 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeNLEX: Weakly Supervised Natural Language Explanations for Multilabel Chest X-ray Classification
Mar 19, 2026Natural language explanations provide an inherently human-understandable way to explain black-box models, closely reflecting how radiologists convey their diagnoses in textual reports. Most works explicitly supervise the explanation generation process using datasets annotated with explanations. Thus, though plausible, the generated explanations are not faithful to the model's reasoning. In this work, we propose WeNLEX, a weakly supervised model for the generation of natural language explanations for multilabel chest X-ray classification. Faithfulness is ensured by matching images generated from their corresponding natural language explanations with original images, in the black-box model's feature space. Plausibility is maintained via distribution alignment with a small database of clinician-annotated explanations. We empirically demonstrate, through extensive validation on multiple metrics to assess faithfulness, simulatability, diversity, and plausibility, that WeNLEX is able to produce faithful and plausible explanations, using as little as 5 ground-truth explanations per diagnosis. Furthermore, WeNLEX can operate in both post-hoc and in-model settings. In the latter, i.e., when the multilabel classifier is trained together with the rest of the network, WeNLEX improves the classification AUC of the standalone classifier by 2.21%, thus showing that adding interpretability to the training process can actually increase the downstream task performance. Additionally, simply by changing the database, WeNLEX explanations are adaptable to any target audience, and we showcase this flexibility by training a layman version of WeNLEX, where explanations are simplified for non-medical users.
Unlocking Generalization in Polyp Segmentation with DINO Self-Attention "keys"
Dec 15, 2025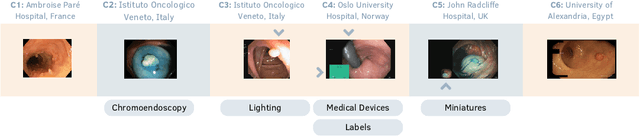

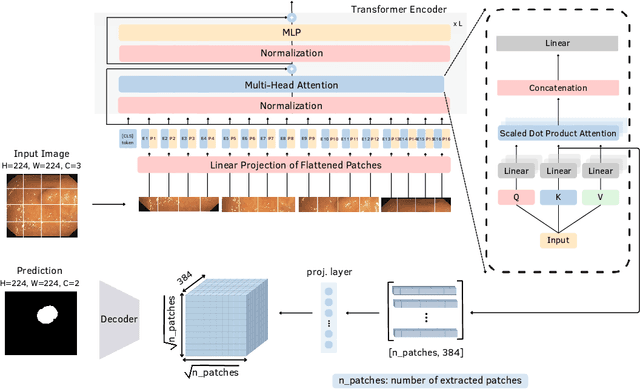

Automatic polyp segmentation is crucial for improving the clinical identification of colorectal cancer (CRC). While Deep Learning (DL) techniques have been extensively researched for this problem, current methods frequently struggle with generalization, particularly in data-constrained or challenging settings. Moreover, many existing polyp segmentation methods rely on complex, task-specific architectures. To address these limitations, we present a framework that leverages the intrinsic robustness of DINO self-attention "key" features for robust segmentation. Unlike traditional methods that extract tokens from the deepest layers of the Vision Transformer (ViT), our approach leverages the key features of the self-attention module with a simple convolutional decoder to predict polyp masks, resulting in enhanced performance and better generalizability. We validate our approach using a multi-center dataset under two rigorous protocols: Domain Generalization (DG) and Extreme Single Domain Generalization (ESDG). Our results, supported by a comprehensive statistical analysis, demonstrate that this pipeline achieves state-of-the-art (SOTA) performance, significantly enhancing generalization, particularly in data-scarce and challenging scenarios. While avoiding a polyp-specific architecture, we surpass well-established models like nnU-Net and UM-Net. Additionally, we provide a systematic benchmark of the DINO framework's evolution, quantifying the specific impact of architectural advancements on downstream polyp segmentation performance.
