 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Policy Gradient Methods Without Batch Updates, Target Networks, or Replay Buffers
Nov 22, 2024Modern deep policy gradient methods achieve effective performance on simulated robotic tasks, but they all require large replay buffers or expensive batch updates, or both, making them incompatible for real systems with resource-limited computers. We show that these methods fail catastrophically when limited to small replay buffers or during incremental learning, where updates only use the most recent sample without batch updates or a replay buffer. We propose a novel incremental deep policy gradient method -- Action Value Gradient (AVG) and a set of normalization and scaling techniques to address the challenges of instability in incremental learning. On robotic simulation benchmarks, we show that AVG is the only incremental method that learns effectively, often achieving final performance comparable to batch policy gradient methods. This advancement enabled us to show for the first time effective deep reinforcement learning with real robots using only incremental updates, employing a robotic manipulator and a mobile robot.
Learning Visual Tracking and Reaching with Deep Reinforcement Learning on a UR10e Robotic Arm
Aug 28, 2023



As technology progresses, industrial and scientific robots are increasingly being used in diverse settings. In many cases, however, programming the robot to perform such tasks is technically complex and costly. To maximize the utility of robots in industrial and scientific settings, they require the ability to quickly shift from one task to another. Reinforcement learning algorithms provide the potential to enable robots to learn optimal solutions to complete new tasks without directly reprogramming them. The current state-of-the-art in reinforcement learning, however, generally relies on fast simulations and parallelization to achieve optimal performance. These are often not possible in robotics applications. Thus, a significant amount of research is required to facilitate the efficient and safe, training and deployment of industrial and scientific reinforcement learning robots. This technical report outlines our initial research into the application of deep reinforcement learning on an industrial UR10e robot. The report describes the reinforcement learning environments created to facilitate policy learning with the UR10e, a robotic arm from Universal Robots, and presents our initial results in training deep Q-learning and proximal policy optimization agents on the developed reinforcement learning environments. Our results show that proximal policy optimization learns a better, more stable policy with less data than deep Q-learning. The corresponding code for this work is available at \url{https://github.com/cbellinger27/bendRL_reacher_tracker}
Learning when to observe: A frugal reinforcement learning framework for a high-cost world
Jul 24, 2023



Reinforcement learning (RL) has been shown to learn sophisticated control policies for complex tasks including games, robotics, heating and cooling systems and text generation. The action-perception cycle in RL, however, generally assumes that a measurement of the state of the environment is available at each time step without a cost. In applications such as materials design, deep-sea and planetary robot exploration and medicine, however, there can be a high cost associated with measuring, or even approximating, the state of the environment. In this paper, we survey the recently growing literature that adopts the perspective that an RL agent might not need, or even want, a costly measurement at each time step. Within this context, we propose the Deep Dynamic Multi-Step Observationless Agent (DMSOA), contrast it with the literature and empirically evaluate it on OpenAI gym and Atari Pong environments. Our results, show that DMSOA learns a better policy with fewer decision steps and measurements than the considered alternative from the literature. The corresponding code is available at: \url{https://github.com/cbellinger27/Learning-when-to-observe-in-RL
ChemGymRL: An Interactive Framework for Reinforcement Learning for Digital Chemistry
May 23, 2023



This paper provides a simulated laboratory for making use of Reinforcement Learning (RL) for chemical discovery. Since RL is fairly data intensive, training agents `on-the-fly' by taking actions in the real world is infeasible and possibly dangerous. Moreover, chemical processing and discovery involves challenges which are not commonly found in RL benchmarks and therefore offer a rich space to work in. We introduce a set of highly customizable and open-source RL environments, ChemGymRL, based on the standard Open AI Gym template. ChemGymRL supports a series of interconnected virtual chemical benches where RL agents can operate and train. The paper introduces and details each of these benches using well-known chemical reactions as illustrative examples, and trains a set of standard RL algorithms in each of these benches. Finally, discussion and comparison of the performances of several standard RL methods are provided in addition to a list of directions for future work as a vision for the further development and usage of ChemGymRL.
