 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding CNN Fragility When Learning With Imbalanced Data
Oct 17, 2022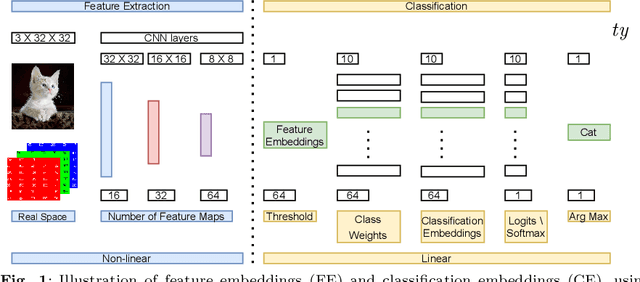
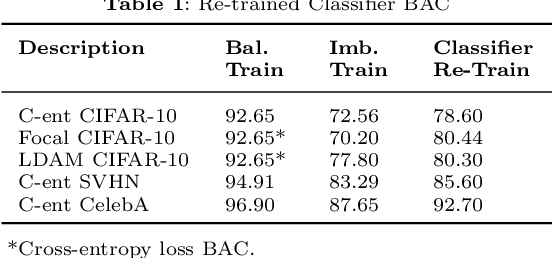
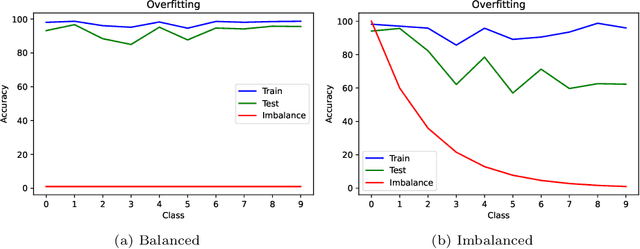
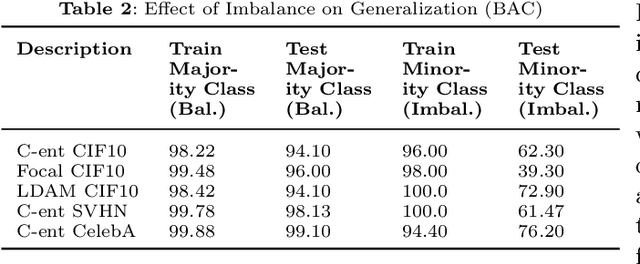
Convolutional neural networks (CNNs) have achieved impressive results on imbalanced image data, but they still have difficulty generalizing to minority classes and their decisions are difficult to interpret. These problems are related because the method by which CNNs generalize to minority classes, which requires improvement, is wrapped in a blackbox. To demystify CNN decisions on imbalanced data, we focus on their latent features. Although CNNs embed the pattern knowledge learned from a training set in model parameters, the effect of this knowledge is contained in feature and classification embeddings (FE and CE). These embeddings can be extracted from a trained model and their global, class properties (e.g., frequency, magnitude and identity) can be analyzed. We find that important information regarding the ability of a neural network to generalize to minority classes resides in the class top-K CE and FE. We show that a CNN learns a limited number of class top-K CE per category, and that their number and magnitudes vary based on whether the same class is balanced or imbalanced. This calls into question whether a CNN has learned intrinsic class features, or merely frequently occurring ones that happen to exist in the sampled class distribution. We also hypothesize that latent class diversity is as important as the number of class examples, which has important implications for re-sampling and cost-sensitive methods. These methods generally focus on rebalancing model weights, class numbers and margins; instead of diversifying class latent features through augmentation. We also demonstrate that a CNN has difficulty generalizing to test data if the magnitude of its top-K latent features do not match the training set. We use three popular image datasets and two cost-sensitive algorithms commonly employed in imbalanced learning for our experiments.
