 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIHT: A Hoeffding Tree for Time Series Classification using Multiple Instance Learning
Mar 23, 2026Due to the prevalence of temporal data and its inherent dependencies in many real-world problems, time series classification is of paramount importance in various domains. However, existing models often struggle with series of variable length or high dimensionality. This paper introduces the MIHT (Multi-instance Hoeffding Tree) algorithm, an efficient model that uses multi-instance learning to classify multivariate and variable-length time series while providing interpretable results. The algorithm uses a novel representation of time series as "bags of subseries," together with an optimization process based on incremental decision trees that distinguish relevant parts of the series from noise. This methodology extracts the underlying concept of series with multiple variables and variable lengths. The generated decision tree is a compact, white-box representation of the series' concept, providing interpretability insights into the most relevant variables and segments of the series. Experimental results demonstrate MIHT's superiority, as it outperforms 11 state-of-the-art time series classification models on 28 public datasets, including high-dimensional ones. MIHT offers enhanced accuracy and interpretability, making it a promising solution for handling complex, dynamic time series data.
Hoeffding adaptive trees for multi-label classification on data streams
Oct 26, 2024Data stream learning is a very relevant paradigm because of the increasing real-world scenarios generating data at high velocities and in unbounded sequences. Stream learning aims at developing models that can process instances as they arrive, so models constantly adapt to new concepts and the temporal evolution in the stream. In multi-label data stream environments where instances have the peculiarity of belonging simultaneously to more than one class, the problem becomes even more complex and poses unique challenges such as different concept drifts impacting different labels at simultaneous or distinct times, higher class imbalance, or new labels emerging in the stream. This paper proposes a novel approach to multi-label data stream classification called Multi-Label Hoeffding Adaptive Tree (MLHAT). MLHAT leverages the Hoeffding adaptive tree to address these challenges by considering possible relations and label co-occurrences in the partitioning process of the decision tree, dynamically adapting the learner in each leaf node of the tree, and implementing a concept drift detector that can quickly detect and replace tree branches that are no longer performing well. The proposed approach is compared with other 18 online multi-label classifiers on 41 datasets. The results, validated with statistical analysis, show that MLHAT outperforms other state-of-the-art approaches in 12 well-known multi-label metrics.
JCLEC-MO: a Java suite for solving many-objective optimization engineering problems
Feb 28, 2024



Although metaheuristics have been widely recognized as efficient techniques to solve real-world optimization problems, implementing them from scratch remains difficult for domain-specific experts without programming skills. In this scenario, metaheuristic optimization frameworks are a practical alternative as they provide a variety of algorithms composed of customized elements, as well as experimental support. Recently, many engineering problems require to optimize multiple or even many objectives, increasing the interest in appropriate metaheuristic algorithms and frameworks that might integrate new specific requirements while maintaining the generality and reusability principles they were conceived for. Based on this idea, this paper introduces JCLEC-MO, a Java framework for both multi- and many-objective optimization that enables engineers to apply, or adapt, a great number of multi-objective algorithms with little coding effort. A case study is developed and explained to show how JCLEC-MO can be used to address many-objective engineering problems, often requiring the inclusion of domain-specific elements, and to analyze experimental outcomes by means of conveniently connected R utilities.
* 41 pages, 5 figures, journal paper
Interactive Multi-Objective Evolutionary Optimization of Software Architectures
Jan 08, 2024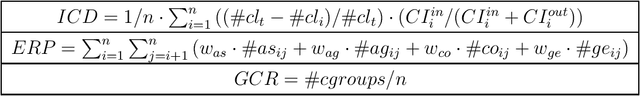
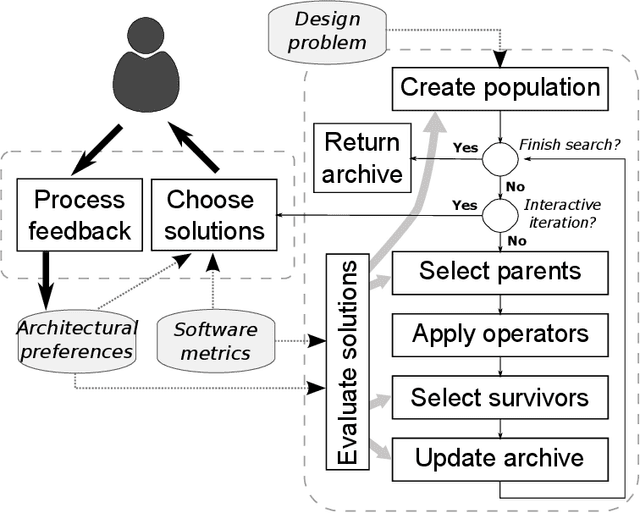
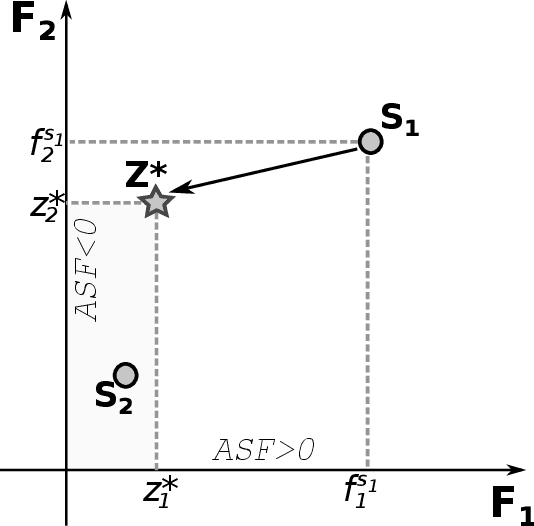
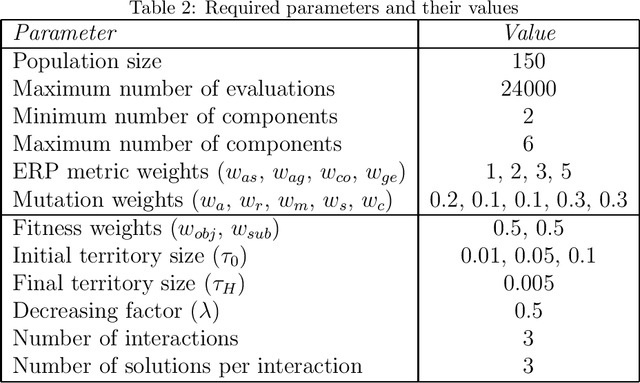
While working on a software specification, designers usually need to evaluate different architectural alternatives to be sure that quality criteria are met. Even when these quality aspects could be expressed in terms of multiple software metrics, other qualitative factors cannot be numerically measured, but they are extracted from the engineer's know-how and prior experiences. In fact, detecting not only strong but also weak points in the different solutions seems to fit better with the way humans make their decisions. Putting the human in the loop brings new challenges to the search-based software engineering field, especially for those human-centered activities within the early analysis phase. This paper explores how the interactive evolutionary computation can serve as a basis for integrating the human's judgment into the search process. An interactive approach is proposed to discover software architectures, in which both quantitative and qualitative criteria are applied to guide a multi-objective evolutionary algorithm. The obtained feedback is incorporated into the fitness function using architectural preferences allowing the algorithm to discern between promising and poor solutions. Experimentation with real users has revealed that the proposed interaction mechanism can effectively guide the search towards those regions of the search space that are of real interest to the expert.
* 41 pages, 5 figures, journal "Information Sciences"