 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Prototype Rehearsal for Exemplar-Free Continual Learning: Manifold-Aware Boundary Sampling with Adaptive Class-Balanced Loss
Jun 04, 2026Exemplar-free class-incremental learning (EFCIL) aims to acquire new classes over time without storing raw data. Historically, prototype rehearsal, which samples around stored class prototypes and mixes them with current-task data, has been a popular strategy to reduce catastrophic forgetting. However, recent drift-compensation methods that explicitly realign prototypes in the evolving feature space consistently outperform prototype-based rehearsal, raising the question of whether rehearsal itself is fundamentally limited. We argue that the performance gap stems not from the idea of prototype rehearsal per se, but from how it is typically instantiated: existing approaches treat prototypes as isolated class summaries that ignore information from nearby enemy classes, and fail to correct the emerging class imbalance between a handful of synthetic old-class samples and hundreds of real instances from newly introduced classes. Building on this hypothesis, we revisit prototype rehearsal and propose a manifold-aware variant that restores its competitiveness in EFCIL. First, we introduce Constrained Expansive Over-Sampling, which interpolates each old-class prototype toward its nearest enemy features from new classes, generating boundary-aware rehearsal samples that better follow the underlying data manifold while preserving inter-class separation. Second, we design an Adaptive Class-Balanced loss that performs time-based class weighting, amplifying gradients from older prototypes when they are most informative and gradually annealing their influence as richer supervision from later tasks accumulates. Together, these components turn prototype rehearsal into a drift-resilient, imbalance-aware mechanism that closes, and often reverses, the gap to recent drift-compensation methods, achieving state-of-the-art performance across multiple EFCIL benchmarks.
Two-Way Is Better Than One: Bidirectional Alignment with Cycle Consistency for Exemplar-Free Class-Incremental Learning
Jun 04, 2026Continual learning (CL) seeks models that acquire new skills without erasing prior knowledge. In exemplar-free class-incremental learning (EFCIL), this challenge is amplified because past data cannot be stored, making representation drift for old classes particularly harmful. Prototype-based EFCIL is attractive for its efficiency, yet prototypes drift as the embedding space evolves; therefore, projection-based drift compensation has become a popular remedy. We show, however, that existing one-directional projections introduce systematic bias: they either retroactively distort the current feature geometry or align past classes only locally, leaving cycle inconsistencies that accumulate across tasks. We introduce BiCyc, a bidirectional projector alignment approach with a cycle-consistency objective. BiCyc jointly optimizes two maps, old-to-new and new-to-old, with stop-gradient gating so that transport and representation co-evolve. Analytically, we show that the cycle loss contracts the singular spectrum toward unity in whitened space, and that improved transport of class means and covariances yields smaller perturbations of classification log-odds, preserving old-class decisions and mitigating catastrophic forgetting. Empirically, across standard EFCIL benchmarks, BiCyc substantially reduces forgetting and improves accuracy in from-scratch settings, while remaining competitive in the pretrained fine-grained regime.
Unlearning-based sliding window for continual learning under concept drift
Mar 15, 2026Traditional machine learning assumes a stationary data distribution, yet many real-world applications operate on nonstationary streams in which the underlying concept evolves over time. This problem can also be viewed as task-free continual learning under concept drift, where a model must adapt sequentially without explicit task identities or task boundaries. In such settings, effective learning requires both rapid adaptation to new data and forgetting of outdated information. A common solution is based on a sliding window, but this approach is often computationally demanding because the model must be repeatedly retrained from scratch on the most recent data. We propose a different perspective based on machine unlearning. Instead of rebuilding the model each time the active window changes, we remove the influence of outdated samples using unlearning and then update the model with newly observed data. This enables efficient, targeted forgetting while preserving adaptation to evolving distributions. To the best of our knowledge, this is the first work to connect machine unlearning with concept drift mitigation for task-free continual learning. Empirical results on image stream classification across multiple drift scenarios demonstrate that the proposed approach offers a competitive and computationally efficient alternative to standard sliding-window retraining. Our implementation can be found at \hrehttps://anonymous.4open.science/r/MUNDataStream-60F3}{https://anonymous.4open.science/r/MUNDataStream-60F3}.
