 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline hierarchical partitioning of the output space in extreme multi-label data stream
Jul 28, 2025



Mining data streams with multi-label outputs poses significant challenges due to evolving distributions, high-dimensional label spaces, sparse label occurrences, and complex label dependencies. Moreover, concept drift affects not only input distributions but also label correlations and imbalance ratios over time, complicating model adaptation. To address these challenges, structured learners are categorized into local and global methods. Local methods break down the task into simpler components, while global methods adapt the algorithm to the full output space, potentially yielding better predictions by exploiting label correlations. This work introduces iHOMER (Incremental Hierarchy Of Multi-label Classifiers), an online multi-label learning framework that incrementally partitions the label space into disjoint, correlated clusters without relying on predefined hierarchies. iHOMER leverages online divisive-agglomerative clustering based on \textit{Jaccard} similarity and a global tree-based learner driven by a multivariate \textit{Bernoulli} process to guide instance partitioning. To address non-stationarity, it integrates drift detection mechanisms at both global and local levels, enabling dynamic restructuring of label partitions and subtrees. Experiments across 23 real-world datasets show iHOMER outperforms 5 state-of-the-art global baselines, such as MLHAT, MLHT of Pruned Sets and iSOUPT, by 23\%, and 12 local baselines, such as binary relevance transformations of kNN, EFDT, ARF, and ADWIN bagging/boosting ensembles, by 32\%, establishing its robustness for online multi-label classification.
Hoeffding adaptive trees for multi-label classification on data streams
Oct 26, 2024Data stream learning is a very relevant paradigm because of the increasing real-world scenarios generating data at high velocities and in unbounded sequences. Stream learning aims at developing models that can process instances as they arrive, so models constantly adapt to new concepts and the temporal evolution in the stream. In multi-label data stream environments where instances have the peculiarity of belonging simultaneously to more than one class, the problem becomes even more complex and poses unique challenges such as different concept drifts impacting different labels at simultaneous or distinct times, higher class imbalance, or new labels emerging in the stream. This paper proposes a novel approach to multi-label data stream classification called Multi-Label Hoeffding Adaptive Tree (MLHAT). MLHAT leverages the Hoeffding adaptive tree to address these challenges by considering possible relations and label co-occurrences in the partitioning process of the decision tree, dynamically adapting the learner in each leaf node of the tree, and implementing a concept drift detector that can quickly detect and replace tree branches that are no longer performing well. The proposed approach is compared with other 18 online multi-label classifiers on 41 datasets. The results, validated with statistical analysis, show that MLHAT outperforms other state-of-the-art approaches in 12 well-known multi-label metrics.
