 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Group Fairness in Federated Learning: Challenges, Taxonomy of Solutions and Directions for Future Research
Paper and Code
Oct 04, 2024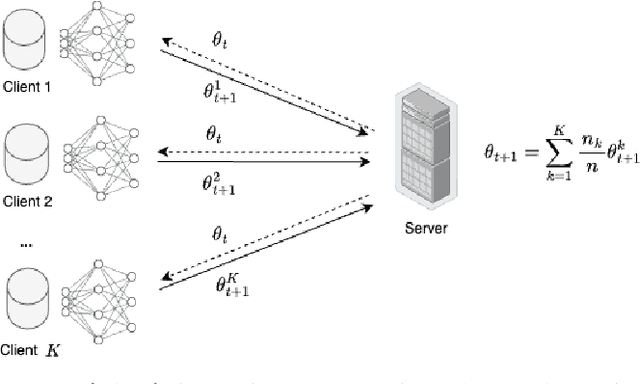


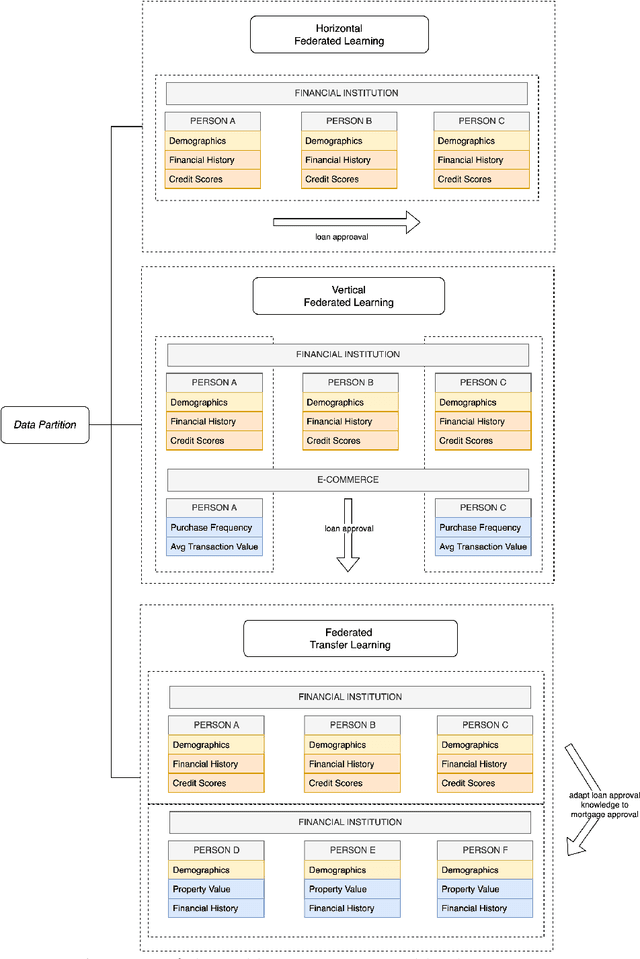
Group fairness in machine learning is a critical area of research focused on achieving equitable outcomes across different groups defined by sensitive attributes such as race or gender. Federated learning, a decentralized approach to training machine learning models across multiple devices or organizations without sharing raw data, amplifies the need for fairness due to the heterogeneous data distributions across clients, which can exacerbate biases. The intersection of federated learning and group fairness has attracted significant interest, with 47 research works specifically dedicated to addressing this issue. However, no dedicated survey has focused comprehensively on group fairness in federated learning. In this work, we present an in-depth survey on this topic, addressing the critical challenges and reviewing related works in the field. We create a novel taxonomy of these approaches based on key criteria such as data partitioning, location, and applied strategies. Additionally, we explore broader concerns related to this problem and investigate how different approaches handle the complexities of various sensitive groups and their intersections. Finally, we review the datasets and applications commonly used in current research. We conclude by highlighting key areas for future research, emphasizing the need for more methods to address the complexities of achieving group fairness in federated systems.