Reinforcement Learning-based Wavefront Sensorless Adaptive Optics Approaches for Satellite-to-Ground Laser Communication
Mar 13, 2023
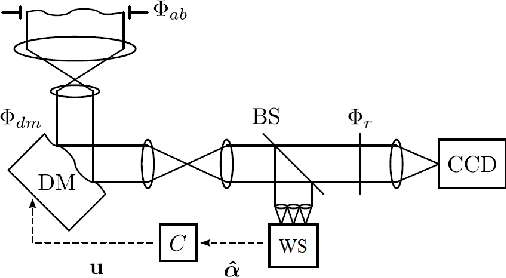
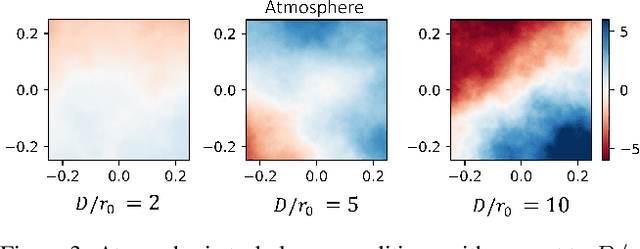
Optical satellite-to-ground communication (OSGC) has the potential to improve access to fast and affordable Internet in remote regions. Atmospheric turbulence, however, distorts the optical beam, eroding the data rate potential when coupling into single-mode fibers. Traditional adaptive optics (AO) systems use a wavefront sensor to improve fiber coupling. This leads to higher system size, cost and complexity, consumes a fraction of the incident beam and introduces latency, making OSGC for internet service impractical. We propose the use of reinforcement learning (RL) to reduce the latency, size and cost of the system by up to $30-40\%$ by learning a control policy through interactions with a low-cost quadrant photodiode rather than a wavefront phase profiling camera. We develop and share an AO RL environment that provides a standardized platform to develop and evaluate RL based on the Strehl ratio, which is correlated to fiber-coupling performance. Our empirical analysis finds that Proximal Policy Optimization (PPO) outperforms Soft-Actor-Critic and Deep Deterministic Policy Gradient. PPO converges to within $86\%$ of the maximum reward obtained by an idealized Shack-Hartmann sensor after training of 250 episodes, indicating the potential of RL to enable efficient wavefront sensorless OSGC.
Interpretable ML for Imbalanced Data
Dec 15, 2022
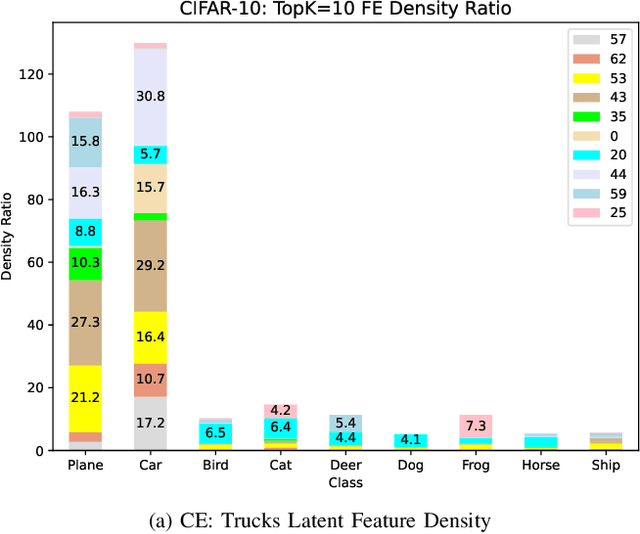


Deep learning models are being increasingly applied to imbalanced data in high stakes fields such as medicine, autonomous driving, and intelligence analysis. Imbalanced data compounds the black-box nature of deep networks because the relationships between classes may be highly skewed and unclear. This can reduce trust by model users and hamper the progress of developers of imbalanced learning algorithms. Existing methods that investigate imbalanced data complexity are geared toward binary classification, shallow learning models and low dimensional data. In addition, current eXplainable Artificial Intelligence (XAI) techniques mainly focus on converting opaque deep learning models into simpler models (e.g., decision trees) or mapping predictions for specific instances to inputs, instead of examining global data properties and complexities. Therefore, there is a need for a framework that is tailored to modern deep networks, that incorporates large, high dimensional, multi-class datasets, and uncovers data complexities commonly found in imbalanced data (e.g., class overlap, sub-concepts, and outlier instances). We propose a set of techniques that can be used by both