 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL-GTA: Latent Generative Modeling for Time Series Augmentation
Jul 31, 2025Data augmentation is gaining importance across various aspects of time series analysis, from forecasting to classification and anomaly detection tasks. We introduce the Latent Generative Transformer Augmentation (L-GTA) model, a generative approach using a transformer-based variational recurrent autoencoder. This model uses controlled transformations within the latent space of the model to generate new time series that preserve the intrinsic properties of the original dataset. L-GTA enables the application of diverse transformations, ranging from simple jittering to magnitude warping, and combining these basic transformations to generate more complex synthetic time series datasets. Our evaluation of several real-world datasets demonstrates the ability of L-GTA to produce more reliable, consistent, and controllable augmented data. This translates into significant improvements in predictive accuracy and similarity measures compared to direct transformation methods.
Cherry-Picking in Time Series Forecasting: How to Select Datasets to Make Your Model Shine
Dec 19, 2024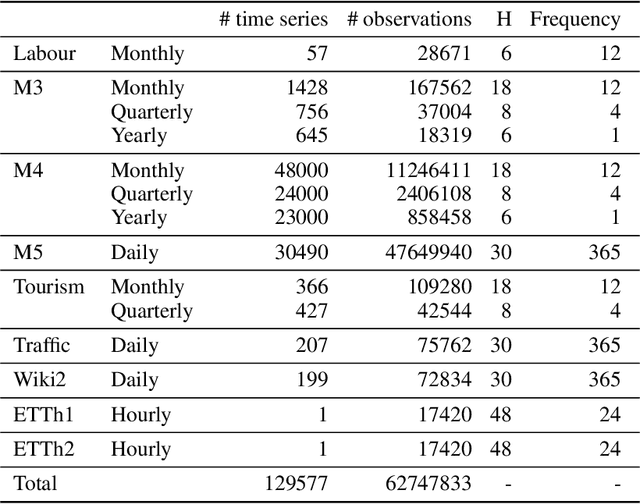
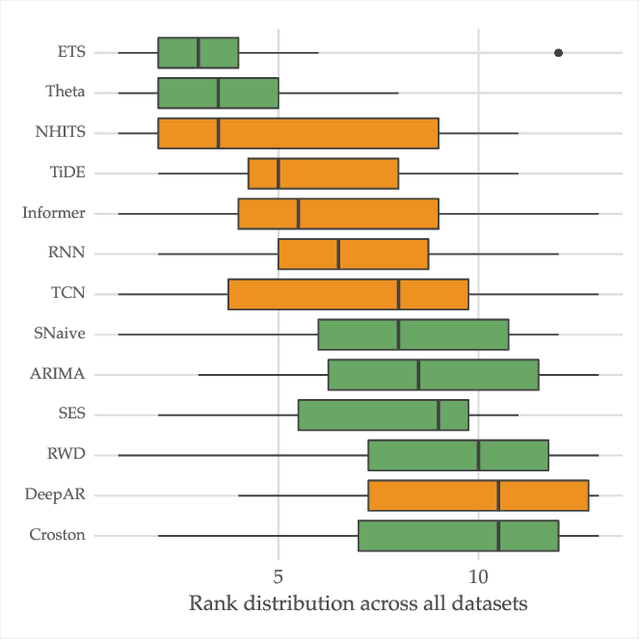
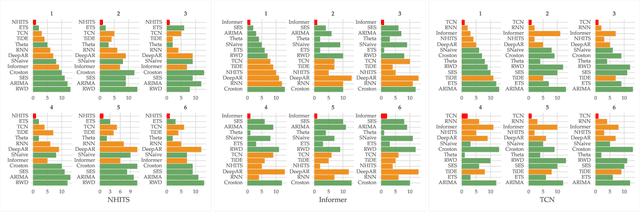

The importance of time series forecasting drives continuous research and the development of new approaches to tackle this problem. Typically, these methods are introduced through empirical studies that frequently claim superior accuracy for the proposed approaches. Nevertheless, concerns are rising about the reliability and generalizability of these results due to limitations in experimental setups. This paper addresses a critical limitation: the number and representativeness of the datasets used. We investigate the impact of dataset selection bias, particularly the practice of cherry-picking datasets, on the performance evaluation of forecasting methods. Through empirical analysis with a diverse set of benchmark datasets, our findings reveal that cherry-picking datasets can significantly distort the perceived performance of methods, often exaggerating their effectiveness. Furthermore, our results demonstrate that by selectively choosing just four datasets - what most studies report - 46% of methods could be deemed best in class, and 77% could rank within the top three. Additionally, recent deep learning-based approaches show high sensitivity to dataset selection, whereas classical methods exhibit greater robustness. Finally, our results indicate that, when empirically validating forecasting algorithms on a subset of the benchmarks, increasing the number of datasets tested from 3 to 6 reduces the risk of incorrectly identifying an algorithm as the best one by approximately 40%. Our study highlights the critical need for comprehensive evaluation frameworks that more accurately reflect real-world scenarios. Adopting such frameworks will ensure the development of robust and reliable forecasting methods.
