 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is the role of memorization in Continual Learning?
May 23, 2025Memorization impacts the performance of deep learning algorithms. Prior works have studied memorization primarily in the context of generalization and privacy. This work studies the memorization effect on incremental learning scenarios. Forgetting prevention and memorization seem similar. However, one should discuss their differences. We designed extensive experiments to evaluate the impact of memorization on continual learning. We clarified that learning examples with high memorization scores are forgotten faster than regular samples. Our findings also indicated that memorization is necessary to achieve the highest performance. However, at low memory regimes, forgetting regular samples is more important. We showed that the importance of a high-memorization score sample rises with an increase in the buffer size. We introduced a memorization proxy and employed it in the buffer policy problem to showcase how memorization could be used during incremental training. We demonstrated that including samples with a higher proxy memorization score is beneficial when the buffer size is large.
Continual Learning with Weight Interpolation
Apr 09, 2024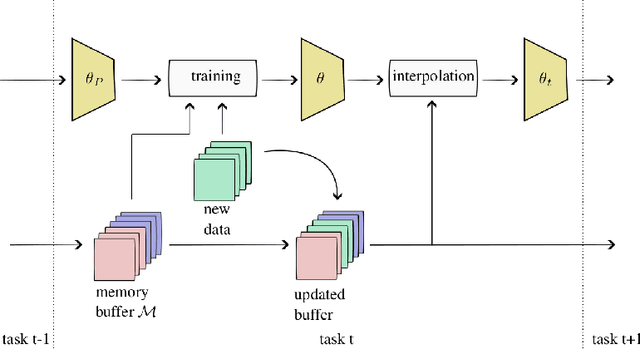
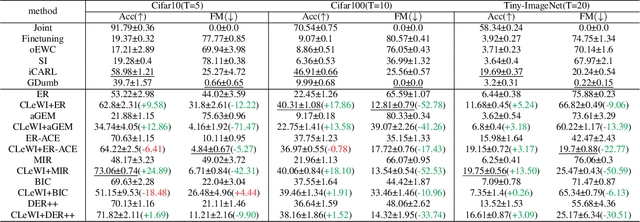
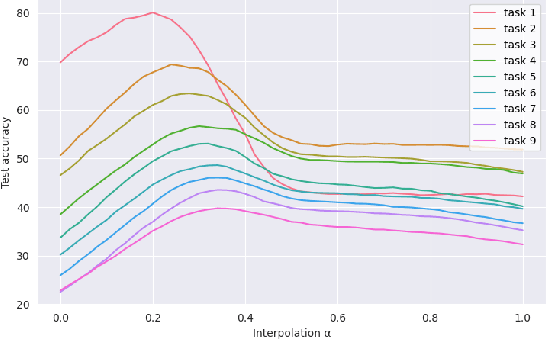
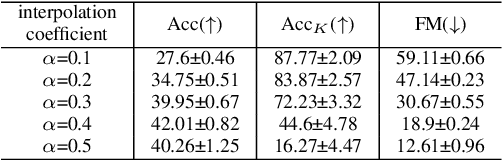
Continual learning poses a fundamental challenge for modern machine learning systems, requiring models to adapt to new tasks while retaining knowledge from previous ones. Addressing this challenge necessitates the development of efficient algorithms capable of learning from data streams and accumulating knowledge over time. This paper proposes a novel approach to continual learning utilizing the weight consolidation method. Our method, a simple yet powerful technique, enhances robustness against catastrophic forgetting by interpolating between old and new model weights after each novel task, effectively merging two models to facilitate exploration of local minima emerging after arrival of new concepts. Moreover, we demonstrate that our approach can complement existing rehearsal-based replay approaches, improving their accuracy and further mitigating the forgetting phenomenon. Additionally, our method provides an intuitive mechanism for controlling the stability-plasticity trade-off. Experimental results showcase the significant performance enhancement to state-of-the-art experience replay algorithms the proposed weight consolidation approach offers. Our algorithm can be downloaded from https://github.com/jedrzejkozal/weight-interpolation-cl.
A Natural Gas Consumption Forecasting System for Continual Learning Scenarios based on Hoeffding Trees with Change Point Detection Mechanism
Sep 07, 2023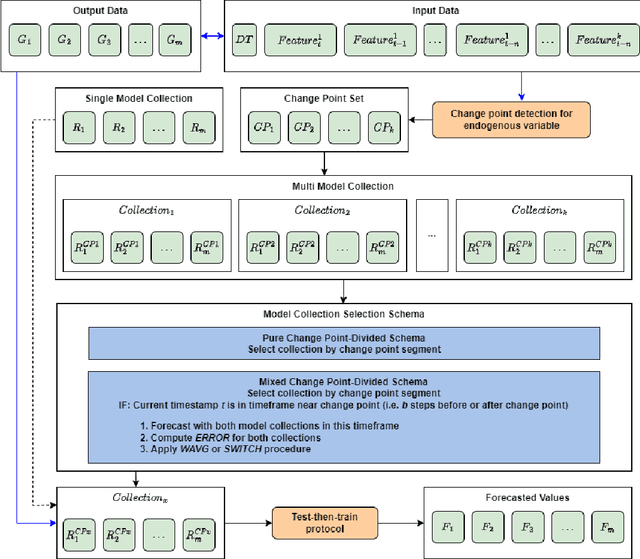
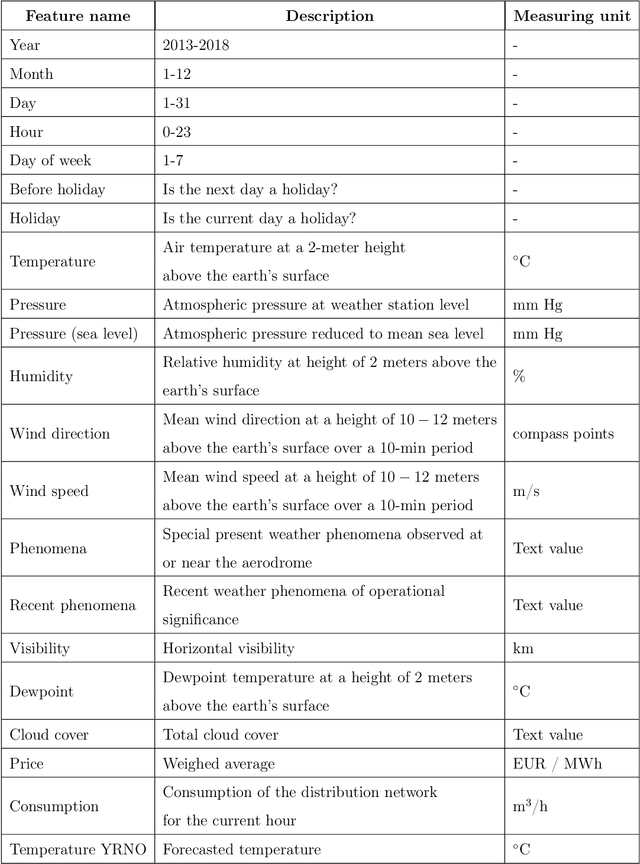