deep learning model users to identify, visualize and understand class prototypes, sub-concepts and outlier instances; and by imbalanced learning algorithm developers to detect features and class exemplars that are key to model performance. Our framework also identifies instances that reside on the border of class decision boundaries, which can carry highly discriminative information. Unlike many existing XAI techniques which map model decisions to gray-scale pixel locations, we use saliency through back-propagation to identify and aggregate image color bands across entire classes. Our framework is publicly available at \url{https://github.com/dd1github/XAI_for_Imbalanced_Learning}
Understanding CNN Fragility When Learning With Imbalanced Data
Oct 17, 2022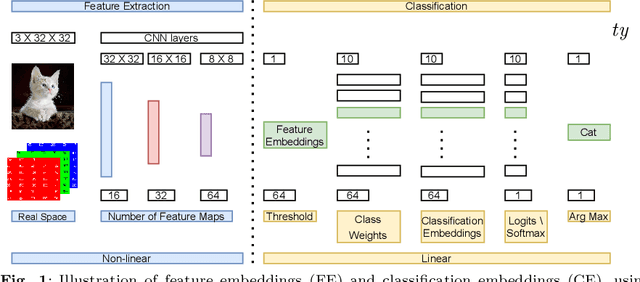
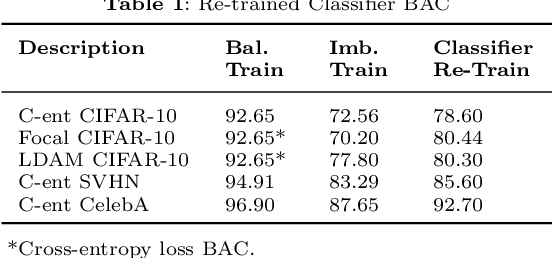
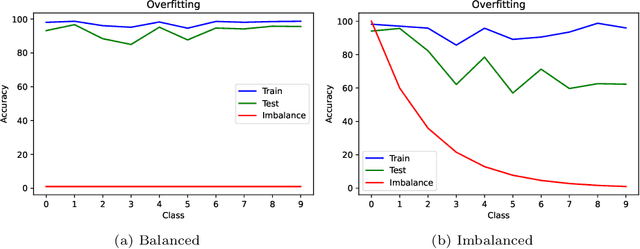
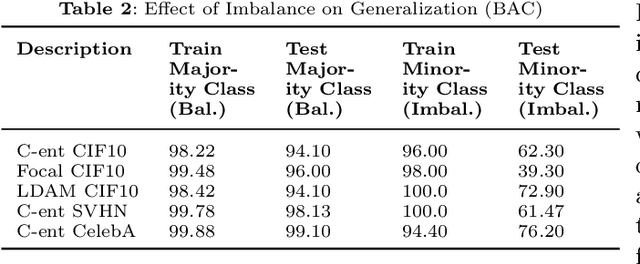
Convolutional neural networks (CNNs) have achieved impressive results on imbalanced image data, but they still have difficulty generalizing to minority classes and their decisions are difficult to interpret. These problems are related because the method by which CNNs generalize to minority classes, which requires improvement, is wrapped in a blackbox. To demystify CNN decisions on imbalanced data, we focus on their latent features. Although CNNs embed the pattern knowledge learned from a training set in model parameters, the effect of this knowledge is contained in feature and classification embeddings (FE and CE). These embeddings can be extracted from a trained model and their global, class properties (e.g., frequency, magnitude and identity) can be analyzed. We find that important information regarding the ability of a neural network to generalize to minority classes resides in the class top-K CE and FE. We show that a CNN learns a limited number of class top-K CE per category, and that their number and magnitudes vary based on whether the same class is balanced or imbalanced. This calls into question whether a CNN has learned intrinsic class features, or merely frequently occurring ones that happen to exist in the sampled class distribution. We also hypothesize that latent class diversity is as important as the number of class examples, which has important implications for re-sampling and cost-sensitive methods. These methods generally focus on rebalancing model weights, class numbers and margins; instead of diversifying class latent features through augmentation. We also demonstrate that a CNN has difficulty generalizing to test data if the magnitude of its top-K latent features do not match the training set. We use three popular image datasets and two cost-sensitive algorithms commonly employed in imbalanced learning for our experiments.