Multi-output Ensembles for Multi-step Forecasting
Jun 26, 2023This paper studies the application of ensembles composed of multi-output models for multi-step ahead forecasting problems. Dynamic ensembles have been commonly used for forecasting. However, these are typically designed for one-step-ahead tasks. On the other hand, the literature regarding the application of dynamic ensembles for multi-step ahead forecasting is scarce. Moreover, it is not clear how the combination rule is applied across the forecasting horizon. We carried out extensive experiments to analyze the application of dynamic ensembles for multi-step forecasting. We resorted to a case study with 3568 time series and an ensemble of 30 multi-output models. We discovered that dynamic ensembles based on arbitrating and windowing present the best performance according to average rank. Moreover, as the horizon increases, most approaches struggle to outperform a static ensemble that assigns equal weights to all models. The experiments are publicly available in a repository.
Exceedance Probability Forecasting via Regression for Significant Wave Height Forecasting
Jun 20, 2022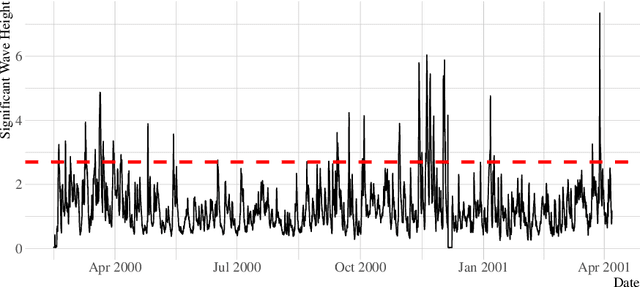
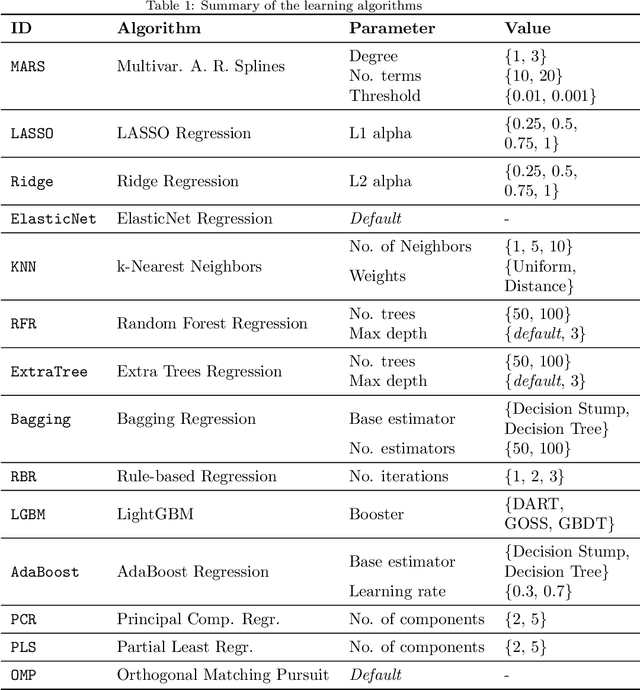
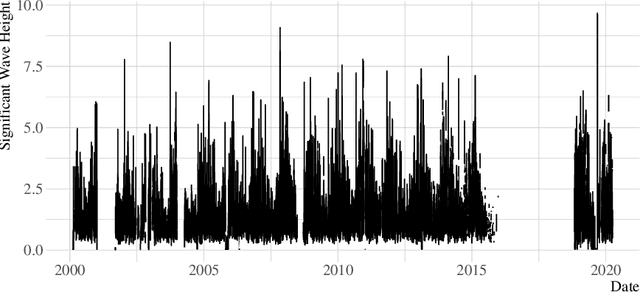
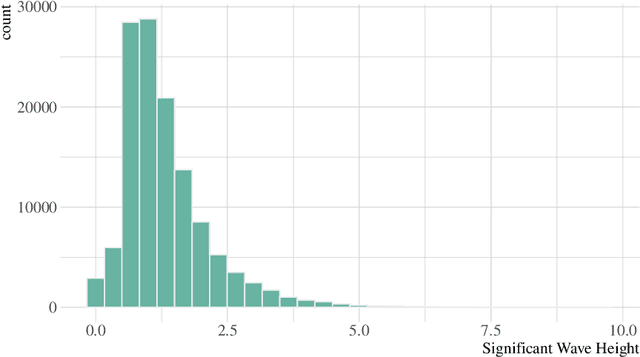
Significant wave height forecasting is a key problem in ocean data analytics. Predicting the significant wave height is crucial for estimating the energy production from waves. Moreover, the timely prediction of large waves is important to ensure the safety of maritime operations, e.g. passage of vessels. We frame the task of predicting extreme values of significant wave height as an exceedance probability forecasting problem. Accordingly, we aim at estimating the probability that the significant wave height will exceed a predefined threshold. This task is usually solved using a probabilistic binary classification model. Instead, we propose a novel approach based on a forecasting model. The method leverages the forecasts for the upcoming observations to estimate the exceedance probability according to the cumulative distribution function. We carried out experiments using data from a buoy placed in the coast of Halifax, Canada. The results suggest that the proposed methodology is better than state-of-the-art approaches for exceedance probability forecasting.
