 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explainable Test Case Prioritisation with Learning-to-Rank Models
May 22, 2024Test case prioritisation (TCP) is a critical task in regression testing to ensure quality as software evolves. Machine learning has become a common way to achieve it. In particular, learning-to-rank (LTR) algorithms provide an effective method of ordering and prioritising test cases. However, their use poses a challenge in terms of explainability, both globally at the model level and locally for particular results. Here, we present and discuss scenarios that require different explanations and how the particularities of TCP (multiple builds over time, test case and test suite variations, etc.) could influence them. We include a preliminary experiment to analyse the similarity of explanations, showing that they do not only vary depending on test case-specific predictions, but also on the relative ranks.
* 3rd International Workshop on Artificial Intelligence in Software Testing (AIST) - International Conference on Software Testing and Validation (ICST)
JCLEC-MO: a Java suite for solving many-objective optimization engineering problems
Feb 28, 2024Although metaheuristics have been widely recognized as efficient techniques to solve real-world optimization problems, implementing them from scratch remains difficult for domain-specific experts without programming skills. In this scenario, metaheuristic optimization frameworks are a practical alternative as they provide a variety of algorithms composed of customized elements, as well as experimental support. Recently, many engineering problems require to optimize multiple or even many objectives, increasing the interest in appropriate metaheuristic algorithms and frameworks that might integrate new specific requirements while maintaining the generality and reusability principles they were conceived for. Based on this idea, this paper introduces JCLEC-MO, a Java framework for both multi- and many-objective optimization that enables engineers to apply, or adapt, a great number of multi-objective algorithms with little coding effort. A case study is developed and explained to show how JCLEC-MO can be used to address many-objective engineering problems, often requiring the inclusion of domain-specific elements, and to analyze experimental outcomes by means of conveniently connected R utilities.
* 41 pages, 5 figures, journal paper
Evolving machine learning workflows through interactive AutoML
Feb 28, 2024Automatic workflow composition (AWC) is a relevant problem in automated machine learning (AutoML) that allows finding suitable sequences of preprocessing and prediction models together with their optimal hyperparameters. This problem can be solved using evolutionary algorithms and, in particular, grammar-guided genetic programming (G3P). Current G3P approaches to AWC define a fixed grammar that formally specifies how workflow elements can be combined and which algorithms can be included. In this paper we present \ourmethod, an interactive G3P algorithm that allows users to dynamically modify the grammar to prune the search space and focus on their regions of interest. Our proposal is the first to combine the advantages of a G3P method with ideas from interactive optimisation and human-guided machine learning, an area little explored in the context of AutoML. To evaluate our approach, we present an experimental study in which 20 participants interact with \ourmethod to evolve workflows according to their preferences. Our results confirm that the collaboration between \ourmethod and humans allows us to find high-performance workflows in terms of accuracy that require less tuning time than those found without human intervention.
Grammar-based evolutionary approach for automated workflow composition with domain-specific operators and ensemble diversity
Feb 03, 2024The process of extracting valuable and novel insights from raw data involves a series of complex steps. In the realm of Automated Machine Learning (AutoML), a significant research focus is on automating aspects of this process, specifically tasks like selecting algorithms and optimising their hyper-parameters. A particularly challenging task in AutoML is automatic workflow composition (AWC). AWC aims to identify the most effective sequence of data preprocessing and ML algorithms, coupled with their best hyper-parameters, for a specific dataset. However, existing AWC methods are limited in how many and in what ways they can combine algorithms within a workflow. Addressing this gap, this paper introduces EvoFlow, a grammar-based evolutionary approach for AWC. EvoFlow enhances the flexibility in designing workflow structures, empowering practitioners to select algorithms that best fit their specific requirements. EvoFlow stands out by integrating two innovative features. First, it employs a suite of genetic operators, designed specifically for AWC, to optimise both the structure of workflows and their hyper-parameters. Second, it implements a novel updating mechanism that enriches the variety of predictions made by different workflows. Promoting this diversity helps prevent the algorithm from overfitting. With this aim, EvoFlow builds an ensemble whose workflows differ in their misclassified instances. To evaluate EvoFlow's effectiveness, we carried out empirical validation using a set of classification benchmarks. We begin with an ablation study to demonstrate the enhanced performance attributable to EvoFlow's unique components. Then, we compare EvoFlow with other AWC approaches, encompassing both evolutionary and non-evolutionary techniques. Our findings show that EvoFlow's specialised genetic operators and updating mechanism substantially outperform current leading methods[..]