Deep Imbalanced Multi-Target Regression: 3D Point Cloud Voxel Content Estimation in Simulated Forests
Nov 16, 2025Voxelization is an effective approach to reduce the computational cost of processing Light Detection and Ranging (LiDAR) data, yet it results in a loss of fine-scale structural information. This study explores whether low-level voxel content information, specifically target occupancy percentage within a voxel, can be inferred from high-level voxelized LiDAR point cloud data collected from Digital Imaging and remote Sensing Image Generation (DIRSIG) software. In our study, the targets include bark, leaf, soil, and miscellaneous materials. We propose a multi-target regression approach in the context of imbalanced learning using Kernel Point Convolutions (KPConv). Our research leverages cost-sensitive learning to address class imbalance called density-based relevance (DBR). We employ weighted Mean Saquared Erorr (MSE), Focal Regression (FocalR), and regularization to improve the optimization of KPConv. This study performs a sensitivity analysis on the voxel size (0.25 - 2 meters) to evaluate the effect of various grid representations in capturing the nuances of the forest. This sensitivity analysis reveals that larger voxel sizes (e.g., 2 meters) result in lower errors due to reduced variability, while smaller voxel sizes (e.g., 0.25 or 0.5 meter) exhibit higher errors, particularly within the canopy, where variability is greatest. For bark and leaf targets, error values at smaller voxel size datasets (0.25 and 0.5 meter) were significantly higher than those in larger voxel size datasets (2 meters), highlighting the difficulty in accurately estimating within-canopy voxel content at fine resolutions. This suggests that the choice of voxel size is application-dependent. Our work fills the gap in deep imbalance learning models for multi-target regression and simulated datasets for 3D LiDAR point clouds of forests.
OpenScout v1.1 mobile robot: a case study on open hardware continuation
Aug 01, 2025OpenScout is an Open Source Hardware (OSH) mobile robot for research and industry. It is extended to v1.1 which includes simplified, cheaper and more powerful onboard compute hardware; a simulated ROS2 interface; and a Gazebo simulation. Changes, their rationale, project methodology, and results are reported as an OSH case study.
Holistic Continual Learning under Concept Drift with Adaptive Memory Realignment
Jul 03, 2025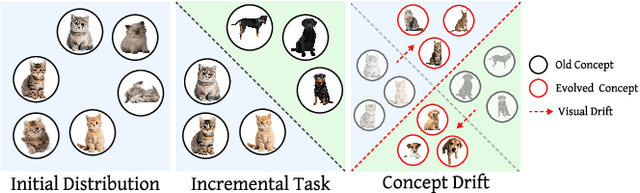
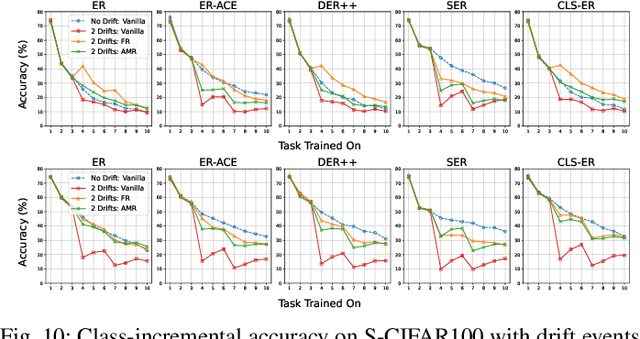
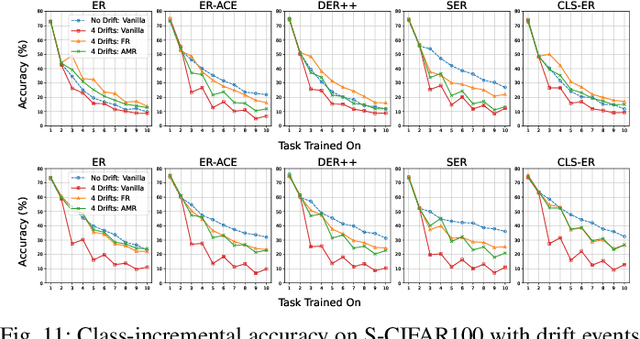
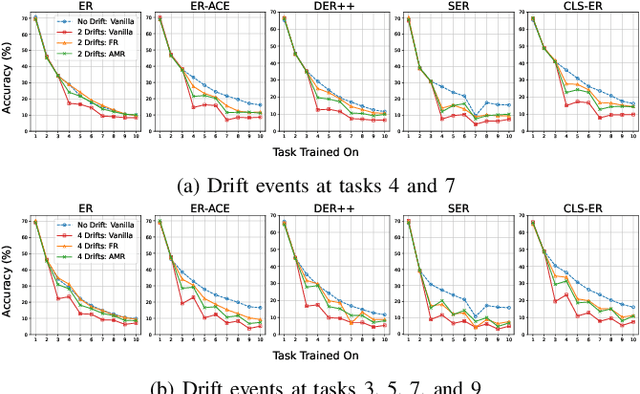
Traditional continual learning methods prioritize knowledge retention and focus primarily on mitigating catastrophic forgetting, implicitly assuming that the data distribution of previously learned tasks remains static. This overlooks the dynamic nature of real-world data streams, where concept drift permanently alters previously seen data and demands both stability and rapid adaptation. We introduce a holistic framework for continual learning under concept drift that simulates realistic scenarios by evolving task distributions. As a baseline, we consider Full Relearning (FR), in which the model is retrained from scratch on newly labeled samples from the drifted distribution. While effective, this approach incurs substantial annotation and computational overhead. To address these limitations, we propose Adaptive Memory Realignment (AMR), a lightweight alternative that equips rehearsal-based learners