Automated Imbalanced Classification via Layered Learning
May 05, 2022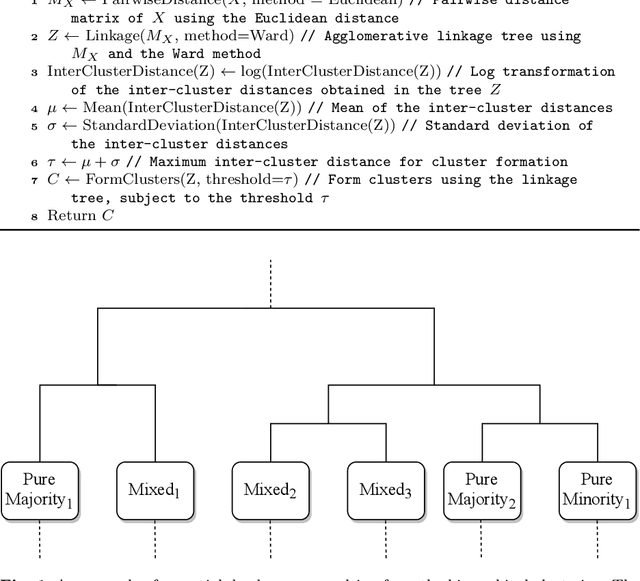
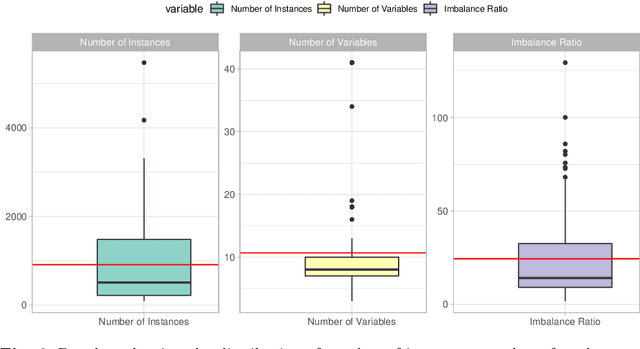

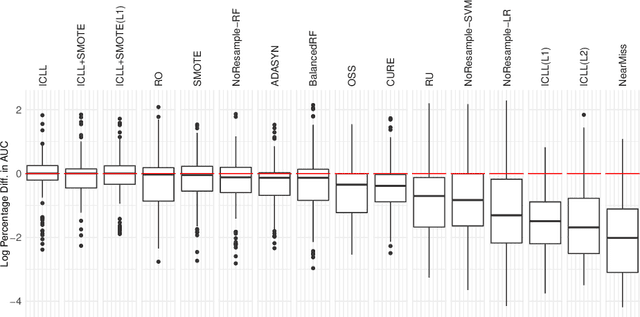
In this paper we address imbalanced binary classification (IBC) tasks. Applying resampling strategies to balance the class distribution of training instances is a common approach to tackle these problems. Many state-of-the-art methods find instances of interest close to the decision boundary to drive the resampling process. However, under-sampling the majority class may potentially lead to important information loss. Over-sampling also may increase the chance of overfitting by propagating the information contained in instances from the minority class. The main contribution of our work is a new method called ICLL for tackling IBC tasks which is not based on resampling training observations. Instead, ICLL follows a layered learning paradigm to model the data in two stages. In the first layer, ICLL learns to distinguish cases close to the decision boundary from cases which are clearly from the majority class, where this dichotomy is defined using a hierarchical clustering analysis. In the subsequent layer, we use instances close to the decision boundary and instances from the minority class to solve the original predictive task. A second contribution of our work is the automatic definition of the layers which comprise the layered learning strategy using a hierarchical clustering model. This is a relevant discovery as this process is usually performed manually according to domain knowledge. We carried out extensive experiments using 100 benchmark data sets. The results show that the proposed method leads to a better performance relatively to several state-of-the-art methods for IBC.
