 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Self-labeling with Selective Sampling
Paper and Code
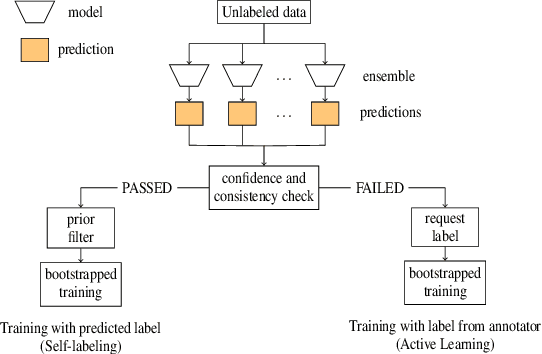



Since data is the fuel that drives machine learning models, and access to labeled data is generally expensive, semi-supervised methods are constantly popular. They enable the acquisition of large datasets without the need for too many expert labels. This work combines self-labeling techniques with active learning in a selective sampling scenario. We propose a new method that builds an ensemble classifier. Based on an evaluation of the inconsistency of the decisions of the individual base classifiers for a given observation, a decision is made on whether to request a new label or use the self-labeling. In preliminary studies, we show that naive application of self-labeling can harm performance by introducing bias towards selected classes and consequently lead to skewed class distribution. Hence, we also propose mechanisms to reduce this phenomenon. Experimental evaluation shows that the proposed method matches current selective sampling methods or achieves better results.