 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Transformer Placement in Variational Autoencoders for Tabular Data Generation
Jan 28, 2026Tabular data remains a challenging domain for generative models. In particular, the standard Variational Autoencoder (VAE) architecture, typically composed of multilayer perceptrons, struggles to model relationships between features, especially when handling mixed data types. In contrast, Transformers, through their attention mechanism, are better suited for capturing complex feature interactions. In this paper, we empirically investigate the impact of integrating Transformers into different components of a VAE. We conduct experiments on 57 datasets from the OpenML CC18 suite and draw two main conclusions. First, results indicate that positioning Transformers to leverage latent and decoder representations leads to a trade-off between fidelity and diversity. Second, we observe a high similarity between consecutive blocks of a Transformer in all components. In particular, in the decoder, the relationship between the input and output of a Transformer is approximately linear.
Grasynda: Graph-based Synthetic Time Series Generation
Jan 27, 2026Data augmentation is a crucial tool in time series forecasting, especially for deep learning architectures that require a large training sample size to generalize effectively. However, extensive datasets are not always available in real-world scenarios. Although many data augmentation methods exist, their limitations include the use of transformations that do not adequately preserve data properties. This paper introduces Grasynda, a novel graph-based approach for synthetic time series generation that: (1) converts univariate time series into a network structure using a graph representation, where each state is a node and each transition is represented as a directed edge; and (2) encodes their temporal dynamics in a transition probability matrix. We performed an extensive evaluation of Grasynda as a data augmentation method for time series forecasting. We use three neural network variations on six benchmark datasets. The results indicate that Grasynda consistently outperforms other time series data augmentation methods, including ones used in state-of-the-art time series foundation models. The method and all experiments are publicly available.
SPATA: Systematic Pattern Analysis for Detailed and Transparent Data Cards
Sep 30, 2025



Due to the susceptibility of Artificial Intelligence (AI) to data perturbations and adversarial examples, it is crucial to perform a thorough robustness evaluation before any Machine Learning (ML) model is deployed. However, examining a model's decision boundaries and identifying potential vulnerabilities typically requires access to the training and testing datasets, which may pose risks to data privacy and confidentiality. To improve transparency in organizations that handle confidential data or manage critical infrastructure, it is essential to allow external verification and validation of AI without the disclosure of private datasets. This paper presents Systematic Pattern Analysis (SPATA), a deterministic method that converts any tabular dataset to a domain-independent representation of its statistical patterns, to provide more detailed and transparent data cards. SPATA computes the projection of each data instance into a discrete space where they can be analyzed and compared, without risking data leakage. These projected datasets can be reliably used for the evaluation of how different features affect ML model robustness and for the generation of interpretable explanations of their behavior, contributing to more trustworthy AI.
L-GTA: Latent Generative Modeling for Time Series Augmentation
Jul 31, 2025Data augmentation is gaining importance across various aspects of time series analysis, from forecasting to classification and anomaly detection tasks. We introduce the Latent Generative Transformer Augmentation (L-GTA) model, a generative approach using a transformer-based variational recurrent autoencoder. This model uses controlled transformations within the latent space of the model to generate new time series that preserve the intrinsic properties of the original dataset. L-GTA enables the application of diverse transformations, ranging from simple jittering to magnitude warping, and combining these basic transformations to generate more complex synthetic time series datasets. Our evaluation of several real-world datasets demonstrates the ability of L-GTA to produce more reliable, consistent, and controllable augmented data. This translates into significant improvements in predictive accuracy and similarity measures compared to direct transformation methods.
Generating Large Semi-Synthetic Graphs of Any Size
Jul 02, 2025Graph generation is an important area in network science. Traditional approaches focus on replicating specific properties of real-world graphs, such as small diameters or power-law degree distributions. Recent advancements in deep learning, particularly with Graph Neural Networks, have enabled data-driven methods to learn and generate graphs without relying on predefined structural properties. Despite these advances, current models are limited by their reliance on node IDs, which restricts their ability to generate graphs larger than the input graph and ignores node attributes. To address these challenges, we propose Latent Graph Sampling Generation (LGSG), a novel framework that leverages diffusion models and node embeddings to generate graphs of varying sizes without retraining. The framework eliminates the dependency on node IDs and captures the distribution of node embeddings and subgraph structures, enabling scalable and flexible graph generation. Experimental results show that LGSG performs on par with baseline models for standard metrics while outperforming them in overlooked ones, such as the tendency of nodes to form clusters. Additionally, it maintains consistent structural characteristics across graphs of different sizes, demonstrating robustness and scalability.