Beyond Average Performance -- exploring regions of deviating performance for black box classification models
Sep 16, 2021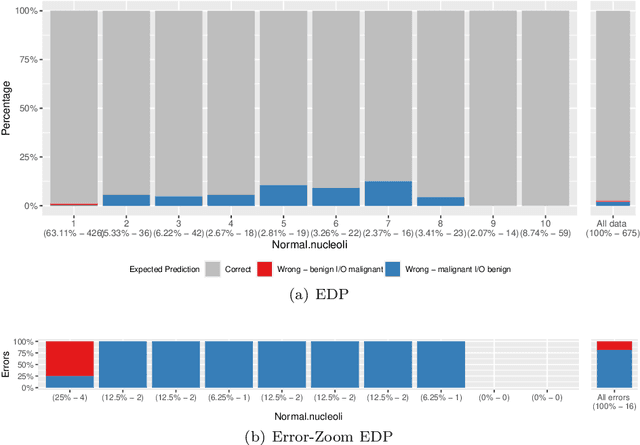
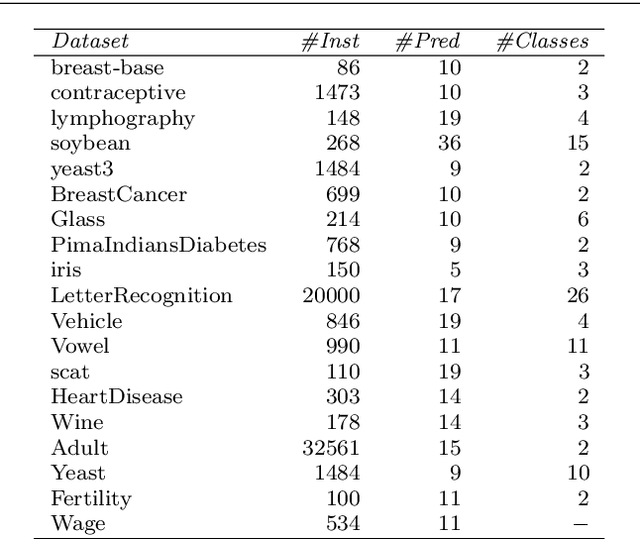

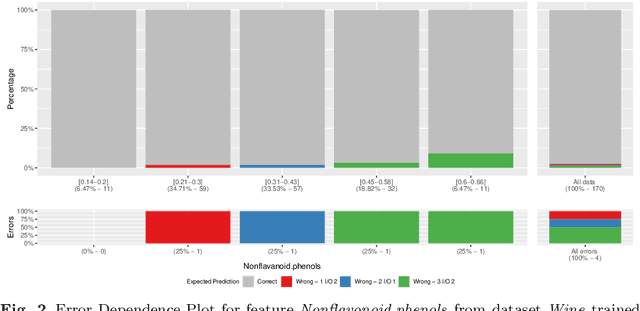
Machine learning models are becoming increasingly popular in different types of settings. This is mainly caused by their ability to achieve a level of predictive performance that is hard to match by human experts in this new era of big data. With this usage growth comes an increase of the requirements for accountability and understanding of the models' predictions. However, the degree of sophistication of the most successful models (e.g. ensembles, deep learning) is becoming a large obstacle to this endeavour as these models are essentially black boxes. In this paper we describe two general approaches that can be used to provide interpretable descriptions of the expected performance of any black box classification model. These approaches are of high practical relevance as they provide means to uncover and describe in an interpretable way situations where the models are expected to have a performance that deviates significantly from their average behaviour. This may be of critical relevance for applications where costly decisions are driven by the predictions of the models, as it can be used to warn end users against the usage of the models in some specific cases.