Towards A Holistic View of Bias in Machine Learning: Bridging Algorithmic Fairness and Imbalanced Learning
Jul 13, 2022
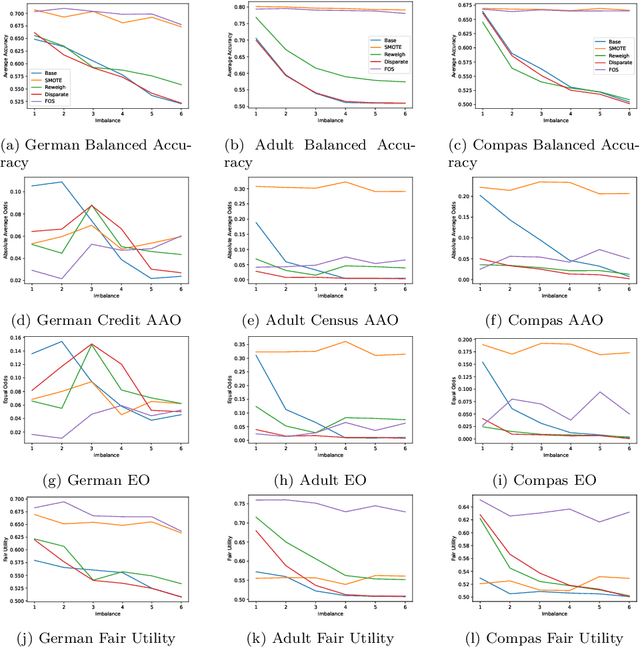
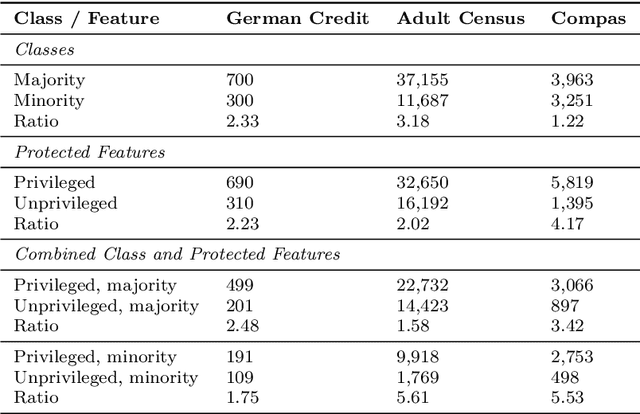
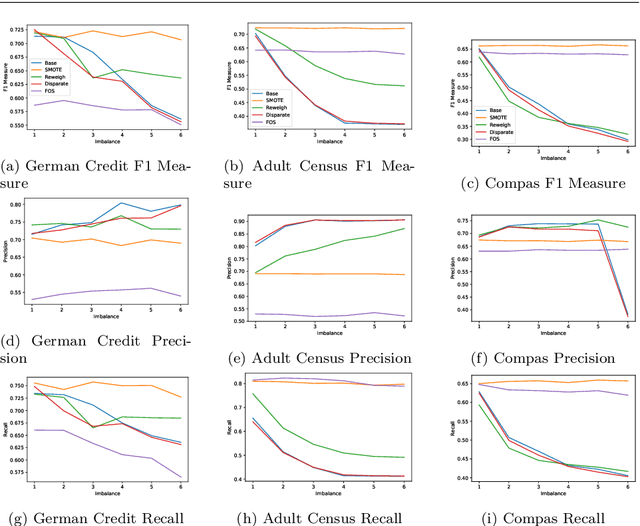
Machine learning (ML) is playing an increasingly important role in rendering decisions that affect a broad range of groups in society. ML models inform decisions in criminal justice, the extension of credit in banking, and the hiring practices of corporations. This posits the requirement of model fairness, which holds that automated decisions should be equitable with respect to protected features (e.g., gender, race, or age) that are often under-represented in the data. We postulate that this problem of under-representation has a corollary to the problem of imbalanced data learning. This class imbalance is often reflected in both classes and protected features. For example, one class (those receiving credit) may be over-represented with respect to another class (those not receiving credit) and a particular group (females) may be under-represented with respect to another group (males). A key element in achieving algorithmic fairness with respect to protected groups is the simultaneous reduction of class and protected group imbalance in the underlying training data, which facilitates increases in both model accuracy and fairness. We discuss the importance of bridging imbalanced learning and group fairness by showing how key concepts in these fields overlap and complement each other; and propose a novel oversampling algorithm, Fair Oversampling, that addresses both skewed class distributions and protected features. Our method: (i) can be used as an efficient pre-processing algorithm for standard ML algorithms to jointly address imbalance and group equity; and (ii) can be combined with fairness-aware learning algorithms to improve their robustness to varying levels of class imbalance. Additionally, we take a step toward bridging the gap between fairness and imbalanced learning with a new metric, Fair Utility, that combines balanced accuracy with fairness.