Efficient Augmentation for Imbalanced Deep Learning
Jul 13, 2022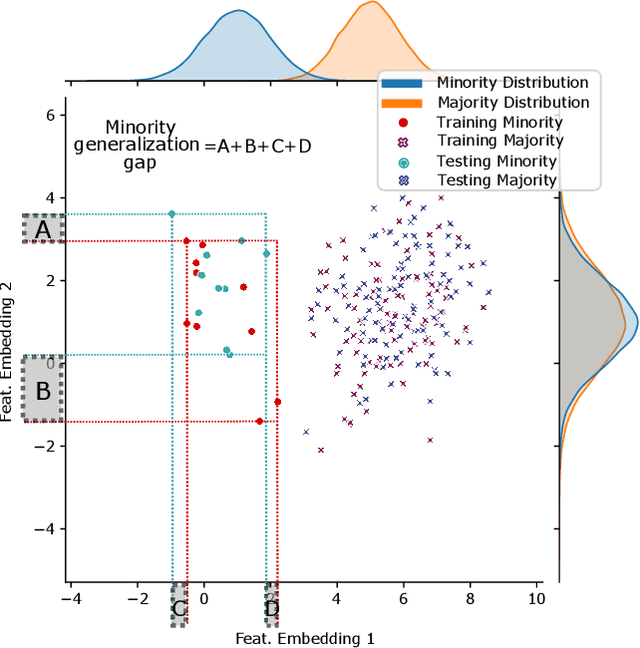
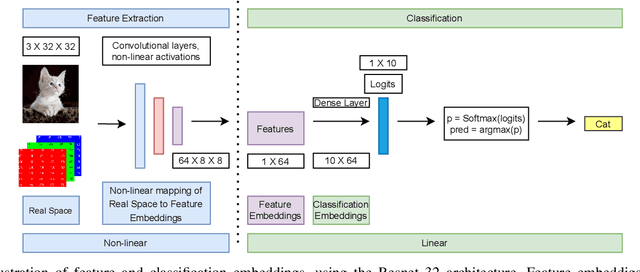
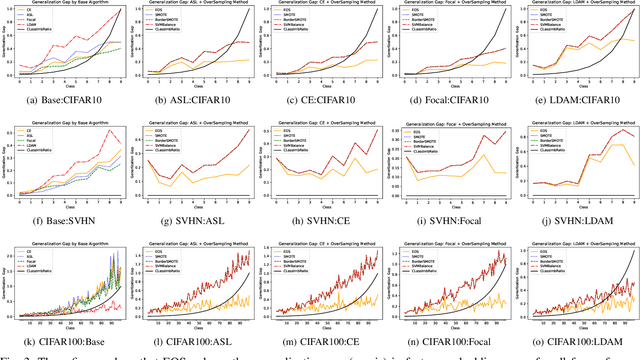
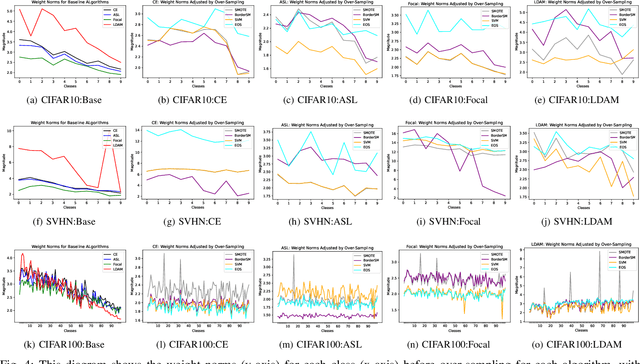
Deep learning models memorize training data, which hurts their ability to generalize to under-represented classes. We empirically study a convolutional neural network's internal representation of imbalanced image data and measure the generalization gap between a model's feature embeddings in the training and test sets, showing that the gap is wider for minority classes. This insight enables us to design an efficient three-phase CNN training framework for imbalanced data. The framework involves training the network end-to-end on imbalanced data to learn accurate feature embeddings, performing data augmentation in the learned embedded space to balance the train distribution, and fine-tuning the classifier head on the embedded balanced training data. We propose Expansive Over-Sampling (EOS) as a data augmentation technique to utilize in the training framework. EOS forms synthetic training instances as convex combinations between the minority class samples and their nearest enemies in the embedded space to reduce the generalization gap. The proposed framework improves the accuracy over leading cost-sensitive and resampling methods commonly used in imbalanced learning. Moreover, it is more computationally efficient than standard data pre-processing methods, such as SMOTE and GAN-based oversampling, as it requires fewer parameters and less training time.
