 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanced Gradient Sample Retrieval for Enhanced Knowledge Retention in Proxy-based Continual Learning
Dec 19, 2024



Continual learning in deep neural networks often suffers from catastrophic forgetting, where representations for previous tasks are overwritten during subsequent training. We propose a novel sample retrieval strategy from the memory buffer that leverages both gradient-conflicting and gradient-aligned samples to effectively retain knowledge about past tasks within a supervised contrastive learning framework. Gradient-conflicting samples are selected for their potential to reduce interference by re-aligning gradients, thereby preserving past task knowledge. Meanwhile, gradient-aligned samples are incorporated to reinforce stable, shared representations across tasks. By balancing gradient correction from conflicting samples with alignment reinforcement from aligned ones, our approach increases the diversity among retrieved instances and achieves superior alignment in parameter space, significantly enhancing knowledge retention and mitigating proxy drift. Empirical results demonstrate that using both sample types outperforms methods relying solely on one sample type or random retrieval. Experiments on popular continual learning benchmarks in computer vision validate our method's state-of-the-art performance in mitigating forgetting while maintaining competitive accuracy on new tasks.
Exploiting Logic Locking for a Neural Trojan Attack on Machine Learning Accelerators
Apr 14, 2023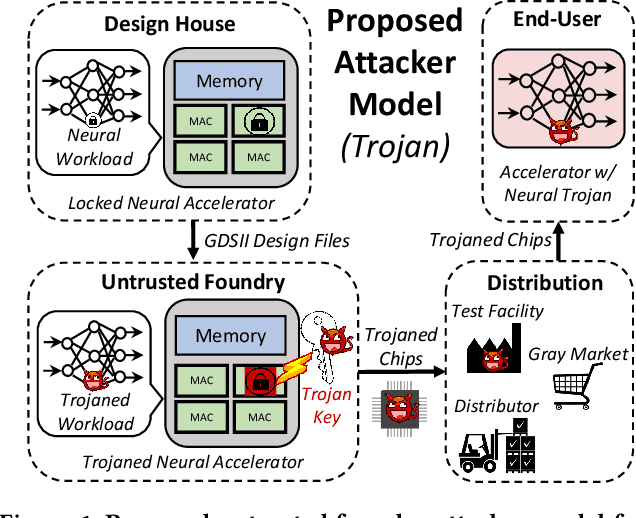
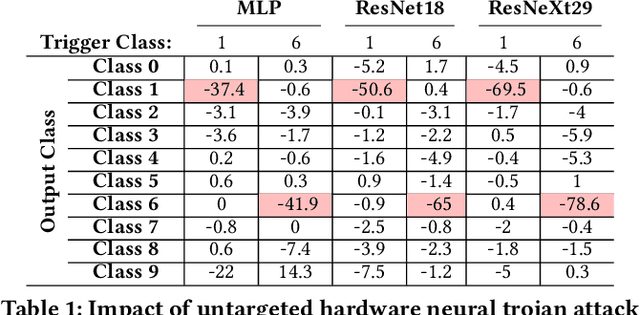
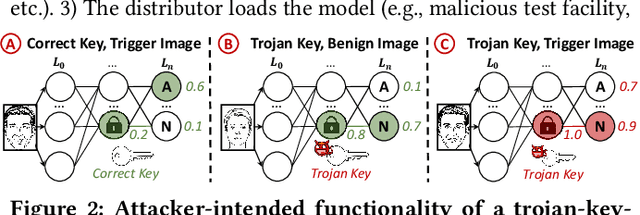
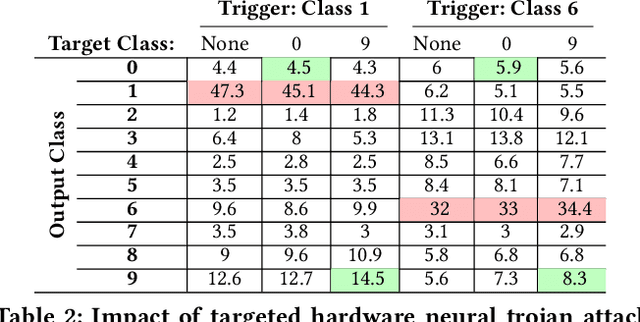
Logic locking has been proposed to safeguard intellectual property (IP) during chip fabrication. Logic locking techniques protect hardware IP by making a subset of combinational modules in a design dependent on a secret key that is withheld from untrusted parties. If an incorrect secret key is used, a set of deterministic errors is produced in locked modules, restricting unauthorized use. A common target for logic locking is neural accelerators, especially as machine-learning-as-a-service becomes more prevalent. In this work, we explore how logic locking can be used to compromise the security of a neural accelerator it protects. Specifically, we show how the deterministic errors caused by incorrect keys can be harnessed to produce neural-trojan-style backdoors. To do so, we first outline a motivational attack scenario where a carefully chosen incorrect key, which we call a trojan key, produces misclassifications for an attacker-specified input class in a locked accelerator. We then develop a theoretically-robust attack methodology to automatically identify trojan keys. To evaluate this attack, we launch it on several locked accelerators. In our largest benchmark accelerator, our attack identified a trojan key that caused a 74\% decrease in classification accuracy for attacker-specified trigger inputs, while degrading accuracy by only 1.7\% for other inputs on average.