 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN-BEATS-MOE: N-BEATS with a Mixture-of-Experts Layer for Heterogeneous Time Series Forecasting
Aug 10, 2025



Deep learning approaches are increasingly relevant for time series forecasting tasks. Methods such as N-BEATS, which is built on stacks of multilayer perceptrons (MLPs) blocks, have achieved state-of-the-art results on benchmark datasets and competitions. N-BEATS is also more interpretable relative to other deep learning approaches, as it decomposes forecasts into different time series components, such as trend and seasonality. In this work, we present N-BEATS-MOE, an extension of N-BEATS based on a Mixture-of-Experts (MoE) layer. N-BEATS-MOE employs a dynamic block weighting strategy based on a gating network which allows the model to better adapt to the characteristics of each time series. We also hypothesize that the gating mechanism provides additional interpretability by identifying which expert is most relevant for each series. We evaluate our method across 12 benchmark datasets against several approaches, achieving consistent improvements on several datasets, especially those composed of heterogeneous time series.
L-GTA: Latent Generative Modeling for Time Series Augmentation
Jul 31, 2025Data augmentation is gaining importance across various aspects of time series analysis, from forecasting to classification and anomaly detection tasks. We introduce the Latent Generative Transformer Augmentation (L-GTA) model, a generative approach using a transformer-based variational recurrent autoencoder. This model uses controlled transformations within the latent space of the model to generate new time series that preserve the intrinsic properties of the original dataset. L-GTA enables the application of diverse transformations, ranging from simple jittering to magnitude warping, and combining these basic transformations to generate more complex synthetic time series datasets. Our evaluation of several real-world datasets demonstrates the ability of L-GTA to produce more reliable, consistent, and controllable augmented data. This translates into significant improvements in predictive accuracy and similarity measures compared to direct transformation methods.
ModelRadar: Aspect-based Forecast Evaluation
Mar 31, 2025Accurate evaluation of forecasting models is essential for ensuring reliable predictions. Current practices for evaluating and comparing forecasting models focus on summarising performance into a single score, using metrics such as SMAPE. While convenient, averaging performance over all samples dilutes relevant information about model behavior under varying conditions. This limitation is especially problematic for time series forecasting, where multiple layers of averaging--across time steps, horizons, and multiple time series in a dataset--can mask relevant performance variations. We address this limitation by proposing ModelRadar, a framework for evaluating univariate time series forecasting models across multiple aspects, such as stationarity, presence of anomalies, or forecasting horizons. We demonstrate the advantages of this framework by comparing 24 forecasting methods, including classical approaches and different machine learning algorithms. NHITS, a state-of-the-art neural network architecture, performs best overall but its superiority varies with forecasting conditions. For instance, concerning the forecasting horizon, we found that NHITS (and also other neural networks) only outperforms classical approaches for multi-step ahead forecasting. Another relevant insight is that classical approaches such as ETS or Theta are notably more robust in the presence of anomalies. These and other findings highlight the importance of aspect-based model evaluation for both practitioners and researchers. ModelRadar is available as a Python package.
Cherry-Picking in Time Series Forecasting: How to Select Datasets to Make Your Model Shine
Dec 19, 2024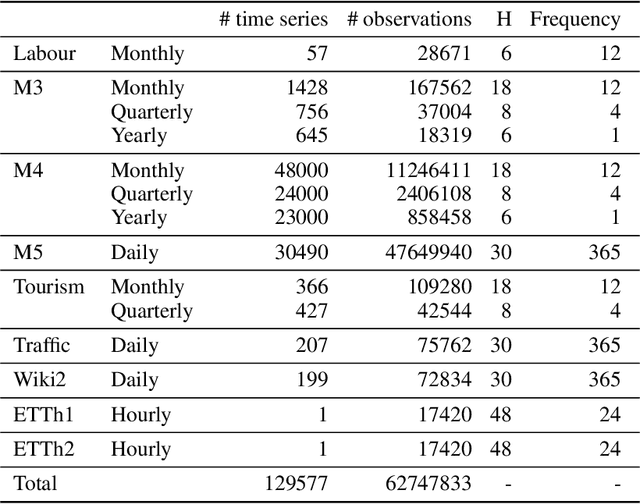
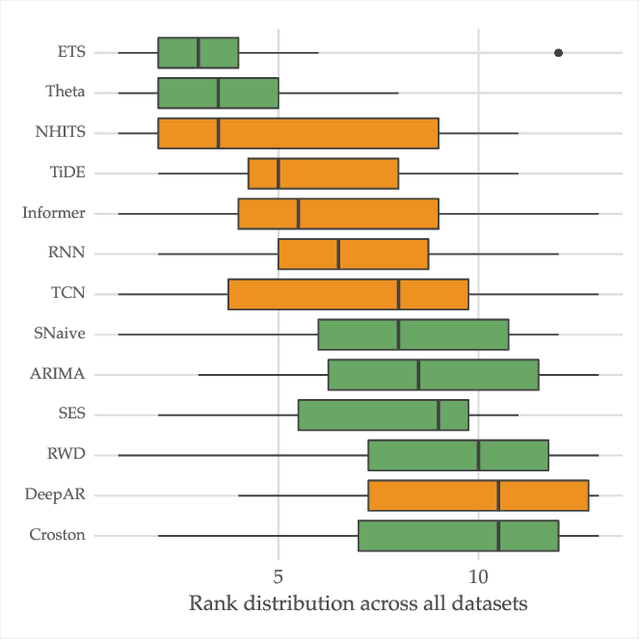
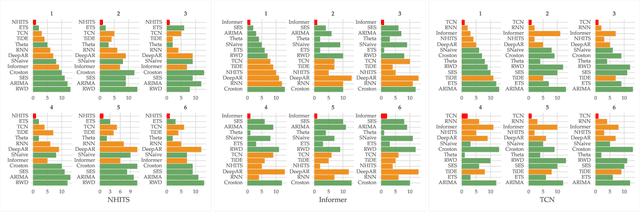