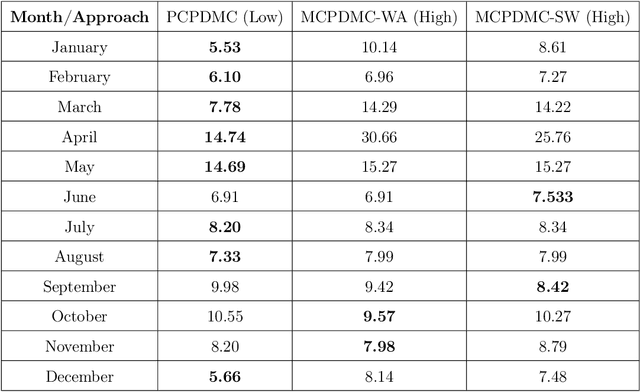
Forecasting natural gas consumption, considering seasonality and trends, is crucial in planning its supply and consumption and optimizing the cost of obtaining it, mainly by industrial entities. However, in times of threats to its supply, it is also a critical element that guarantees the supply of this raw material to meet individual consumers' needs, ensuring society's energy security. This article introduces a novel multistep ahead forecasting of natural gas consumption with change point detection integration for model collection selection with continual learning capabilities using data stream processing. The performance of the forecasting models based on the proposed approach is evaluated in a complex real-world use case of natural gas consumption forecasting. We employed Hoeffding tree predictors as forecasting models and the Pruned Exact Linear Time (PELT) algorithm for the change point detection procedure. The change point detection integration enables selecting a different model collection for successive time frames. Thus, three model collection selection procedures (with and without an error feedback loop) are defined and evaluated for forecasting scenarios with various densities of detected change points. These models were compared with change point agnostic baseline approaches. Our experiments show that fewer change points result in a lower forecasting error regardless of the model collection selection procedure employed. Also, simpler model collection selection procedures omitting forecasting error feedback leads to more robust forecasting models suitable for continual learning tasks.
Combining Self-labeling with Selective Sampling
Jan 11, 2023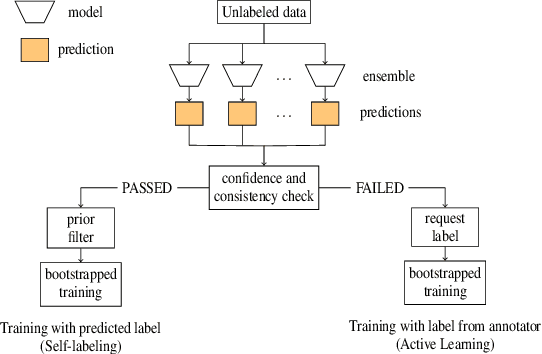