ModelRadar: Aspect-based Forecast Evaluation
Mar 31, 2025Accurate evaluation of forecasting models is essential for ensuring reliable predictions. Current practices for evaluating and comparing forecasting models focus on summarising performance into a single score, using metrics such as SMAPE. While convenient, averaging performance over all samples dilutes relevant information about model behavior under varying conditions. This limitation is especially problematic for time series forecasting, where multiple layers of averaging--across time steps, horizons, and multiple time series in a dataset--can mask relevant performance variations. We address this limitation by proposing ModelRadar, a framework for evaluating univariate time series forecasting models across multiple aspects, such as stationarity, presence of anomalies, or forecasting horizons. We demonstrate the advantages of this framework by comparing 24 forecasting methods, including classical approaches and different machine learning algorithms. NHITS, a state-of-the-art neural network architecture, performs best overall but its superiority varies with forecasting conditions. For instance, concerning the forecasting horizon, we found that NHITS (and also other neural networks) only outperforms classical approaches for multi-step ahead forecasting. Another relevant insight is that classical approaches such as ETS or Theta are notably more robust in the presence of anomalies. These and other findings highlight the importance of aspect-based model evaluation for both practitioners and researchers. ModelRadar is available as a Python package.
Cherry-Picking in Time Series Forecasting: How to Select Datasets to Make Your Model Shine
Dec 19, 2024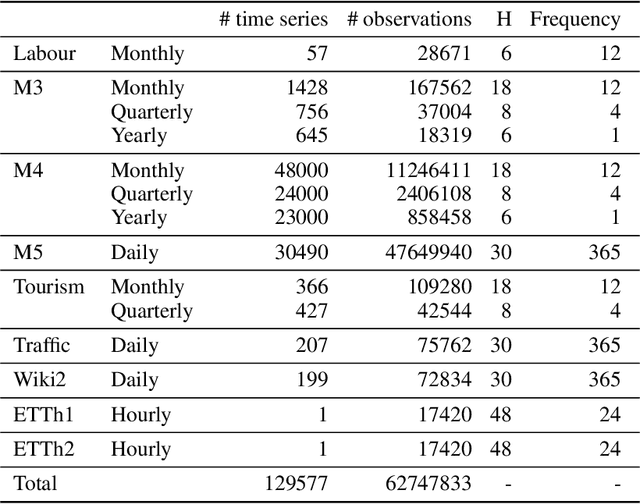
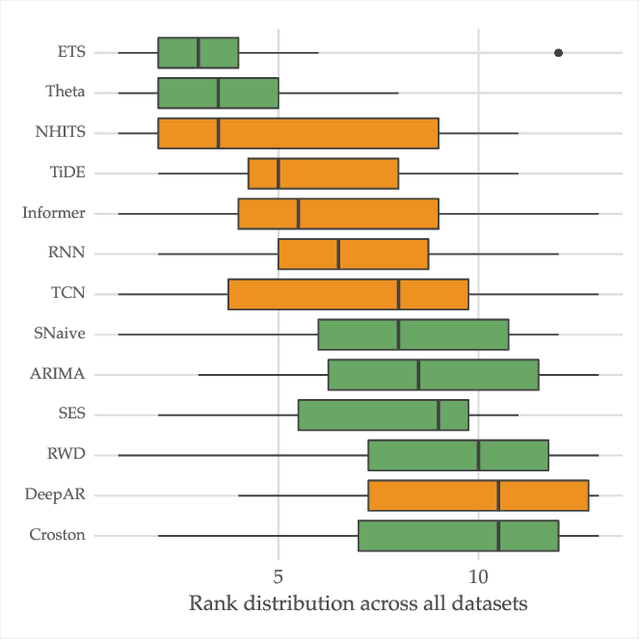
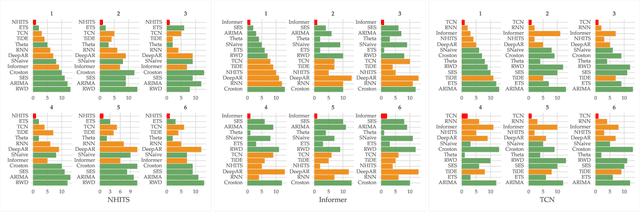

The importance of time series forecasting drives continuous research and the development of new approaches to tackle this problem. Typically, these methods are introduced through empirical studies that frequently claim superior accuracy for the proposed approaches. Nevertheless, concerns are rising about the reliability and generalizability of these results due to limitations in experimental setups. This paper addresses a critical limitation: the number and representativeness of the datasets used. We investigate the impact of dataset selection bias, particularly the practice of cherry-picking datasets, on the performance evaluation of forecasting methods. Through empirical analysis with a diverse set of benchmark datasets, our findings reveal that cherry-picking datasets can significantly distort the perceived performance of methods, often exaggerating their effectiveness. Furthermore, our results demonstrate that by selectively choosing just four datasets - what most studies report - 46% of methods could be deemed best in class, and 77% could rank within the top three. Additionally, recent deep learning-based approaches show high sensitivity to dataset selection, whereas classical methods exhibit greater robustness. Finally, our results indicate that, when empirically validating forecasting algorithms on a subset of the benchmarks, increasing the number of datasets tested from 3 to 6 reduces the risk of incorrectly identifying an algorithm as the best one by approximately 40%. Our study highlights the critical need for comprehensive evaluation frameworks that more accurately reflect real-world scenarios. Adopting such frameworks will ensure the development of robust and reliable forecasting methods.
