 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Group Fairness in Federated Learning: Challenges, Taxonomy of Solutions and Directions for Future Research
Oct 04, 2024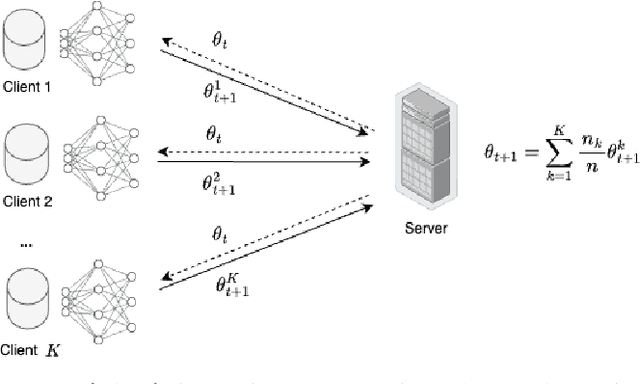


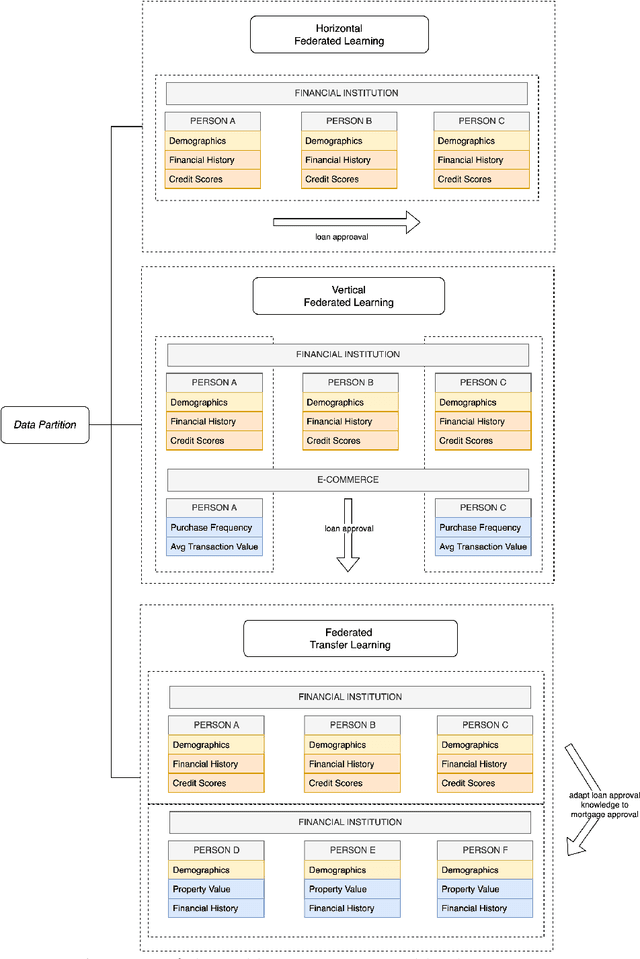
Group fairness in machine learning is a critical area of research focused on achieving equitable outcomes across different groups defined by sensitive attributes such as race or gender. Federated learning, a decentralized approach to training machine learning models across multiple devices or organizations without sharing raw data, amplifies the need for fairness due to the heterogeneous data distributions across clients, which can exacerbate biases. The intersection of federated learning and group fairness has attracted significant interest, with 47 research works specifically dedicated to addressing this issue. However, no dedicated survey has focused comprehensively on group fairness in federated learning. In this work, we present an in-depth survey on this topic, addressing the critical challenges and reviewing related works in the field. We create a novel taxonomy of these approaches based on key criteria such as data partitioning, location, and applied strategies. Additionally, we explore broader concerns related to this problem and investigate how different approaches handle the complexities of various sensitive groups and their intersections. Finally, we review the datasets and applications commonly used in current research. We conclude by highlighting key areas for future research, emphasizing the need for more methods to address the complexities of achieving group fairness in federated systems.
Unveiling Group-Specific Distributed Concept Drift: A Fairness Imperative in Federated Learning
Feb 12, 2024In the evolving field of machine learning, ensuring fairness has become a critical concern, prompting the development of algorithms designed to mitigate discriminatory outcomes in decision-making processes. However, achieving fairness in the presence of group-specific concept drift remains an unexplored frontier, and our research represents pioneering efforts in this regard. Group-specific concept drift refers to situations where one group experiences concept drift over time while another does not, leading to a decrease in fairness even if accuracy remains fairly stable. Within the framework of federated learning, where clients collaboratively train models, its distributed nature further amplifies these challenges since each client can experience group-specific concept drift independently while still sharing the same underlying concept, creating a complex and dynamic environment for maintaining fairness. One of the significant contributions of our research is the formalization and introduction of the problem of group-specific concept drift and its distributed counterpart, shedding light on its critical importance in the realm of fairness. In addition, leveraging insights from prior research, we adapt an existing distributed concept drift adaptation algorithm to tackle group-specific distributed concept drift which utilizes a multi-model approach, a local group-specific drift detection mechanism, and continuous clustering of models over time. The findings from our experiments highlight the importance of addressing group-specific concept drift and its distributed counterpart to advance fairness in machine learning.