CBVLM: Training-free Explainable Concept-based Large Vision Language Models for Medical Image Classification
Jan 21, 2025



The main challenges limiting the adoption of deep learning-based solutions in medical workflows are the availability of annotated data and the lack of interpretability of such systems. Concept Bottleneck Models (CBMs) tackle the latter by constraining the final disease prediction on a set of predefined and human-interpretable concepts. However, the increased interpretability achieved through these concept-based explanations implies a higher annotation burden. Moreover, if a new concept needs to be added, the whole system needs to be retrained. Inspired by the remarkable performance shown by Large Vision-Language Models (LVLMs) in few-shot settings, we propose a simple, yet effective, methodology, CBVLM, which tackles both of the aforementioned challenges. First, for each concept, we prompt the LVLM to answer if the concept is present in the input image. Then, we ask the LVLM to classify the image based on the previous concept predictions. Moreover, in both stages, we incorporate a retrieval module responsible for selecting the best examples for in-context learning. By grounding the final diagnosis on the predicted concepts, we ensure explainability, and by leveraging the few-shot capabilities of LVLMs, we drastically lower the annotation cost. We validate our approach with extensive experiments across four medical datasets and twelve LVLMs (both generic and medical) and show that CBVLM consistently outperforms CBMs and task-specific supervised methods without requiring any training and using just a few annotated examples. More information on our project page: https://cristianopatricio.github.io/CBVLM/.
A Two-Step Concept-Based Approach for Enhanced Interpretability and Trust in Skin Lesion Diagnosis
Nov 08, 2024The main challenges hindering the adoption of deep learning-based systems in clinical settings are the scarcity of annotated data and the lack of interpretability and trust in these systems. Concept Bottleneck Models (CBMs) offer inherent interpretability by constraining the final disease prediction on a set of human-understandable concepts. However, this inherent interpretability comes at the cost of greater annotation burden. Additionally, adding new concepts requires retraining the entire system. In this work, we introduce a novel two-step methodology that addresses both of these challenges. By simulating the two stages of a CBM, we utilize a pretrained Vision Language Model (VLM) to automatically predict clinical concepts, and a Large Language Model (LLM) to generate disease diagnoses based on the predicted concepts. We validate our approach on three skin lesion datasets, demonstrating that it outperforms traditional CBMs and state-of-the-art explainable methods, all without requiring any training and utilizing only a few annotated examples. The code is available at https://github.com/CristianoPatricio/2-step-concept-based-skin-diagnosis.
Finding Patterns in Ambiguity: Interpretable Stress Testing in the Decision~Boundary
Aug 12, 2024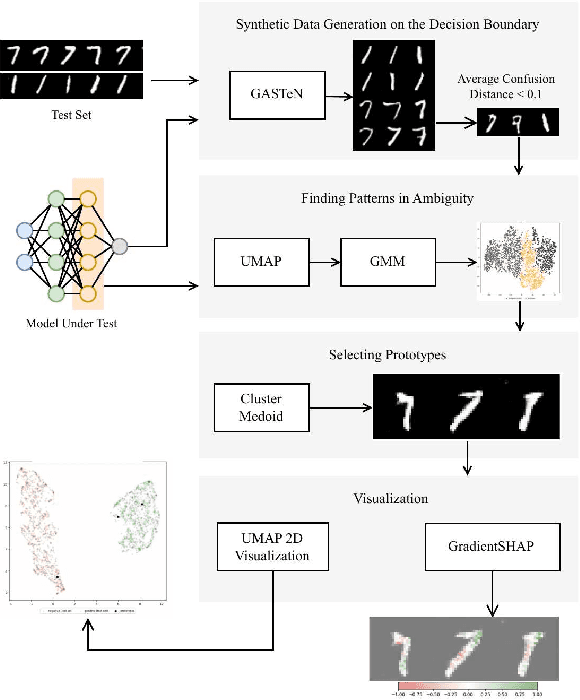
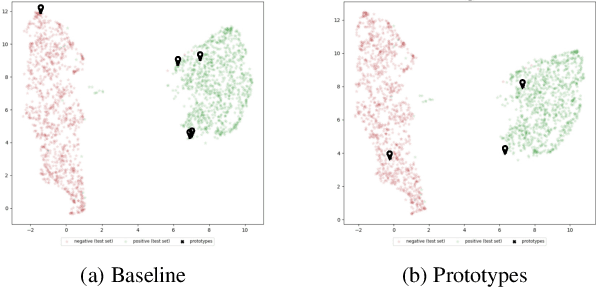
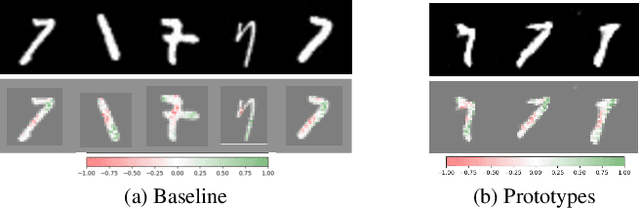