Efficient Augmentation for Imbalanced Deep Learning
Jul 13, 2022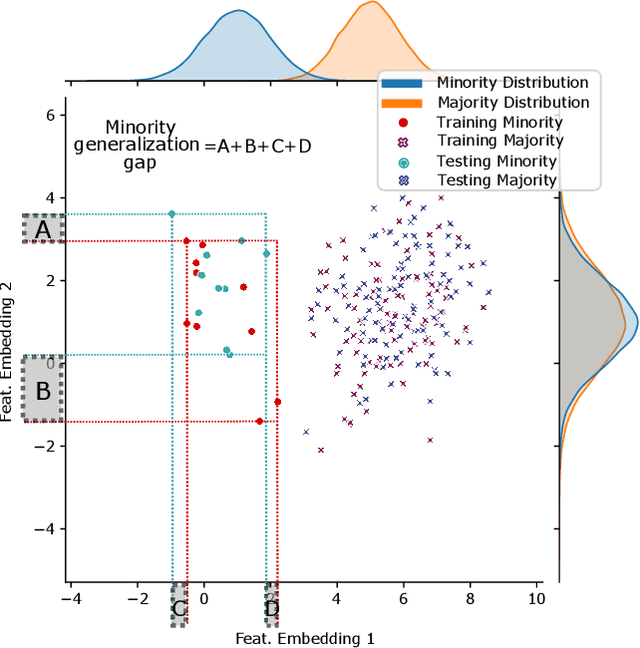
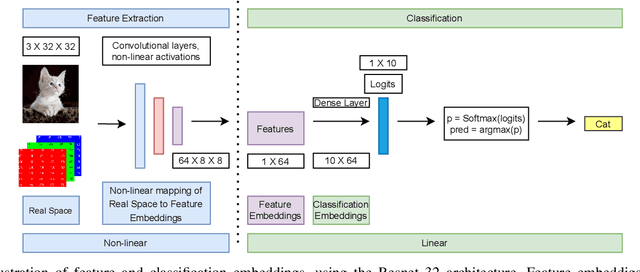
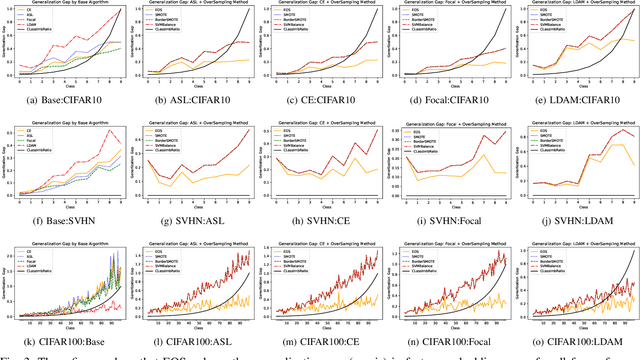
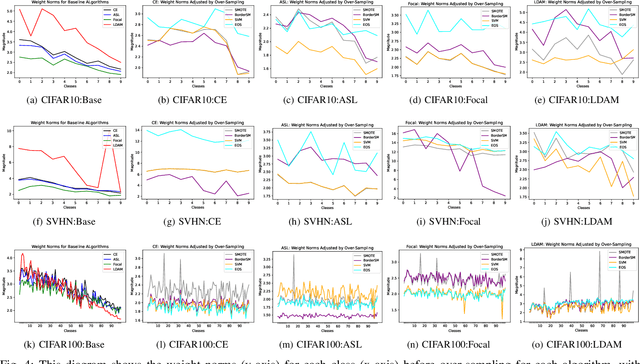
Deep learning models memorize training data, which hurts their ability to generalize to under-represented classes. We empirically study a convolutional neural network's internal representation of imbalanced image data and measure the generalization gap between a model's feature embeddings in the training and test sets, showing that the gap is wider for minority classes. This insight enables us to design an efficient three-phase CNN training framework for imbalanced data. The framework involves training the network end-to-end on imbalanced data to learn accurate feature embeddings, performing data augmentation in the learned embedded space to balance the train distribution, and fine-tuning the classifier head on the embedded balanced training data. We propose Expansive Over-Sampling (EOS) as a data augmentation technique to utilize in the training framework. EOS forms synthetic training instances as convex combinations between the minority class samples and their nearest enemies in the embedded space to reduce the generalization gap. The proposed framework improves the accuracy over leading cost-sensitive and resampling methods commonly used in imbalanced learning. Moreover, it is more computationally efficient than standard data pre-processing methods, such as SMOTE and GAN-based oversampling, as it requires fewer parameters and less training time.