A Survey on Group Fairness in Federated Learning: Challenges, Taxonomy of Solutions and Directions for Future Research
Oct 04, 2024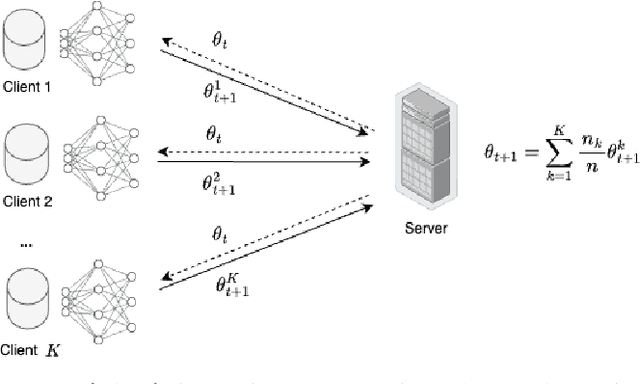


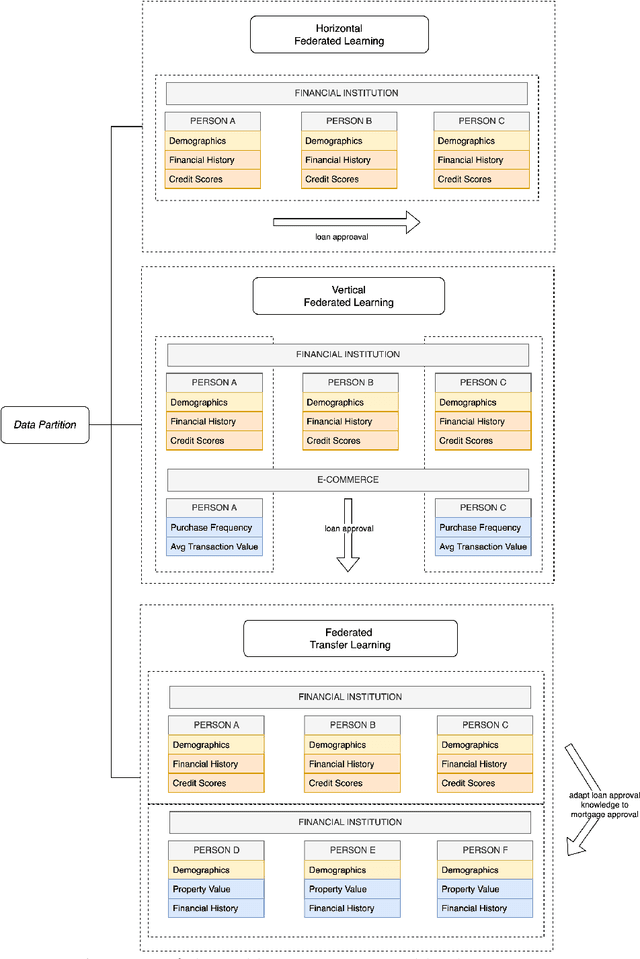
Group fairness in machine learning is a critical area of research focused on achieving equitable outcomes across different groups defined by sensitive attributes such as race or gender. Federated learning, a decentralized approach to training machine learning models across multiple devices or organizations without sharing raw data, amplifies the need for fairness due to the heterogeneous data distributions across clients, which can exacerbate biases. The intersection of federated learning and group fairness has attracted significant interest, with 47 research works specifically dedicated to addressing this issue. However, no dedicated survey has focused comprehensively on group fairness in federated learning. In this work, we present an in-depth survey on this topic, addressing the critical challenges and reviewing related works in the field. We create a novel taxonomy of these approaches based on key criteria such as data partitioning, location, and applied strategies. Additionally, we explore broader concerns related to this problem and investigate how different approaches handle the complexities of various sensitive groups and their intersections. Finally, we review the datasets and applications commonly used in current research. We conclude by highlighting key areas for future research, emphasizing the need for more methods to address the complexities of achieving group fairness in federated systems.
A comprehensive analysis of concept drift locality in data streams
Nov 10, 2023Adapting to drifting data streams is a significant challenge in online learning. Concept drift must be detected for effective model adaptation to evolving data properties. Concept drift can impact the data distribution entirely or partially, which makes it difficult for drift detectors to accurately identify the concept drift. Despite the numerous concept drift detectors in the literature, standardized procedures and benchmarks for comprehensive evaluation considering the locality of the drift are lacking. We present a novel categorization of concept drift based on its locality and scale. A systematic approach leads to a set of 2,760 benchmark problems, reflecting various difficulty levels following our proposed categorization. We conduct a comparative assessment of 9 state-of-the-art drift detectors across diverse difficulties, highlighting their strengths and weaknesses for future research. We examine how drift locality influences the classifier performance and propose strategies for different drift categories to minimize the recovery time. Lastly, we provide lessons learned and recommendations for future concept drift research. Our benchmark data streams and experiments are publicly available at https://github.com/gabrieljaguiar/locality-concept-drift.
