 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Taxonomy of Information Attributes for Test Case Prioritisation: Applicability, Machine Learning
Paper and Code

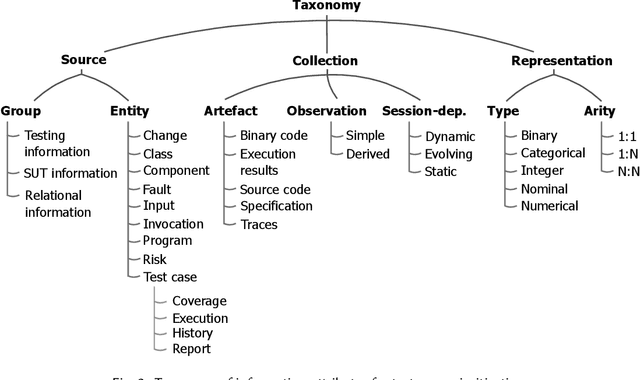
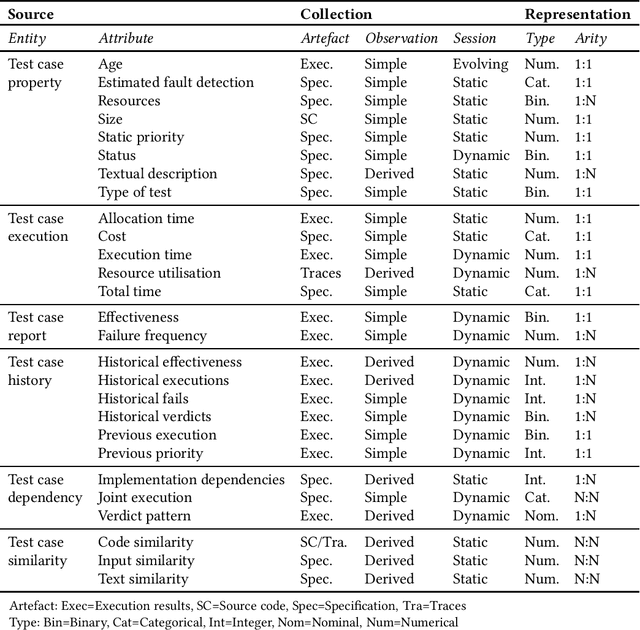
Most software companies have extensive test suites and re-run parts of them continuously to ensure recent changes have no adverse effects. Since test suites are costly to execute, industry needs methods for test case prioritisation (TCP). Recently, TCP methods use machine learning (ML) to exploit the information known about the system under test (SUT) and its test cases. However, the value added by ML-based TCP methods should be critically assessed with respect to the cost of collecting the information. This paper analyses two decades of TCP research, and presents a taxonomy of 91 information attributes that have been used. The attributes are classified with respect to their information sources and the characteristics of their extraction process. Based on this taxonomy, TCP methods validated with industrial data and those applying ML are analysed in terms of information availability, attribute combination and definition of data features suitable for ML. Relying on a high number of information attributes, assuming easy access to SUT code and simplified testing environments are identified as factors that might hamper industrial applicability of ML-based TCP. The TePIA taxonomy provides a reference framework to unify terminology and evaluate alternatives considering the cost-benefit of the information attributes.