Tabular data generation with tensor contraction layers and transformers
Dec 06, 2024



Generative modeling for tabular data has recently gained significant attention in the Deep Learning domain. Its objective is to estimate the underlying distribution of the data. However, estimating the underlying distribution of tabular data has its unique challenges. Specifically, this data modality is composed of mixed types of features, making it a non-trivial task for a model to learn intra-relationships between them. One approach to address mixture is to embed each feature into a continuous matrix via tokenization, while a solution to capture intra-relationships between variables is via the transformer architecture. In this work, we empirically investigate the potential of using embedding representations on tabular data generation, utilizing tensor contraction layers and transformers to model the underlying distribution of tabular data within Variational Autoencoders. Specifically, we compare four architectural approaches: a baseline VAE model, two variants that focus on tensor contraction layers and transformers respectively, and a hybrid model that integrates both techniques. Our empirical study, conducted across multiple datasets from the OpenML CC18 suite, compares models over density estimation and Machine Learning efficiency metrics. The main takeaway from our results is that leveraging embedding representations with the help of tensor contraction layers improves density estimation metrics, albeit maintaining competitive performance in terms of machine learning efficiency.
Fair-OBNC: Correcting Label Noise for Fairer Datasets
Oct 08, 2024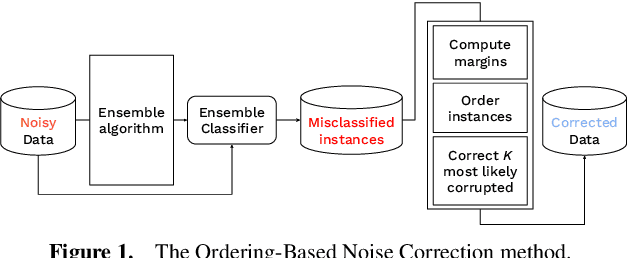
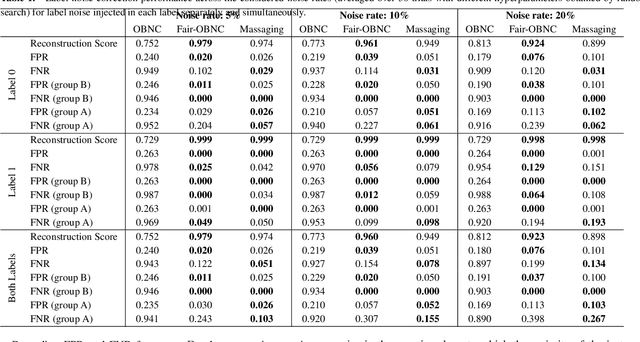
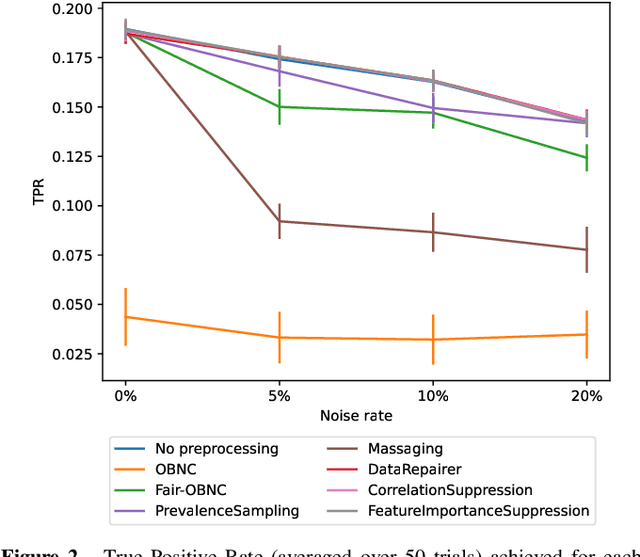
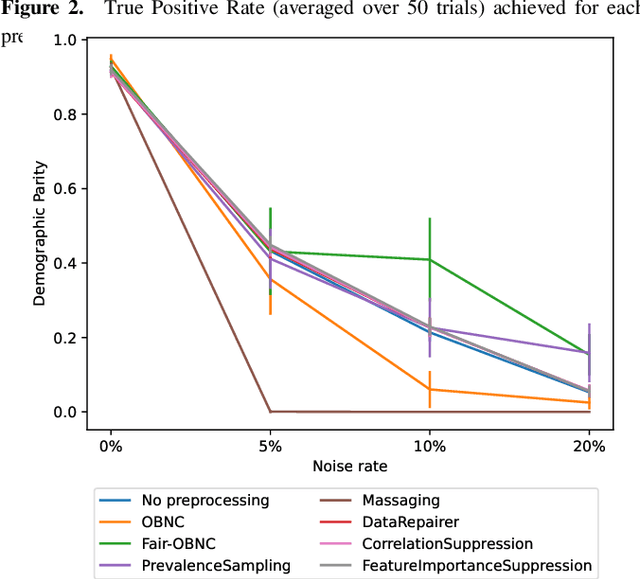
Data used by automated decision-making systems, such as Machine Learning models, often reflects discriminatory behavior that occurred in the past. These biases in the training data are sometimes related to label noise, such as in COMPAS, where more African-American offenders are wrongly labeled as having a higher risk of recidivism when compared to their White counterparts. Models trained on such biased data may perpetuate or