A survey on learning from imbalanced data streams: taxonomy, challenges, empirical study, and reproducible experimental framework
Apr 07, 2022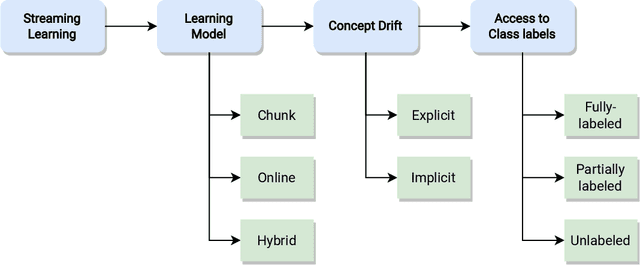
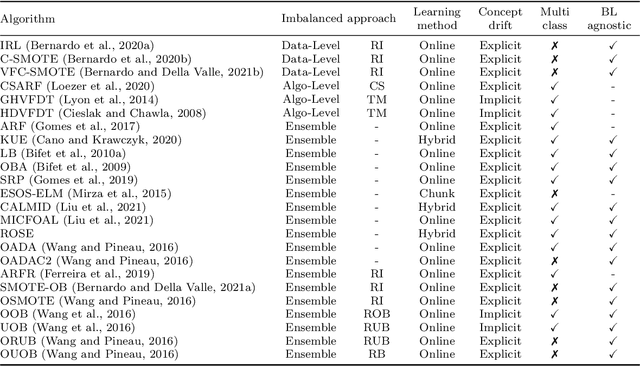
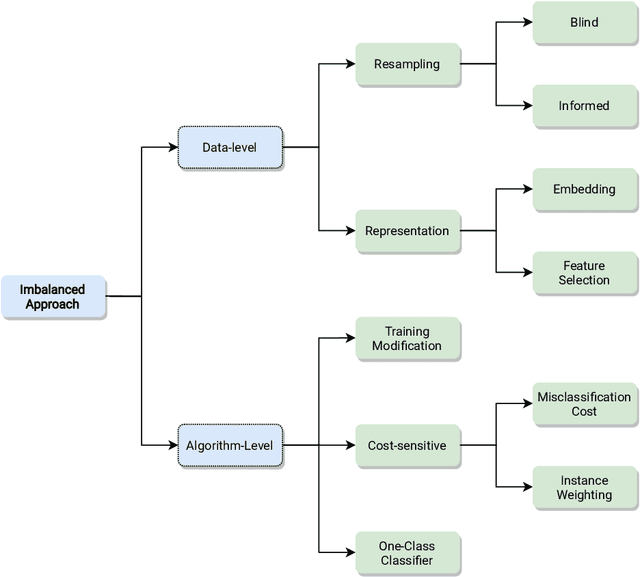
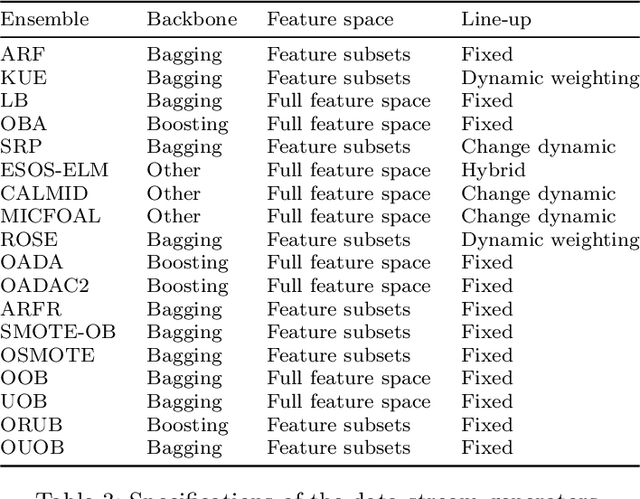
Class imbalance poses new challenges when it comes to classifying data streams. Many algorithms recently proposed in the literature tackle this problem using a variety of data-level, algorithm-level, and ensemble approaches. However, there is a lack of standardized and agreed-upon procedures on how to evaluate these algorithms. This work presents a taxonomy of algorithms for imbalanced data streams and proposes a standardized, exhaustive, and informative experimental testbed to evaluate algorithms in a collection of diverse and challenging imbalanced data stream scenarios. The experimental study evaluates 24 state-of-the-art data streams algorithms on 515 imbalanced data streams that combine static and dynamic class imbalance ratios, instance-level difficulties, concept drift, real-world and semi-synthetic datasets in binary and multi-class scenarios. This leads to the largest experimental study conducted so far in the data stream mining domain. We discuss the advantages and disadvantages of state-of-the-art classifiers in each of these scenarios and we provide general recommendations to end-users for selecting the best algorithms for imbalanced data streams. Additionally, we formulate open challenges and future directions for this domain. Our experimental testbed is fully reproducible and easy to extend with new methods. This way we propose the first standardized approach to conducting experiments in imbalanced data streams that can be used by other researchers to create trustworthy and fair evaluation of newly proposed methods. Our experimental framework can be downloaded from https://github.com/canoalberto/imbalanced-streams.