Model Compression for Dynamic Forecast Combination
Apr 05, 2021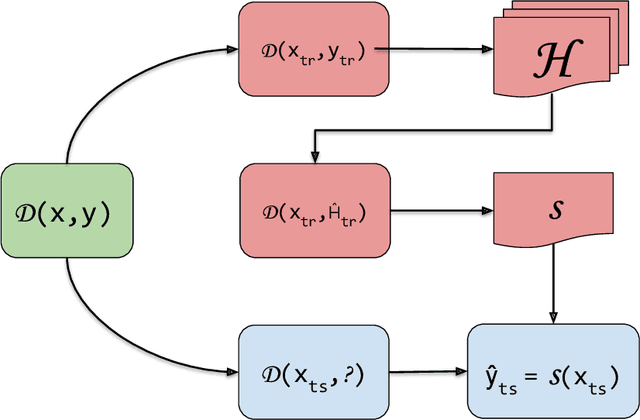
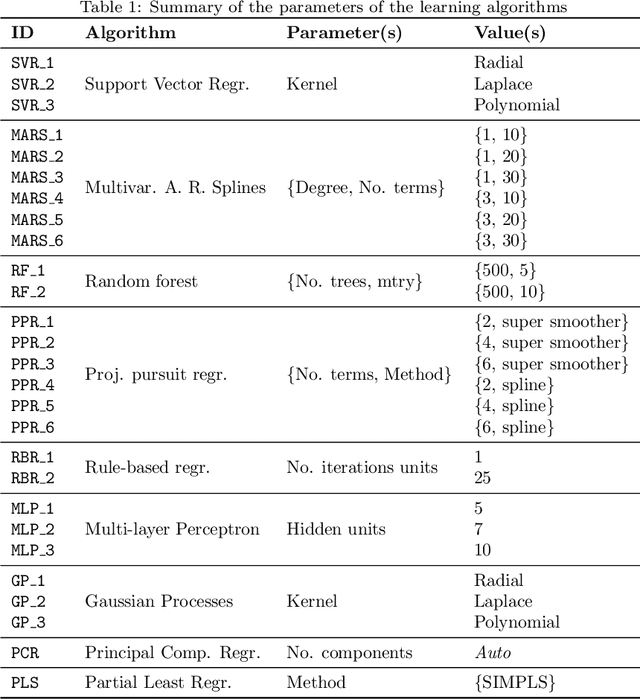
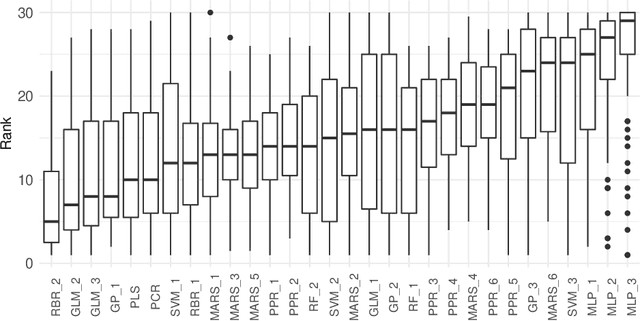
The predictive advantage of combining several different predictive models is widely accepted. Particularly in time series forecasting problems, this combination is often dynamic to cope with potential non-stationary sources of variation present in the data. Despite their superior predictive performance, ensemble methods entail two main limitations: high computational costs and lack of transparency. These issues often preclude the deployment of such approaches, in favour of simpler yet more efficient and reliable ones. In this paper, we leverage the idea of model compression to address this problem in time series forecasting tasks. Model compression approaches have been mostly unexplored for forecasting. Their application in time series is challenging due to the evolving nature of the data. Further, while the literature focuses on neural networks, we apply model compression to distinct types of methods. In an extensive set of experiments, we show that compressing dynamic forecasting ensembles into an individual model leads to a comparable predictive performance and a drastic reduction in computational costs. Further, the compressed individual model with best average rank is a rule-based regression model. Thus, model compression also leads to benefits in terms of model interpretability. The experiments carried in this paper are fully reproducible.