Automated Imbalanced Classification via Layered Learning
May 05, 2022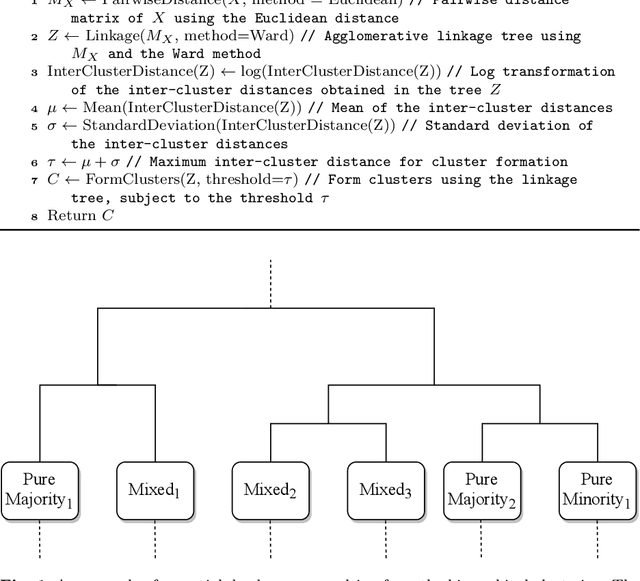
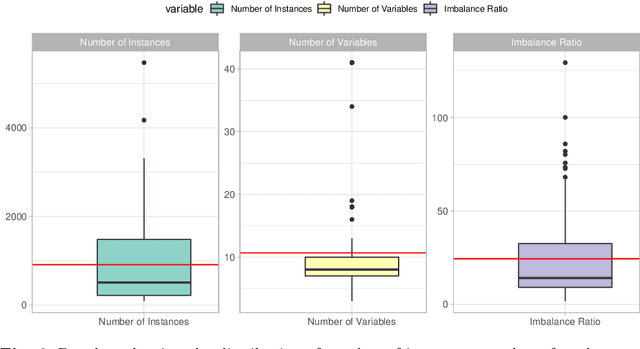

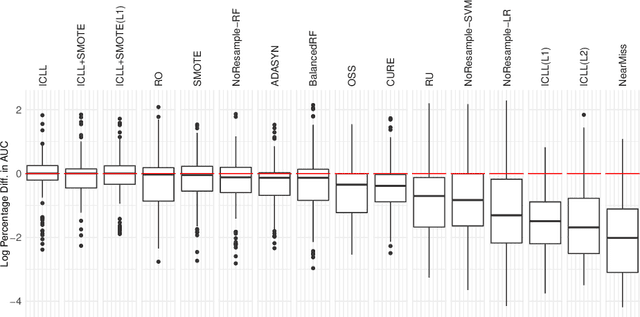
In this paper we address imbalanced binary classification (IBC) tasks. Applying resampling strategies to balance the class distribution of training instances is a common approach to tackle these problems. Many state-of-the-art methods find instances of interest close to the decision boundary to drive the resampling process. However, under-sampling the majority class may potentially lead to important information loss. Over-sampling also may increase the chance of overfitting by propagating the information contained in instances from the minority class. The main contribution of our work is a new method called ICLL for tackling IBC tasks which is not based on resampling training observations. Instead, ICLL follows a layered learning paradigm to model the data in two stages. In the first layer, ICLL learns to distinguish cases close to the decision boundary from cases which are clearly from the majority class, where this dichotomy is defined using a hierarchical clustering analysis. In the subsequent layer, we use instances close to the decision boundary and instances from the minority class to solve the original predictive task. A second contribution of our work is the automatic definition of the layers which comprise the layered learning strategy using a hierarchical clustering model. This is a relevant discovery as this process is usually performed manually according to domain knowledge. We carried out extensive experiments using 100 benchmark data sets. The results show that the proposed method leads to a better performance relatively to several state-of-the-art methods for IBC.
Scientific Discovery and the Cost of Measurement -- Balancing Information and Cost in Reinforcement Learning
Dec 14, 2021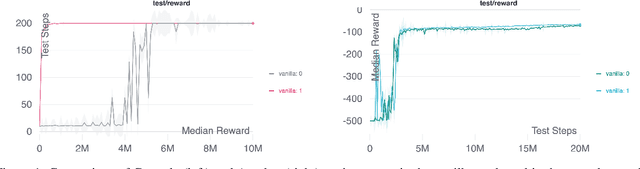
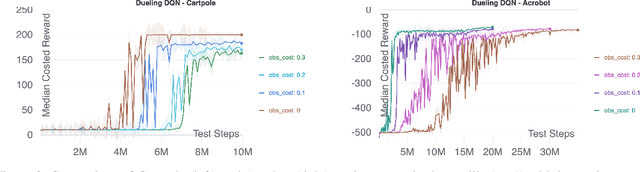


The use of reinforcement learning (RL) in scientific applications, such as materials design and automated chemistry, is increasing. A major challenge, however, lies in fact that measuring the state of the system is often costly and time consuming in scientific applications, whereas policy learning with RL requires a measurement after each time step. In this work, we make the measurement costs explicit in the form of a costed reward and propose a framework that enables off-the-shelf deep RL algorithms to learn a policy for both selecting actions and determining whether or not to measure the current state of the system at each time step. In this way, the agents learn to balance the need for information with the cost of information. Our results show that when trained under this regime, the Dueling DQN and PPO agents can learn optimal action policies whilst making up to 50\% fewer state measurements, and recurrent neural networks can produce a greater than 50\% reduction in measurements. We postulate the these reduction can help to lower the barrier to applying RL to real-world scientific applications.