* 32 pages, 7 figures, 6 tables, journal paper
GEML: A Grammar-based Evolutionary Machine Learning Approach for Design-Pattern Detection
Jan 13, 2024Design patterns (DPs) are recognised as a good practice in software development. However, the lack of appropriate documentation often hampers traceability, and their benefits are blurred among thousands of lines of code. Automatic methods for DP detection have become relevant but are usually based on the rigid analysis of either software metrics or specific properties of the source code. We propose GEML, a novel detection approach based on evolutionary machine learning using software properties of diverse nature. Firstly, GEML makes use of an evolutionary algorithm to extract those characteristics that better describe the DP, formulated in terms of human-readable rules, whose syntax is conformant with a context-free grammar. Secondly, a rule-based classifier is built to predict whether new code contains a hidden DP implementation. GEML has been validated over five DPs taken from a public repository recurrently adopted by machine learning studies. Then, we increase this number up to 15 diverse DPs, showing its effectiveness and robustness in terms of detection capability. An initial parameter study served to tune a parameter setup whose performance guarantees the general applicability of this approach without the need to adjust complex parameters to a specific pattern. Finally, a demonstration tool is also provided.
* 27 pages, 18 tables, 10 figures, journal paper
InterEvo-TR: Interactive Evolutionary Test Generation With Readability Assessment
Jan 13, 2024Automated test case generation has proven to be useful to reduce the usually high expenses of software testing. However, several studies have also noted the skepticism of testers regarding the comprehension of generated test suites when compared to manually designed ones. This fact suggests that involving testers in the test generation process could be helpful to increase their acceptance of automatically-produced test suites. In this paper, we propose incorporating interactive readability assessments made by a tester into EvoSuite, a widely-known evolutionary test generation tool. Our approach, InterEvo-TR, interacts with the tester at different moments during the search and shows different test cases covering the same coverage target for their subjective evaluation. The design of such an interactive approach involves a schedule of interaction, a method to diversify the selected targets, a plan to save and handle the readability values, and some mechanisms to customize the level of engagement in the revision, among other aspects. To analyze the potential and practicability of our proposal, we conduct a controlled experiment in which 39 participants, including academics, professional developers, and student collaborators, interact with InterEvo-TR. Our results show that the strategy to select and present intermediate results is effective for the purpose of readability assessment. Furthermore, the participants' actions and responses to a questionnaire allowed us to analyze the aspects influencing test code readability and the benefits and limitations of an interactive approach in the context of test case generation, paving the way for future developments based on interactivity.
* 17 pages, 10 figures, 5 tables, journal paper
Artificial intelligence to automate the systematic review of scientific literature
Jan 13, 2024Artificial intelligence (AI) has acquired notorious relevance in modern computing as it effectively solves complex tasks traditionally done by humans. AI provides methods to represent and infer knowledge, efficiently manipulate texts and learn from vast amount of data. These characteristics are applicable in many activities that human find laborious or repetitive, as is the case of the analysis of scientific literature. Manually preparing and writing a systematic literature review (SLR) takes considerable time and effort, since it requires planning a strategy, conducting the literature search and analysis, and reporting the findings. Depending on the area under study, the number of papers retrieved can be of hundreds or thousands, meaning that filtering those relevant ones and extracting the key information becomes a costly and error-prone process. However, some of the involved tasks are repetitive and, therefore, subject to automation by means of AI. In this paper, we present a survey of AI techniques proposed in the last 15 years to help researchers conduct systematic analyses of scientific literature. We describe the tasks currently supported, the types of algorithms applied, and available tools proposed in 34 primary studies. This survey also provides a historical perspective of the evolution of the field and the role that humans can play in an increasingly automated SLR process.
* 25 pages, 3 figures, 1 table, journal paper
Interactive Multi-Objective Evolutionary Optimization of Software Architectures
Jan 08, 2024While working on a software specification, designers usually need to evaluate different architectural alternatives to be sure that quality criteria are met. Even when these quality aspects could be expressed in terms of multiple software metrics, other qualitative factors cannot be numerically measured, but they are extracted from the engineer's know-how and prior experiences. In fact, detecting not only strong but also weak points in the different solutions seems to fit better with the way humans make their decisions. Putting the human in the loop brings new challenges to the search-based software engineering field, especially for those human-centered activities within the early analysis phase. This paper explores how the interactive evolutionary computation can serve as a basis for integrating the human's judgment into the search process. An interactive approach is proposed to discover software architectures, in which both quantitative and qualitative criteria are applied to guide a multi-objective evolutionary algorithm. The obtained feedback is incorporated into the fitness function using architectural preferences allowing the algorithm to discern between promising and poor solutions. Experimentation with real users has revealed that the proposed interaction mechanism can effectively guide the search towards those regions of the search space that are of real interest to the expert.