Model Selection for Time Series Forecasting: Empirical Analysis of Different Estimators
Apr 01, 2021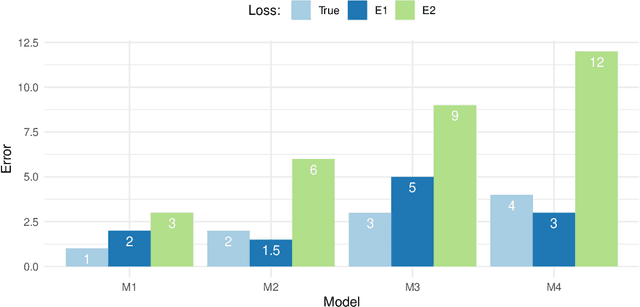
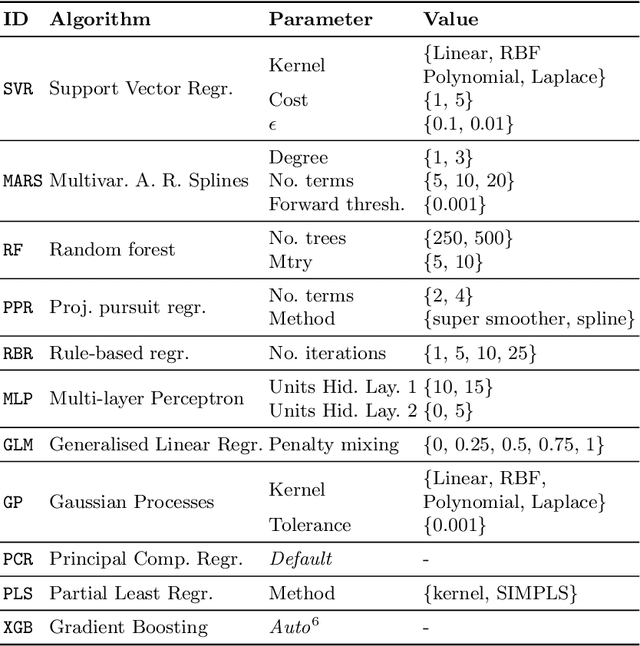
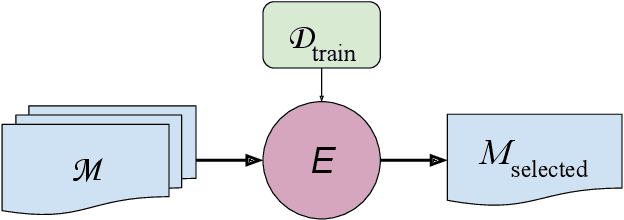
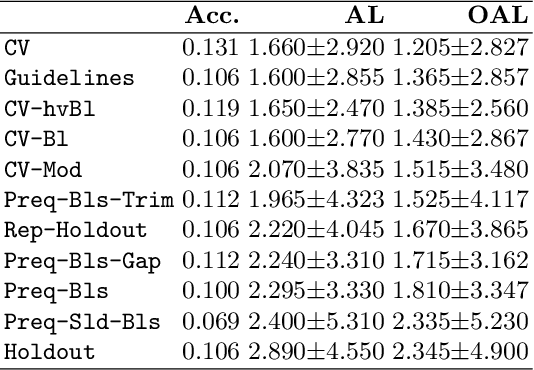
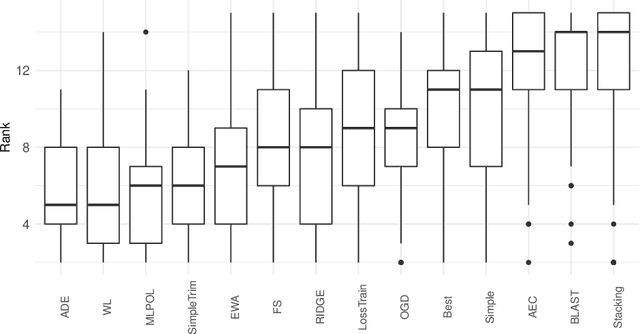
Evaluating predictive models is a crucial task in predictive analytics. This process is especially challenging with time series data where the observations show temporal dependencies. Several studies have analysed how different performance estimation methods compare with each other for approximating the true loss incurred by a given forecasting model. However, these studies do not address how the estimators behave for model selection: the ability to select the best solution among a set of alternatives. We address this issue and compare a set of estimation methods for model selection in time series forecasting tasks. We attempt to answer two main questions: (i) how often is the best possible model selected by the estimators; and (ii) what is the performance loss when it does not. We empirically found that the accuracy of the estimators for selecting the best solution is low, and the overall forecasting performance loss associated with the model selection process ranges from 1.2% to 2.3%. We also discovered that some factors, such as the sample size, are important in the relative performance of the estimators.