Since data is the fuel that drives machine learning models, and access to labeled data is generally expensive, semi-supervised methods are constantly popular. They enable the acquisition of large datasets without the need for too many expert labels. This work combines self-labeling techniques with active learning in a selective sampling scenario. We propose a new method that builds an ensemble classifier. Based on an evaluation of the inconsistency of the decisions of the individual base classifiers for a given observation, a decision is made on whether to request a new label or use the self-labeling. In preliminary studies, we show that naive application of self-labeling can harm performance by introducing bias towards selected classes and consequently lead to skewed class distribution. Hence, we also propose mechanisms to reduce this phenomenon. Experimental evaluation shows that the proposed method matches current selective sampling methods or achieves better results.
Increasing Depth of Neural Networks for Life-long Learning
Feb 22, 2022



Increasing neural network depth is a well-known method for improving neural network performance. Modern deep architectures contain multiple mechanisms that allow hundreds or even thousands of layers to train. This work is trying to answer if extending neural network depth may be beneficial in a life-long learning setting. In particular, we propose a novel method based on adding new layers on top of existing ones to enable the forward transfer of knowledge and adapting previously learned representations for new tasks. We utilize a method of determining the most similar tasks for selecting the best location in our network to add new nodes with trainable parameters. This approach allows for creating a tree-like model, where each node is a set of neural network parameters dedicated to a specific task. The proposed method is inspired by Progressive Neural Network (PNN) concept, therefore it is rehearsal-free and benefits from dynamic change of network structure. However, it requires fewer parameters per task than PNN. Experiments on Permuted MNIST and SplitCIFAR show that the proposed algorithm is on par with other continual learning methods. We also perform ablation studies to clarify the contributions of each system part.
Employing chunk size adaptation to overcome concept drift
Oct 25, 2021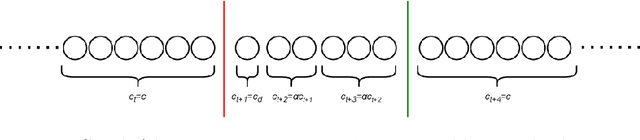

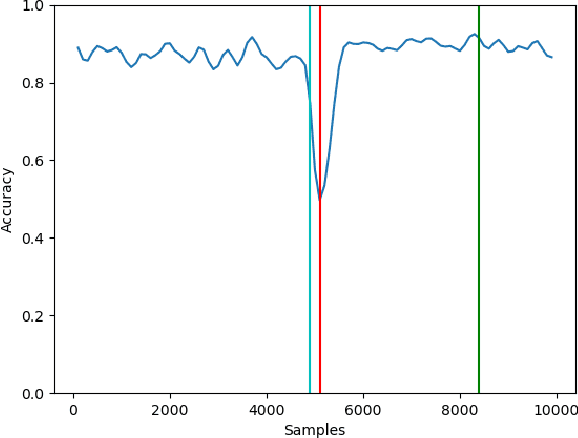

Modern analytical systems must be ready to process streaming data and correctly respond to data distribution changes. The phenomenon of changes in data distributions is called concept drift, and it may harm the quality of the used models. Additionally, the possibility of concept drift appearance causes that the used algorithms must be ready for the continuous adaptation of the model to the changing data distributions. This work focuses on non-stationary data stream classification, where a classifier ensemble is used. To keep the ensemble model up to date, the new base classifiers are trained on the incoming data blocks and added to the ensemble while, at the same time, outdated models are removed from the ensemble. One of the problems with this type of model is the fast reaction to changes in data distributions. We propose a new Chunk Adaptive Restoration framework that can be adapted to any block-based data stream classification algorithm. The proposed algorithm adjusts the data chunk size in the case of concept drift detection to minimize the impact of the change on the predictive performance of the used model. The conducted experimental research, backed up with the statistical tests, has proven that Chunk Adaptive Restoration significantly reduces the model's restoration time.