The increasing use of deep learning across various domains highlights the importance of understanding the decision-making processes of these black-box models. Recent research focusing on the decision boundaries of deep classifiers, relies on generated synthetic instances in areas of low confidence, uncovering samples that challenge both models and humans. We propose a novel approach to enhance the interpretability of deep binary classifiers by selecting representative samples from the decision boundary - prototypes - and applying post-model explanation algorithms. We evaluate the effectiveness of our approach through 2D visualizations and GradientSHAP analysis. Our experiments demonstrate the potential of the proposed method, revealing distinct and compact clusters and diverse prototypes that capture essential features that lead to low-confidence decisions. By offering a more aggregated view of deep classifiers' decision boundaries, our work contributes to the responsible development and deployment of reliable machine learning systems.
Markerless Multi-view 3D Human Pose Estimation: a survey
Jul 04, 2024



3D human pose estimation aims to reconstruct the human skeleton of all the individuals in a scene by detecting several body joints. The creation of accurate and efficient methods is required for several real-world applications including animation, human-robot interaction, surveillance systems or sports, among many others. However, several obstacles such as occlusions, random camera perspectives, or the scarcity of 3D labelled data, have been hampering the models' performance and limiting their deployment in real-world scenarios. The higher availability of cameras has led researchers to explore multi-view solutions due to the advantage of being able to exploit different perspectives to reconstruct the pose. Thus, the goal of this survey is to present an overview of the methodologies used to estimate the 3D pose in multi-view settings, understand what were the strategies found to address the various challenges and also, identify their limitations. Based on the reviewed articles, it was possible to find that no method is yet capable of solving all the challenges associated with the reconstruction of the 3D pose. Due to the existing trade-off between complexity and performance, the best method depends on the application scenario. Therefore, further research is still required to develop an approach capable of quickly inferring a highly accurate 3D pose with bearable computation cost. To this goal, techniques such as active learning, methods that learn with a low level of supervision, the incorporation of temporal consistency, view selection, estimation of depth information and multi-modal approaches might be interesting strategies to keep in mind when developing a new methodology to solve this task.
Towards Concept-based Interpretability of Skin Lesion Diagnosis using Vision-Language Models
Nov 24, 2023Concept-based models naturally lend themselves to the development of inherently interpretable skin lesion diagnosis, as medical experts make decisions based on a set of visual patterns of the lesion. Nevertheless, the development of these models depends on the existence of concept-annotated datasets, whose availability is scarce due to the specialized knowledge and expertise required in the annotation process. In this work, we show that vision-language models can be used to alleviate the dependence on a large number of concept-annotated samples. In particular, we propose an embedding learning strategy to adapt CLIP to the downstream task of skin lesion classification using concept-based descriptions as textual embeddings. Our experiments reveal that vision-language models not only attain better accuracy when using concepts as textual embeddings, but also require a smaller number of concept-annotated samples to attain comparable performance to approaches specifically devised for automatic concept generation.