Developing an NLP-based Recommender System for the Ethical, Legal, and Social Implications of Synthetic Biology
Jul 10, 2022
Synthetic biology is an emerging field that involves the engineering and re-design of organisms for purposes such as food security, health, and environmental protection. As such, it poses numerous ethical, legal, and social implications (ELSI) for researchers and policy makers. Various efforts to ensure socially responsible synthetic biology are underway. Policy making is one regulatory avenue, and other initiatives have sought to embed social scientists and ethicists on synthetic biology projects. However, given the nascency of synthetic biology, the number of heterogeneous domains it spans, and the open nature of many ethical questions, it has proven challenging to establish widespread concrete policies, and including social scientists and ethicists on synthetic biology teams has met with mixed success. This text proposes a different approach, asking instead is it possible to develop a well-performing recommender model based upon natural language processing (NLP) to connect synthetic biologists with information on the ELSI of their specific research? This recommender was developed as part of a larger project building a Synthetic Biology Knowledge System (SBKS) to accelerate discovery and exploration of the synthetic biology design space. Our approach aims to distill for synthetic biologists relevant ethical and social scientific information and embed it into synthetic biology research workflows.
DeepSMOTE: Fusing Deep Learning and SMOTE for Imbalanced Data
May 05, 2021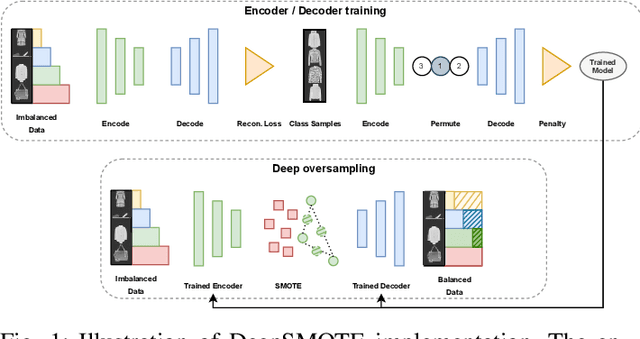

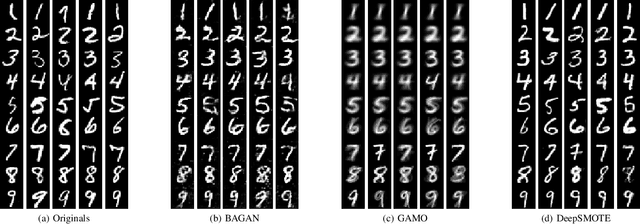

Despite over two decades of progress, imbalanced data is still considered a significant challenge for contemporary machine learning models. Modern advances in deep learning have magnified the importance of the imbalanced data problem. The two main approaches to address this issue are based on loss function modifications and instance resampling. Instance sampling is typically based on Generative Adversarial Networks (GANs), which may suffer from mode collapse. Therefore, there is a need for an oversampling method that is specifically tailored to deep learning models, can work on raw images while preserving their properties, and is capable of generating high quality, artificial images that can enhance minority classes and balance the training set. We propose DeepSMOTE - a novel oversampling algorithm for deep learning models. It is simple, yet effective in its design. It consists of three major components: (i) an encoder/decoder framework; (ii) SMOTE-based oversampling; and (iii) a dedicated loss function that is enhanced with a penalty term. An important advantage of DeepSMOTE over GAN-based oversampling is that DeepSMOTE does not require a discriminator, and it generates high-quality artificial images that are both information-rich and suitable for visual inspection. DeepSMOTE code is publicly available at: https://github.com/dd1github/DeepSMOTE