 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLag Selection for Univariate Time Series Forecasting using Deep Learning: An Empirical Study
Paper and Code
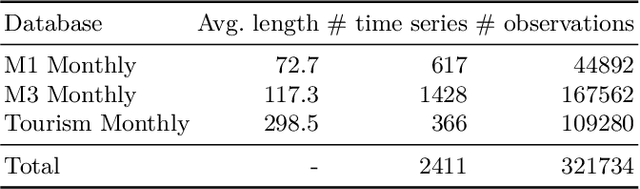
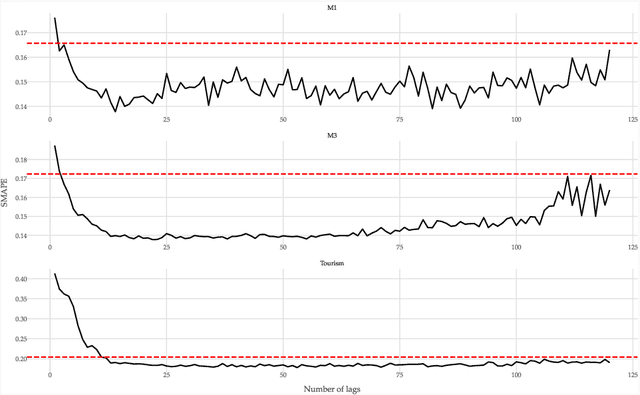


Most forecasting methods use recent past observations (lags) to model the future values of univariate time series. Selecting an adequate number of lags is important for training accurate forecasting models. Several approaches and heuristics have been devised to solve this task. However, there is no consensus about what the best approach is. Besides, lag selection procedures have been developed based on local models and classical forecasting techniques such as ARIMA. We bridge this gap in the literature by carrying out an extensive empirical analysis of different lag selection methods. We focus on deep learning methods trained in a global approach, i.e., on datasets comprising multiple univariate time series. The experiments were carried out using three benchmark databases that contain a total of 2411 univariate time series. The results indicate that the lag size is a relevant parameter for accurate forecasts. In particular, excessively small or excessively large lag sizes have a considerable negative impact on forecasting performance. Cross-validation approaches show the best performance for lag selection, but this performance is comparable with simple heuristics.