The importance of time series forecasting drives continuous research and the development of new approaches to tackle this problem. Typically, these methods are introduced through empirical studies that frequently claim superior accuracy for the proposed approaches. Nevertheless, concerns are rising about the reliability and generalizability of these results due to limitations in experimental setups. This paper addresses a critical limitation: the number and representativeness of the datasets used. We investigate the impact of dataset selection bias, particularly the practice of cherry-picking datasets, on the performance evaluation of forecasting methods. Through empirical analysis with a diverse set of benchmark datasets, our findings reveal that cherry-picking datasets can significantly distort the perceived performance of methods, often exaggerating their effectiveness. Furthermore, our results demonstrate that by selectively choosing just four datasets - what most studies report - 46% of methods could be deemed best in class, and 77% could rank within the top three. Additionally, recent deep learning-based approaches show high sensitivity to dataset selection, whereas classical methods exhibit greater robustness. Finally, our results indicate that, when empirically validating forecasting algorithms on a subset of the benchmarks, increasing the number of datasets tested from 3 to 6 reduces the risk of incorrectly identifying an algorithm as the best one by approximately 40%. Our study highlights the critical need for comprehensive evaluation frameworks that more accurately reflect real-world scenarios. Adopting such frameworks will ensure the development of robust and reliable forecasting methods.
RHiOTS: A Framework for Evaluating Hierarchical Time Series Forecasting Algorithms
Aug 06, 2024We introduce the Robustness of Hierarchically Organized Time Series (RHiOTS) framework, designed to assess the robustness of hierarchical time series forecasting models and algorithms on real-world datasets. Hierarchical time series, where lower-level forecasts must sum to upper-level ones, are prevalent in various contexts, such as retail sales across countries. Current empirical evaluations of forecasting methods are often limited to a small set of benchmark datasets, offering a narrow view of algorithm behavior. RHiOTS addresses this gap by systematically altering existing datasets and modifying the characteristics of individual series and their interrelations. It uses a set of parameterizable transformations to simulate those changes in the data distribution. Additionally, RHiOTS incorporates an innovative visualization component, turning complex, multidimensional robustness evaluation results into intuitive, easily interpretable visuals. This approach allows an in-depth analysis of algorithm and model behavior under diverse conditions. We illustrate the use of RHiOTS by analyzing the predictive performance of several algorithms. Our findings show that traditional statistical methods are more robust than state-of-the-art deep learning algorithms, except when the transformation effect is highly disruptive. Furthermore, we found no significant differences in the robustness of the algorithms when applying specific reconciliation methods, such as MinT. RHiOTS provides researchers with a comprehensive tool for understanding the nuanced behavior of forecasting algorithms, offering a more reliable basis for selecting the most appropriate method for a given problem.
Forecasting with Deep Learning: Beyond Average of Average of Average Performance
Jun 24, 2024



Accurate evaluation of forecasting models is essential for ensuring reliable predictions. Current practices for evaluating and comparing forecasting models focus on summarising performance into a single score, using metrics such as SMAPE. We hypothesize that averaging performance over all samples dilutes relevant information about the relative performance of models. Particularly, conditions in which this relative performance is different than the overall accuracy. We address this limitation by proposing a novel framework for evaluating univariate time series forecasting models from multiple perspectives, such as one-step ahead forecasting versus multi-step ahead forecasting. We show the advantages of this framework by comparing a state-of-the-art deep learning approach with classical forecasting techniques. While classical methods (e.g. ARIMA) are long-standing approaches to forecasting, deep neural networks (e.g. NHITS) have recently shown state-of-the-art forecasting performance in benchmark datasets. We conducted extensive experiments that show NHITS generally performs best, but its superiority varies with forecasting conditions. For instance, concerning the forecasting horizon, NHITS only outperforms classical approaches for multi-step ahead forecasting. Another relevant insight is that, when dealing with anomalies, NHITS is outperformed by methods such as Theta. These findings highlight the importance of aspect-based model evaluation.
Optimal Combination Forecasts on Retail Multi-Dimensional Sales Data
Mar 22, 2019
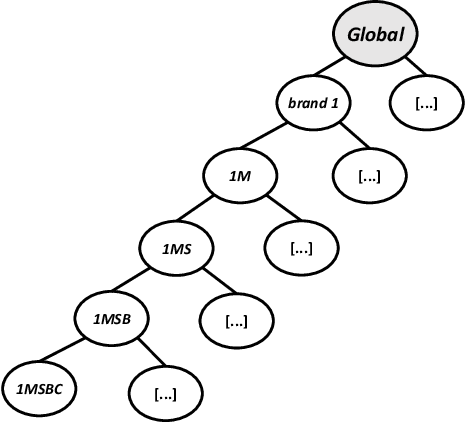

Time series data in the retail world are particularly rich in terms of dimensionality, and these dimensions can be aggregated in groups or hierarchies. Valuable information is nested in these complex structures, which helps to predict the aggregated time series data. From a portfolio of brands under HUUB's monitoring, we selected two to explore their sales behaviour, leveraging the grouping properties of their product structure. Using statistical models, namely SARIMA, to forecast each level of the hierarchy, an optimal combination approach was used to generate more consistent forecasts in the higher levels. Our results show that the proposed methods can indeed capture nested information in the more granular series, helping to improve the forecast accuracy of the aggregated series. The Weighted Least Squares (WLS) method surpasses all other methods proposed in the study, including the Minimum Trace (MinT) reconciliation.