 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Transformer Placement in Variational Autoencoders for Tabular Data Generation
Jan 28, 2026Tabular data remains a challenging domain for generative models. In particular, the standard Variational Autoencoder (VAE) architecture, typically composed of multilayer perceptrons, struggles to model relationships between features, especially when handling mixed data types. In contrast, Transformers, through their attention mechanism, are better suited for capturing complex feature interactions. In this paper, we empirically investigate the impact of integrating Transformers into different components of a VAE. We conduct experiments on 57 datasets from the OpenML CC18 suite and draw two main conclusions. First, results indicate that positioning Transformers to leverage latent and decoder representations leads to a trade-off between fidelity and diversity. Second, we observe a high similarity between consecutive blocks of a Transformer in all components. In particular, in the decoder, the relationship between the input and output of a Transformer is approximately linear.
Tabular data generation with tensor contraction layers and transformers
Dec 06, 2024



Generative modeling for tabular data has recently gained significant attention in the Deep Learning domain. Its objective is to estimate the underlying distribution of the data. However, estimating the underlying distribution of tabular data has its unique challenges. Specifically, this data modality is composed of mixed types of features, making it a non-trivial task for a model to learn intra-relationships between them. One approach to address mixture is to embed each feature into a continuous matrix via tokenization, while a solution to capture intra-relationships between variables is via the transformer architecture. In this work, we empirically investigate the potential of using embedding representations on tabular data generation, utilizing tensor contraction layers and transformers to model the underlying distribution of tabular data within Variational Autoencoders. Specifically, we compare four architectural approaches: a baseline VAE model, two variants that focus on tensor contraction layers and transformers respectively, and a hybrid model that integrates both techniques. Our empirical study, conducted across multiple datasets from the OpenML CC18 suite, compares models over density estimation and Machine Learning efficiency metrics. The main takeaway from our results is that leveraging embedding representations with the help of tensor contraction layers improves density estimation metrics, albeit maintaining competitive performance in terms of machine learning efficiency.
Finding Patterns in Ambiguity: Interpretable Stress Testing in the Decision~Boundary
Aug 12, 2024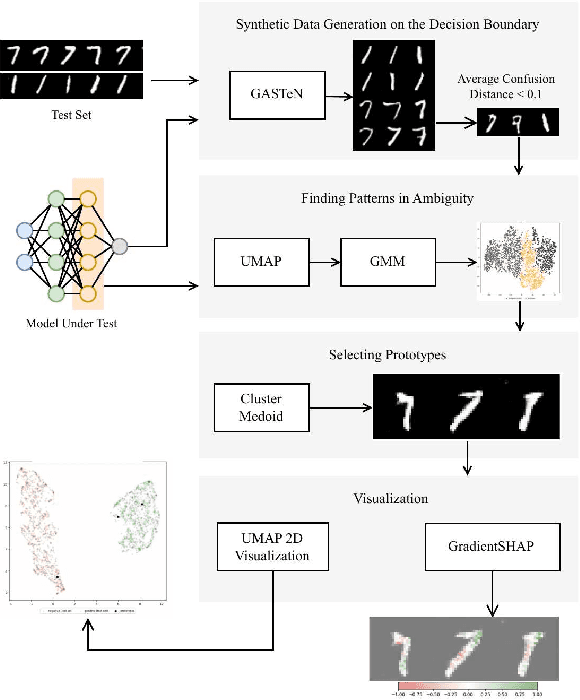
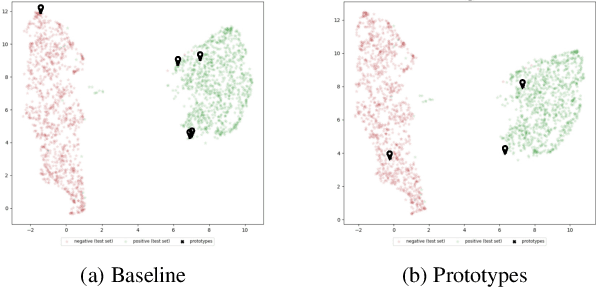
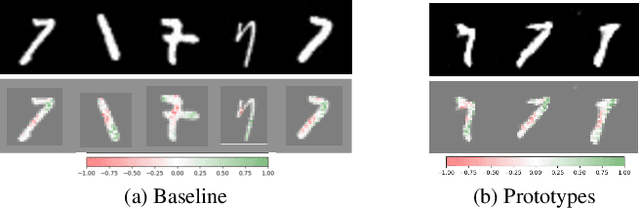
The increasing use of deep learning across various domains highlights the importance of understanding the decision-making processes of these black-box models. Recent research focusing on the decision boundaries of deep classifiers, relies on generated synthetic instances in areas of low confidence, uncovering samples that challenge both models and humans. We propose a novel approach to enhance the interpretability of deep binary classifiers by selecting representative samples from the decision boundary - prototypes - and applying post-model explanation algorithms. We evaluate the effectiveness of our approach through 2D visualizations and GradientSHAP analysis. Our experiments demonstrate the potential of the proposed method, revealing distinct and compact clusters and diverse prototypes that capture essential features that lead to low-confidence decisions. By offering a more aggregated view of deep classifiers' decision boundaries, our work contributes to the responsible development and deployment of reliable machine learning systems.