A Survey on Spatio-temporal Data Analytics Systems
Mar 17, 2021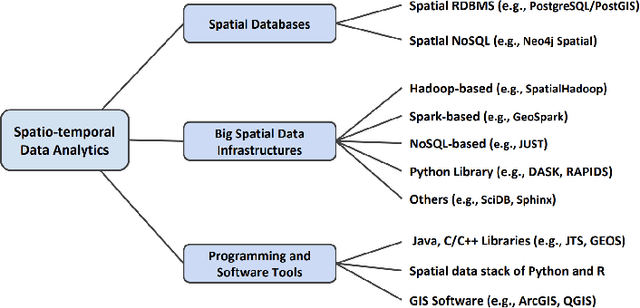
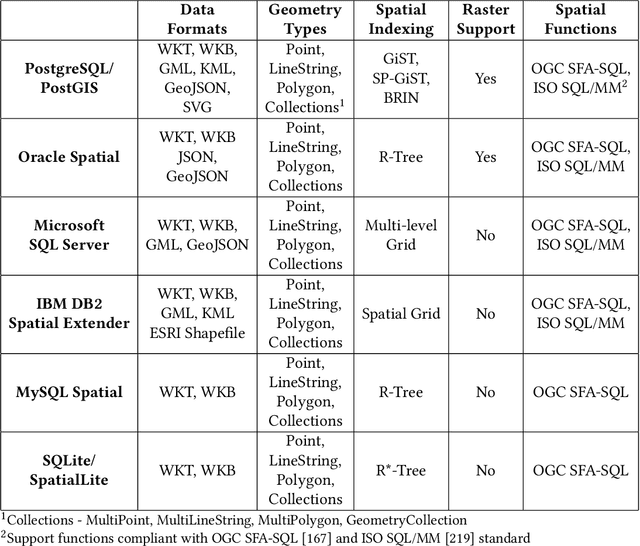
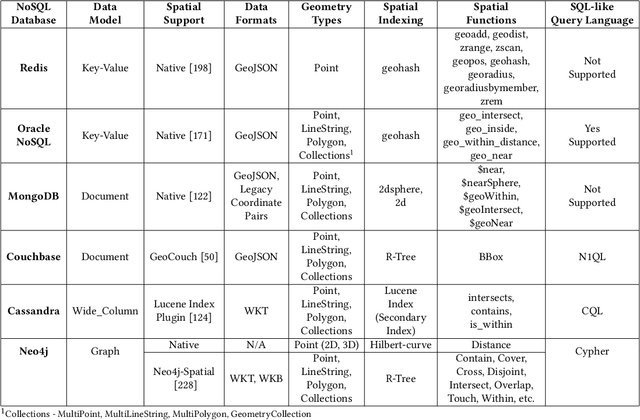
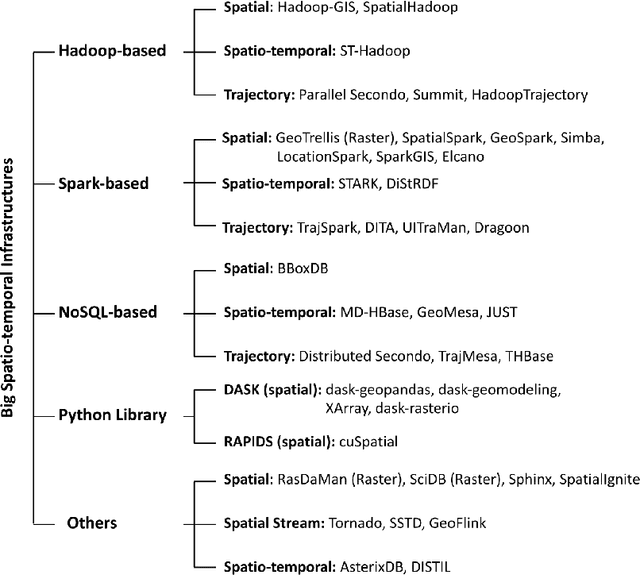
Due to the surge of spatio-temporal data volume, the popularity of location-based services and applications, and the importance of extracted knowledge from spatio-temporal data to solve a wide range of real-world problems, a plethora of research and development work has been done in the area of spatial and spatio-temporal data analytics in the past decade. The main goal of existing works was to develop algorithms and technologies to capture, store, manage, analyze, and visualize spatial or spatio-temporal data. The researchers have contributed either by adding spatio-temporal support with existing systems, by developing a new system from scratch for processing spatio-temporal data, or by implementing algorithms for mining spatio-temporal data. The existing ecosystem of spatial and spatio-temporal data analytics can be categorized into three groups, (1) spatial databases (SQL and NoSQL), (2) big spatio-temporal data processing infrastructures, and (3) programming languages and software tools for processing spatio-temporal data. Since existing surveys mostly investigated big data infrastructures for processing spatial data, this survey has explored the whole ecosystem of spatial and spatio-temporal analytics along with an up-to-date review of big spatial data processing systems. This survey also portrays the importance and future of spatial and spatio-temporal data analytics.