even aggravate the biases with respect to sensitive information, such as gender, race, or age. However, while multiple label noise correction approaches are available in the literature, these focus on model performance exclusively. In this work, we propose Fair-OBNC, a label noise correction method with fairness considerations, to produce training datasets with measurable demographic parity. The presented method adapts Ordering-Based Noise Correction, with an adjusted criterion of ordering, based both on the margin of error of an ensemble, and the potential increase in the observed demographic parity of the dataset. We evaluate Fair-OBNC against other different pre-processing techniques, under different scenarios of controlled label noise. Our results show that the proposed method is the overall better alternative within the pool of label correction methods, being capable of attaining better reconstructions of the original labels. Models trained in the corrected data have an increase, on average, of 150% in demographic parity, when compared to models trained in data with noisy labels, across the considered levels of label noise.
RIFF: Inducing Rules for Fraud Detection from Decision Trees
Aug 23, 2024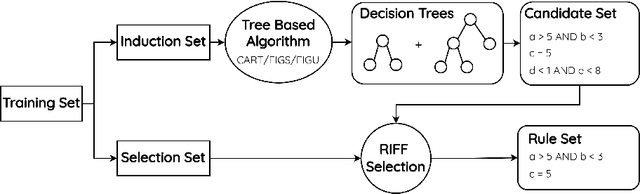

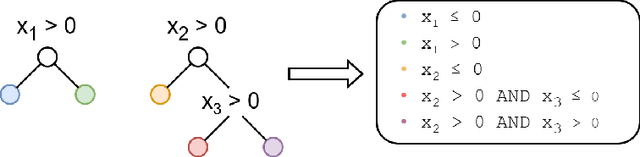
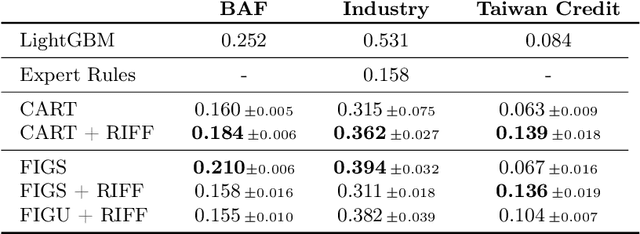
Financial fraud is the cause of multi-billion dollar losses annually. Traditionally, fraud detection systems rely on rules due to their transparency and interpretability, key features in domains where decisions need to be explained. However, rule systems require significant input from domain experts to create and tune, an issue that rule induction algorithms attempt to mitigate by inferring rules directly from data. We explore the application of these algorithms to fraud detection, where rule systems are constrained to have a low false positive rate (FPR) or alert rate, by proposing RIFF, a rule induction algorithm that distills a low FPR rule set directly from decision trees. Our experiments show that the induced rules are often able to maintain or improve performance of the original models for low FPR tasks, while substantially reducing their complexity and outperforming rules hand-tuned by experts.