 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA survey on learning from imbalanced data streams: taxonomy, challenges, empirical study, and reproducible experimental framework
Apr 07, 2022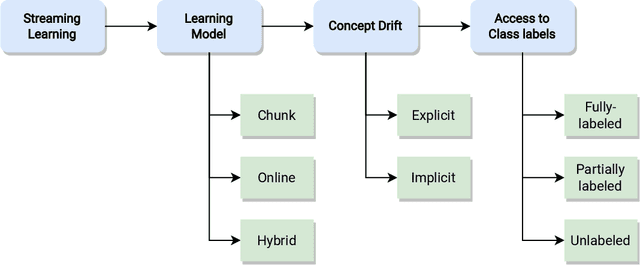
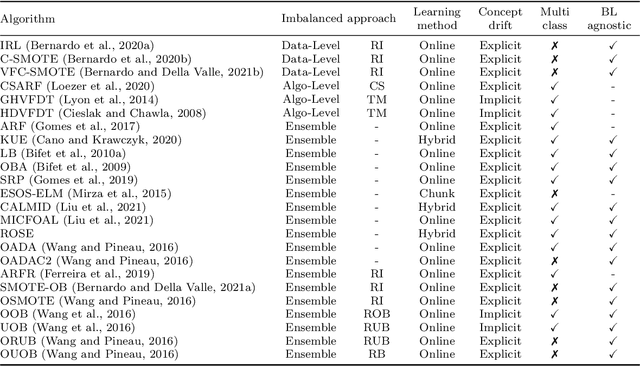
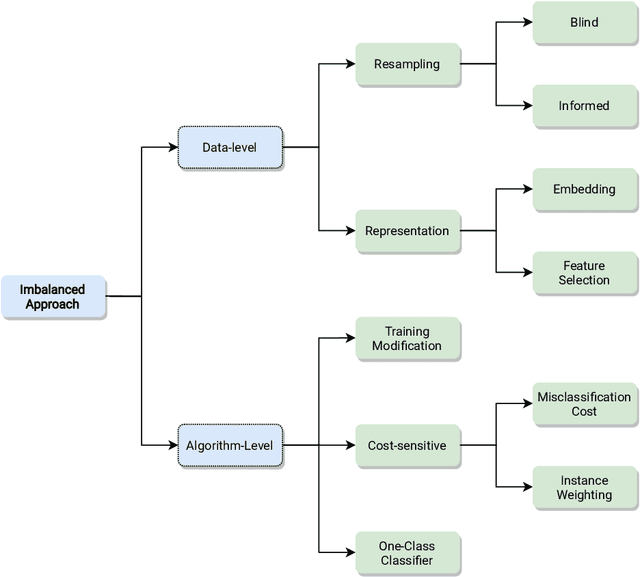
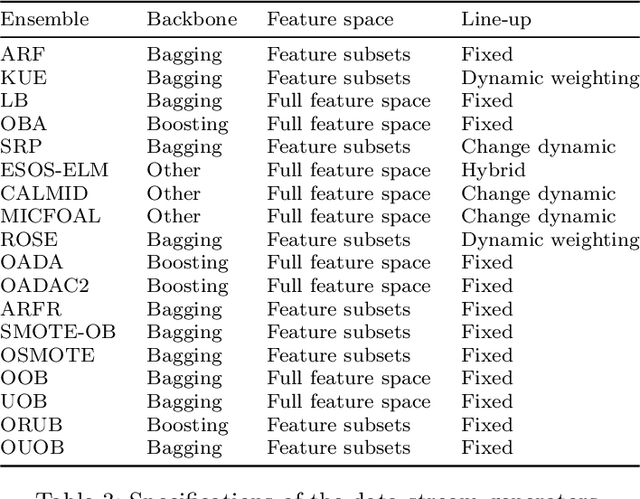
Class imbalance poses new challenges when it comes to classifying data streams. Many algorithms recently proposed in the literature tackle this problem using a variety of data-level, algorithm-level, and ensemble approaches. However, there is a lack of standardized and agreed-upon procedures on how to evaluate these algorithms. This work presents a taxonomy of algorithms for imbalanced data streams and proposes a standardized, exhaustive, and informative experimental testbed to evaluate algorithms in a collection of diverse and challenging imbalanced data stream scenarios. The experimental study evaluates 24 state-of-the-art data streams algorithms on 515 imbalanced data streams that combine static and dynamic class imbalance ratios, instance-level difficulties, concept drift, real-world and semi-synthetic datasets in binary and multi-class scenarios. This leads to the largest experimental study conducted so far in the data stream mining domain. We discuss the advantages and disadvantages of state-of-the-art classifiers in each of these scenarios and we provide general recommendations to end-users for selecting the best algorithms for imbalanced data streams. Additionally, we formulate open challenges and future directions for this domain. Our experimental testbed is fully reproducible and easy to extend with new methods. This way we propose the first standardized approach to conducting experiments in imbalanced data streams that can be used by other researchers to create trustworthy and fair evaluation of newly proposed methods. Our experimental framework can be downloaded from https://github.com/canoalberto/imbalanced-streams.