STUDD: A Student-Teacher Method for Unsupervised Concept Drift Detection
Mar 01, 2021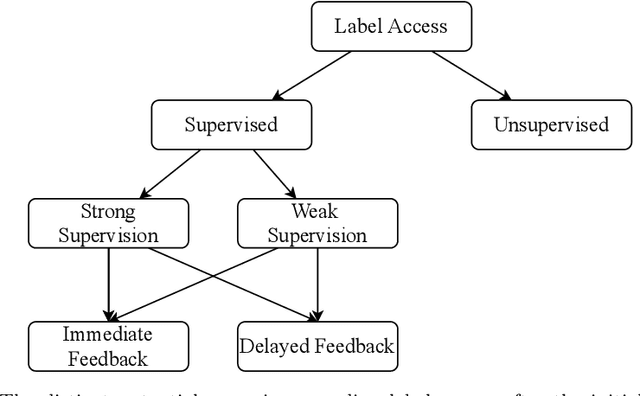
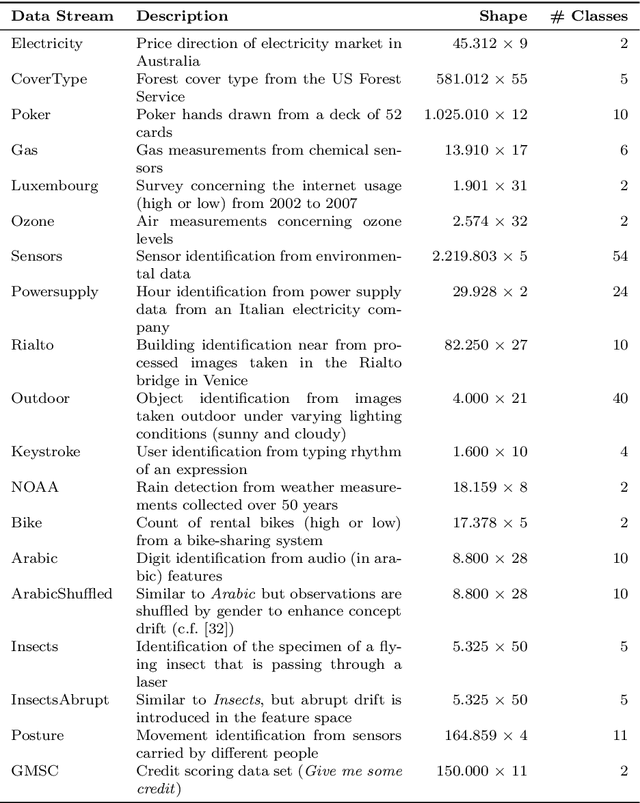

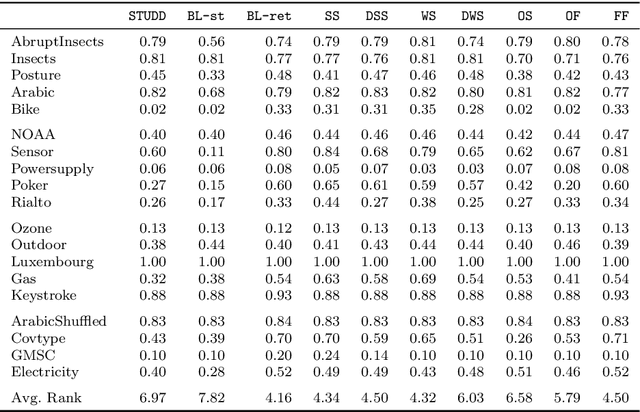
Concept drift detection is a crucial task in data stream evolving environments. Most of state of the art approaches designed to tackle this problem monitor the loss of predictive models. However, this approach falls short in many real-world scenarios, where the true labels are not readily available to compute the loss. In this context, there is increasing attention to approaches that perform concept drift detection in an unsupervised manner, i.e., without access to the true labels. We propose a novel approach to unsupervised concept drift detection based on a student-teacher learning paradigm. Essentially, we create an auxiliary model (student) to mimic the behaviour of the primary model (teacher). At run-time, our approach is to use the teacher for predicting new instances and monitoring the mimicking loss of the student for concept drift detection. In a set of experiments using 19 data streams, we show that the proposed approach can detect concept drift and present a competitive behaviour relative to the state of the art approaches.