* 41 pages, 5 figures, journal "Information Sciences"
A Taxonomy of Information Attributes for Test Case Prioritisation: Applicability, Machine Learning
Jan 16, 2022
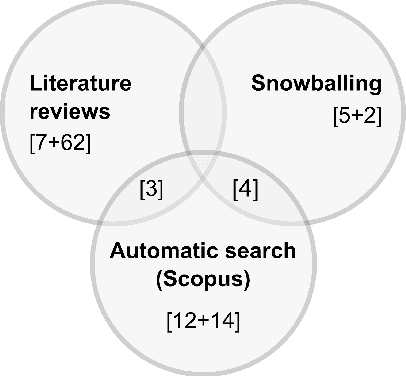
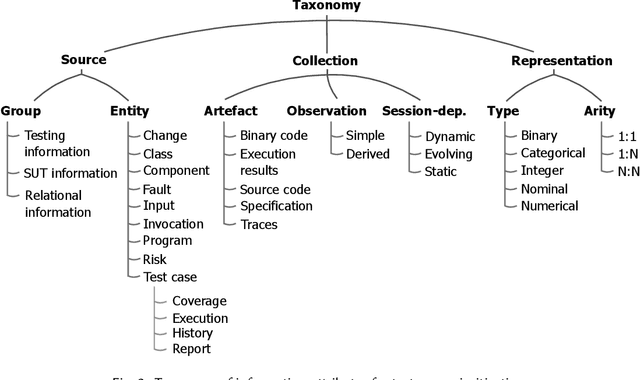
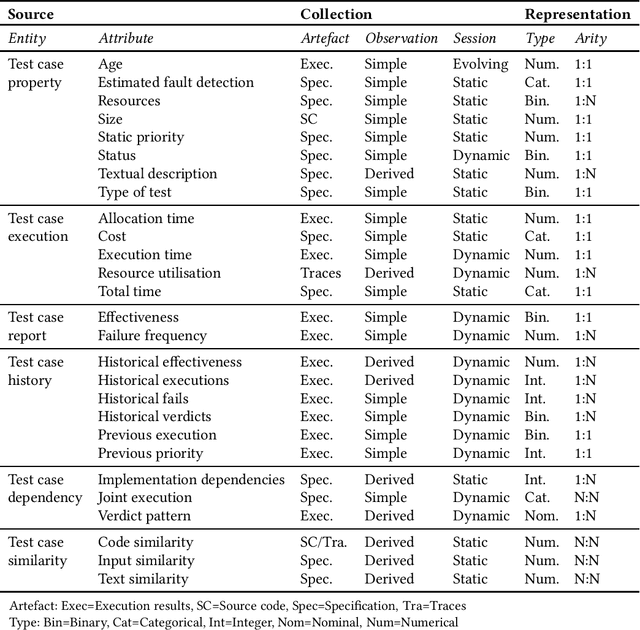
Most software companies have extensive test suites and re-run parts of them continuously to ensure recent changes have no adverse effects. Since test suites are costly to execute, industry needs methods for test case prioritisation (TCP). Recently, TCP methods use machine learning (ML) to exploit the information known about the system under test (SUT) and its test cases. However, the value added by ML-based TCP methods should be critically assessed with respect to the cost of collecting the information. This paper analyses two decades of TCP research, and presents a taxonomy of 91 information attributes that have been used. The attributes are classified with respect to their information sources and the characteristics of their extraction process. Based on this taxonomy, TCP methods validated with industrial data and those applying ML are analysed in terms of information availability, attribute combination and definition of data features suitable for ML. Relying on a high number of information attributes, assuming easy access to SUT code and simplified testing environments are identified as factors that might hamper industrial applicability of ML-based TCP. The TePIA taxonomy provides a reference framework to unify terminology and evaluate alternatives considering the cost-benefit of the information attributes.