 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is the role of memorization in Continual Learning?
May 23, 2025Memorization impacts the performance of deep learning algorithms. Prior works have studied memorization primarily in the context of generalization and privacy. This work studies the memorization effect on incremental learning scenarios. Forgetting prevention and memorization seem similar. However, one should discuss their differences. We designed extensive experiments to evaluate the impact of memorization on continual learning. We clarified that learning examples with high memorization scores are forgotten faster than regular samples. Our findings also indicated that memorization is necessary to achieve the highest performance. However, at low memory regimes, forgetting regular samples is more important. We showed that the importance of a high-memorization score sample rises with an increase in the buffer size. We introduced a memorization proxy and employed it in the buffer policy problem to showcase how memorization could be used during incremental training. We demonstrated that including samples with a higher proxy memorization score is beneficial when the buffer size is large.
Balanced Gradient Sample Retrieval for Enhanced Knowledge Retention in Proxy-based Continual Learning
Dec 19, 2024



Continual learning in deep neural networks often suffers from catastrophic forgetting, where representations for previous tasks are overwritten during subsequent training. We propose a novel sample retrieval strategy from the memory buffer that leverages both gradient-conflicting and gradient-aligned samples to effectively retain knowledge about past tasks within a supervised contrastive learning framework. Gradient-conflicting samples are selected for their potential to reduce interference by re-aligning gradients, thereby preserving past task knowledge. Meanwhile, gradient-aligned samples are incorporated to reinforce stable, shared representations across tasks. By balancing gradient correction from conflicting samples with alignment reinforcement from aligned ones, our approach increases the diversity among retrieved instances and achieves superior alignment in parameter space, significantly enhancing knowledge retention and mitigating proxy drift. Empirical results demonstrate that using both sample types outperforms methods relying solely on one sample type or random retrieval. Experiments on popular continual learning benchmarks in computer vision validate our method's state-of-the-art performance in mitigating forgetting while maintaining competitive accuracy on new tasks.
Continual Learning with Weight Interpolation
Apr 09, 2024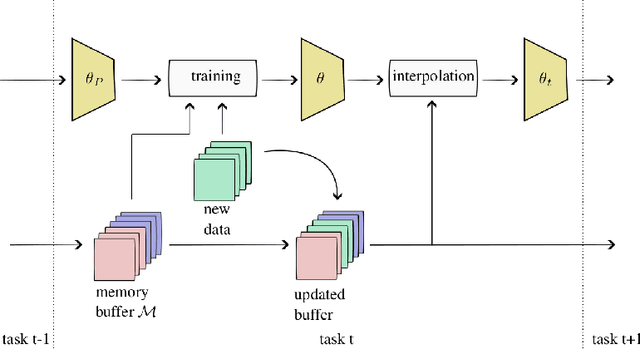
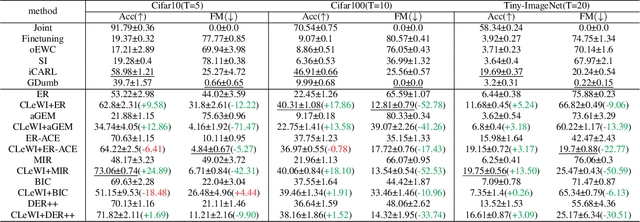
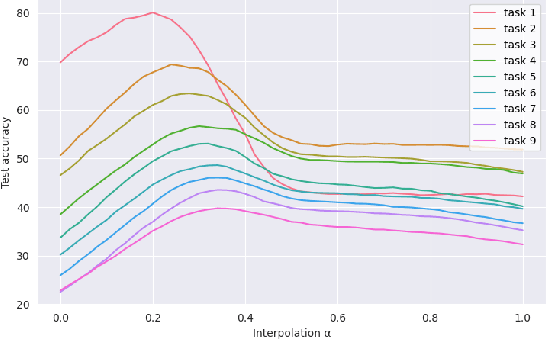
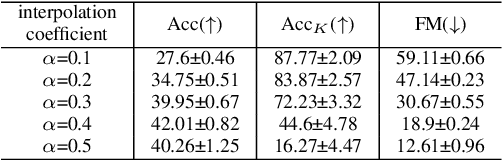
Continual learning poses a fundamental challenge for modern machine learning systems, requiring models to adapt to new tasks while retaining knowledge from previous ones. Addressing this challenge necessitates the development of efficient algorithms capable of learning from data streams and accumulating knowledge over time. This paper proposes a novel approach to continual learning utilizing the weight consolidation method. Our method, a simple yet powerful technique, enhances robustness against catastrophic forgetting by interpolating between old and new model weights after each novel task, effectively merging two models to facilitate exploration of local minima emerging after arrival of new concepts. Moreover, we demonstrate that our approach can complement existing rehearsal-based replay approaches, improving their accuracy and further mitigating the forgetting phenomenon. Additionally, our method provides an intuitive mechanism for controlling the stability-plasticity trade-off. Experimental results showcase the significant performance enhancement to state-of-the-art experience replay algorithms the proposed weight consolidation approach offers. Our algorithm can be downloaded from https://github.com/jedrzejkozal/weight-interpolation-cl.