 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards A Holistic View of Bias in Machine Learning: Bridging Algorithmic Fairness and Imbalanced Learning
Paper and Code

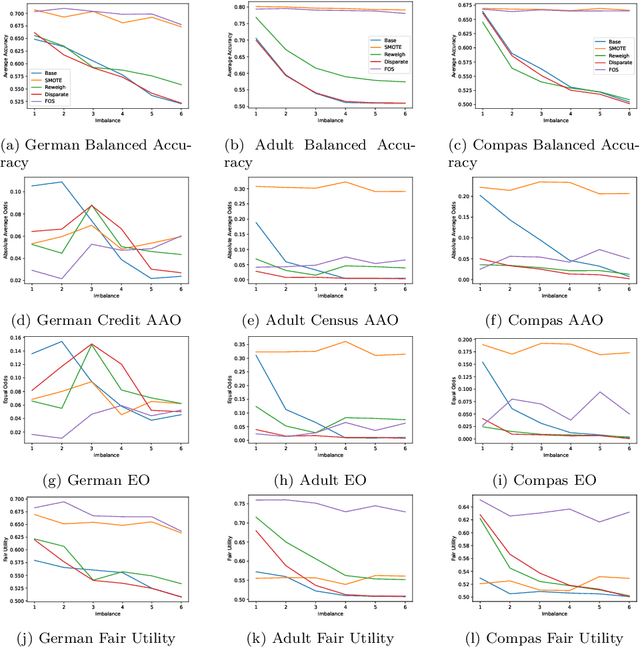
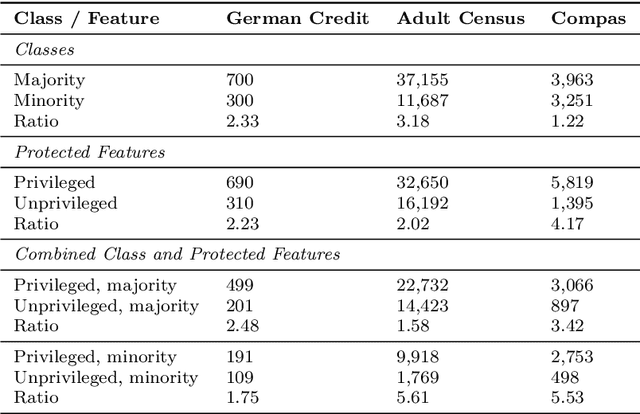
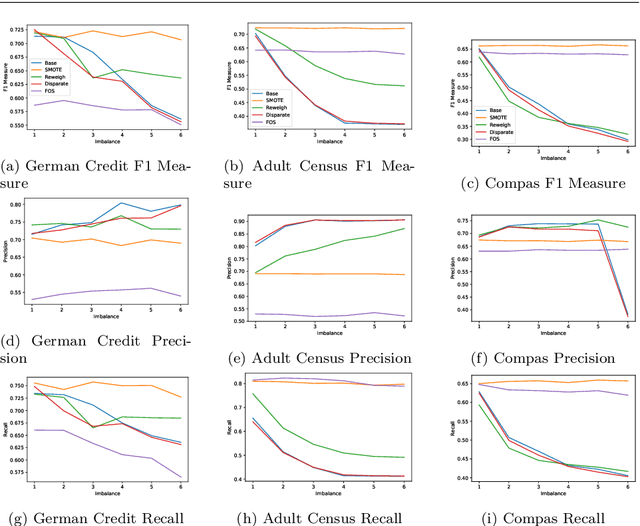
Machine learning (ML) is playing an increasingly important role in rendering decisions that affect a broad range of groups in society. ML models inform decisions in criminal justice, the extension of credit in banking, and the hiring practices of corporations. This posits the requirement of model fairness, which holds that automated decisions should be equitable with respect to protected features (e.g., gender, race, or age) that are often under-represented in the data. We postulate that this problem of under-representation has a corollary to the problem of imbalanced data learning. This class imbalance is often reflected in both classes and protected features. For example, one class (those receiving credit) may be over-represented with respect to another class (those not receiving credit) and a particular group (females) may be under-represented with respect to another group (males). A key element in achieving algorithmic fairness with respect to protected groups is the simultaneous reduction of class and protected group imbalance in the underlying training data, which facilitates increases in both model accuracy and fairness. We discuss the importance of bridging imbalanced learning and group fairness by showing how key concepts in these fields overlap and complement each other; and propose a novel oversampling algorithm, Fair Oversampling, that addresses both skewed class distributions and protected features. Our method: (i) can be used as an efficient pre-processing algorithm for standard ML algorithms to jointly address imbalance and group equity; and (ii) can be combined with fairness-aware learning algorithms to improve their robustness to varying levels of class imbalance. Additionally, we take a step toward bridging the gap between fairness and imbalanced learning with a new metric, Fair Utility, that combines balanced accuracy with fairness.