with a drift-aware adaptation mechanism. AMR selectively removes outdated samples of drifted classes from the replay buffer and repopulates it with a small number of up-to-date instances, effectively realigning memory with the new distribution. This targeted resampling matches the performance of FR while reducing the need for labeled data and computation by orders of magnitude. To enable reproducible evaluation, we introduce four concept-drift variants of standard vision benchmarks: Fashion-MNIST-CD, CIFAR10-CD, CIFAR100-CD, and Tiny-ImageNet-CD, where previously seen classes reappear with shifted representations. Comprehensive experiments on these datasets using several rehearsal-based baselines show that AMR consistently counters concept drift, maintaining high accuracy with minimal overhead. These results position AMR as a scalable solution that reconciles stability and plasticity in non-stationary continual learning environments.
What is the role of memorization in Continual Learning?
May 23, 2025Memorization impacts the performance of deep learning algorithms. Prior works have studied memorization primarily in the context of generalization and privacy. This work studies the memorization effect on incremental learning scenarios. Forgetting prevention and memorization seem similar. However, one should discuss their differences. We designed extensive experiments to evaluate the impact of memorization on continual learning. We clarified that learning examples with high memorization scores are forgotten faster than regular samples. Our findings also indicated that memorization is necessary to achieve the highest performance. However, at low memory regimes, forgetting regular samples is more important. We showed that the importance of a high-memorization score sample rises with an increase in the buffer size. We introduced a memorization proxy and employed it in the buffer policy problem to showcase how memorization could be used during incremental training. We demonstrated that including samples with a higher proxy memorization score is beneficial when the buffer size is large.
Balanced Gradient Sample Retrieval for Enhanced Knowledge Retention in Proxy-based Continual Learning
Dec 19, 2024



Continual learning in deep neural networks often suffers from catastrophic forgetting, where representations for previous tasks are overwritten during subsequent training. We propose a novel sample retrieval strategy from the memory buffer that leverages both gradient-conflicting and gradient-aligned samples to effectively retain knowledge about past tasks within a supervised contrastive learning framework. Gradient-conflicting samples are selected for their potential to reduce interference by re-aligning gradients, thereby preserving past task knowledge. Meanwhile, gradient-aligned samples are incorporated to reinforce stable, shared representations across tasks. By balancing gradient correction from conflicting samples with alignment reinforcement from aligned ones, our approach increases the diversity among retrieved instances and achieves superior alignment in parameter space, significantly enhancing knowledge retention and mitigating proxy drift. Empirical results demonstrate that using both sample types outperforms methods relying solely on one sample type or random retrieval. Experiments on popular continual learning benchmarks in computer vision validate our method's state-of-the-art performance in mitigating forgetting while maintaining competitive accuracy on new tasks.