Coherent Concept-based Explanations in Medical Image and Its Application to Skin Lesion Diagnosis
Apr 17, 2023



Early detection of melanoma is crucial for preventing severe complications and increasing the chances of successful treatment. Existing deep learning approaches for melanoma skin lesion diagnosis are deemed black-box models, as they omit the rationale behind the model prediction, compromising the trustworthiness and acceptability of these diagnostic methods. Attempts to provide concept-based explanations are based on post-hoc approaches, which depend on an additional model to derive interpretations. In this paper, we propose an inherently interpretable framework to improve the interpretability of concept-based models by incorporating a hard attention mechanism and a coherence loss term to assure the visual coherence of concept activations by the concept encoder, without requiring the supervision of additional annotations. The proposed framework explains its decision in terms of human-interpretable concepts and their respective contribution to the final prediction, as well as a visual interpretation of the locations where the concept is present in the image. Experiments on skin image datasets demonstrate that our method outperforms existing black-box and concept-based models for skin lesion classification.
Explainable Deep Learning Methods in Medical Diagnosis: A Survey
May 10, 2022The remarkable success of deep learning has prompted interest in its application to medical diagnosis. Even tough state-of-the-art deep learning models have achieved human-level accuracy on the classification of different types of medical data, these models are hardly adopted in clinical workflows, mainly due to their lack of interpretability. The black-box-ness of deep learning models has raised the need for devising strategies to explain the decision process of these models, leading to the creation of the topic of eXplainable Artificial Intelligence (XAI). In this context, we provide a thorough survey of XAI applied to medical diagnosis, including visual, textual, and example-based explanation methods. Moreover, this work reviews the existing medical imaging datasets and the existing metrics for evaluating the quality of the explanations . Complementary to most existing surveys, we include a performance comparison among a set of report generation-based methods. Finally, the major challenges in applying XAI to medical imaging are also discussed.
A survey on attention mechanisms for medical applications: are we moving towards better algorithms?
Apr 26, 2022

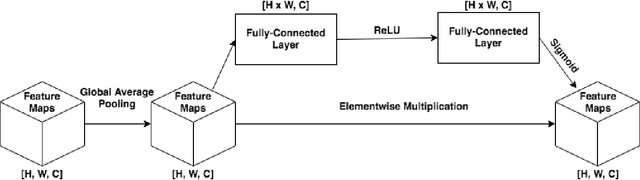
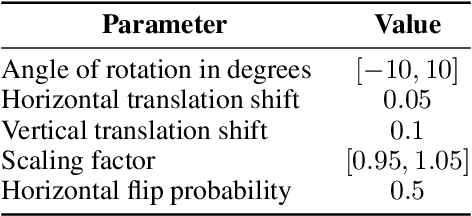
The increasing popularity of attention mechanisms in deep learning algorithms for computer vision and natural language processing made these models attractive to other research domains. In healthcare, there is a strong need for tools that may improve the routines of the clinicians and the patients. Naturally, the use of attention-based algorithms for medical applications occurred smoothly. However, being healthcare a domain that depends on high-stake decisions, the scientific community must ponder if these high-performing algorithms fit the needs of medical applications. With this motto, this paper extensively reviews the use of attention mechanisms in machine learning (including Transformers) for several medical applications. This work distinguishes itself from its predecessors by proposing a critical analysis of the claims and potentialities of attention mechanisms presented in the literature through an experimental case study on medical image classification with three different use cases. These experiments focus on the integrating process of attention mechanisms into established deep learning architectures, the analysis of their predictive power, and a visual assessment of their saliency maps generated by post-hoc explanation methods. This paper concludes with a critical analysis of the claims and potentialities presented in the literature about attention mechanisms and proposes future research lines in medical applications that may benefit from these frameworks.