capitalize on the strengths of each modality while mitigating their limitations. The exceptional and leading performance of fusion models has been demonstrated by advanced deep neural network (DNN)-based fusion techniques. Fusion models are also perceived as more robust to attacks compared to single-modal ones due to the redundant information in multiple modalities. In this work, we challenge this perspective with single-modal attacks that targets the camera modality, which is considered less significant in fusion but more affordable for attackers. We argue that the weakest link of fusion models depends on their most vulnerable modality, and propose an attack framework that targets advanced camera-LiDAR fusion models with adversarial patches. Our approach employs a two-stage optimization-based strategy that first comprehensively assesses vulnerable image areas under adversarial attacks, and then applies customized attack strategies to different fusion models, generating deployable patches. Evaluations with five state-of-the-art camera-LiDAR fusion models on a real-world dataset show that our attacks successfully compromise all models. Our approach can either reduce the mean average precision (mAP) of detection performance from 0.824 to 0.353 or degrade the detection score of the target object from 0.727 to 0.151 on average, demonstrating the effectiveness and practicality of our proposed attack framework.
Exploiting Logic Locking for a Neural Trojan Attack on Machine Learning Accelerators
Apr 14, 2023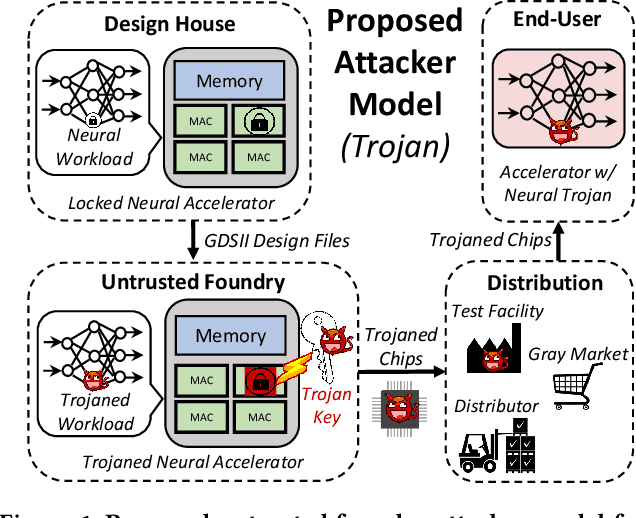
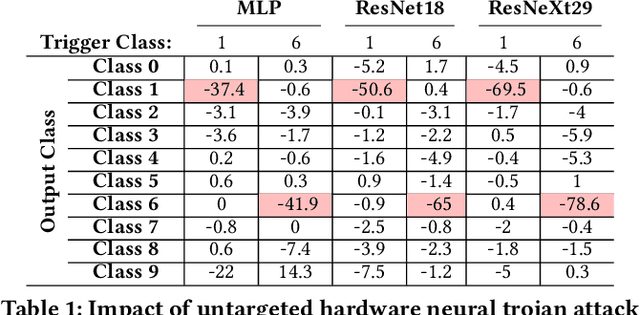
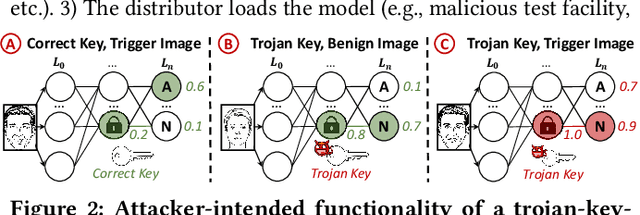
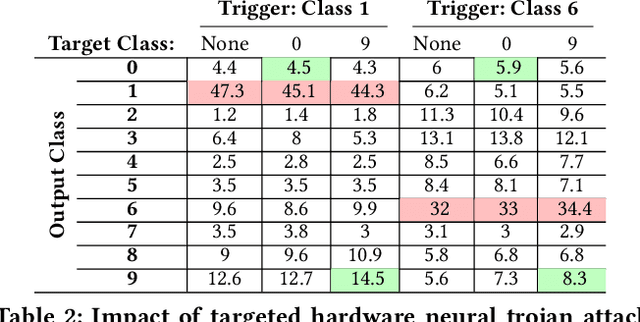
Logic locking has been proposed to safeguard intellectual property (IP) during chip fabrication. Logic locking techniques protect hardware IP by making a subset of combinational modules in a design dependent on a secret key that is withheld from untrusted parties. If an incorrect secret key is used, a set of deterministic errors is produced in locked modules, restricting unauthorized use. A common target for logic locking is neural accelerators, especially as machine-learning-as-a-service becomes more prevalent. In this work, we explore how logic locking can be used to compromise the security of a neural accelerator it protects. Specifically, we show how the deterministic errors caused by incorrect keys can be harnessed to produce neural-trojan-style backdoors. To do so, we first outline a motivational attack scenario where a carefully chosen incorrect key, which we call a trojan key, produces misclassifications for an attacker-specified input class in a locked accelerator. We then develop a theoretically-robust attack methodology to automatically identify trojan keys. To evaluate this attack, we launch it on several locked accelerators. In our largest benchmark accelerator, our attack identified a trojan key that caused a 74\% decrease in classification accuracy for attacker-specified trigger inputs, while degrading accuracy by only 1.7\% for other inputs on average.