Continual Learning with Weight Interpolation
Apr 09, 2024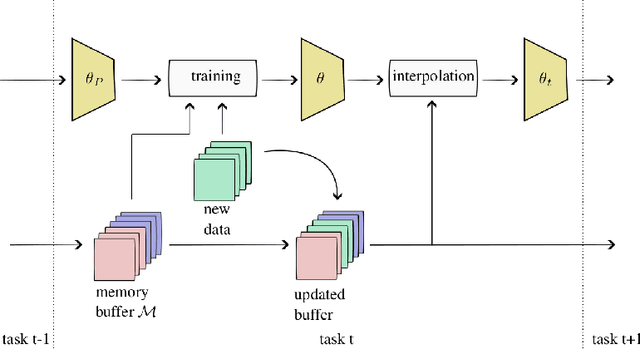
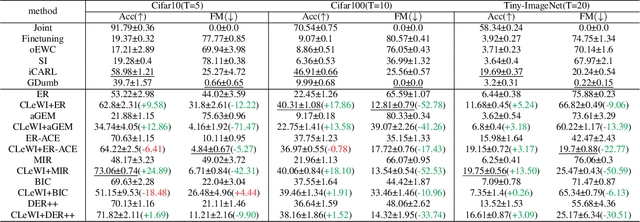
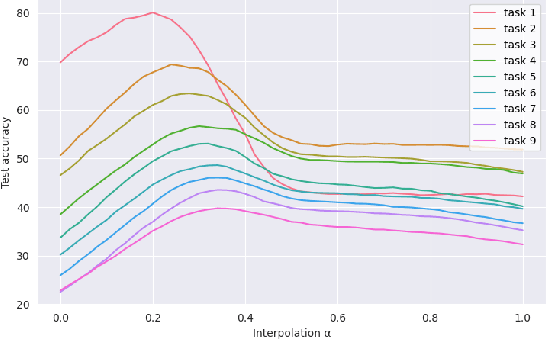
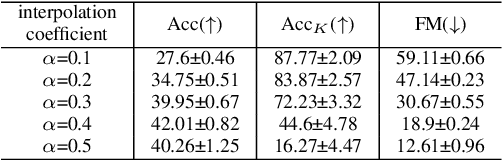
Continual learning poses a fundamental challenge for modern machine learning systems, requiring models to adapt to new tasks while retaining knowledge from previous ones. Addressing this challenge necessitates the development of efficient algorithms capable of learning from data streams and accumulating knowledge over time. This paper proposes a novel approach to continual learning utilizing the weight consolidation method. Our method, a simple yet powerful technique, enhances robustness against catastrophic forgetting by interpolating between old and new model weights after each novel task, effectively merging two models to facilitate exploration of local minima emerging after arrival of new concepts. Moreover, we demonstrate that our approach can complement existing rehearsal-based replay approaches, improving their accuracy and further mitigating the forgetting phenomenon. Additionally, our method provides an intuitive mechanism for controlling the stability-plasticity trade-off. Experimental results showcase the significant performance enhancement to state-of-the-art experience replay algorithms the proposed weight consolidation approach offers. Our algorithm can be downloaded from https://github.com/jedrzejkozal/weight-interpolation-cl.
Class-Incremental Mixture of Gaussians for Deep Continual Learning
Jul 09, 2023Continual learning models for stationary data focus on learning and retaining concepts coming to them in a sequential manner. In the most generic class-incremental environment, we have to be ready to deal with classes coming one by one, without any higher-level grouping. This requirement invalidates many previously proposed methods and forces researchers to look for more flexible alternative approaches. In this work, we follow the idea of centroid-driven methods and propose end-to-end incorporation of the mixture of Gaussians model into the continual learning framework. By employing the gradient-based approach and designing losses capable of learning discriminative features while avoiding degenerate solutions, we successfully combine the mixture model with a deep feature extractor allowing for joint optimization and adjustments in the latent space. Additionally, we show that our model can effectively learn in memory-free scenarios with fixed extractors. In the conducted experiments, we empirically demonstrate the effectiveness of the proposed solutions and exhibit the competitiveness of our model when compared with state-of-the-art continual learning baselines evaluated in the context of image classification problems.