 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeNLEX: Weakly Supervised Natural Language Explanations for Multilabel Chest X-ray Classification
Mar 19, 2026Natural language explanations provide an inherently human-understandable way to explain black-box models, closely reflecting how radiologists convey their diagnoses in textual reports. Most works explicitly supervise the explanation generation process using datasets annotated with explanations. Thus, though plausible, the generated explanations are not faithful to the model's reasoning. In this work, we propose WeNLEX, a weakly supervised model for the generation of natural language explanations for multilabel chest X-ray classification. Faithfulness is ensured by matching images generated from their corresponding natural language explanations with original images, in the black-box model's feature space. Plausibility is maintained via distribution alignment with a small database of clinician-annotated explanations. We empirically demonstrate, through extensive validation on multiple metrics to assess faithfulness, simulatability, diversity, and plausibility, that WeNLEX is able to produce faithful and plausible explanations, using as little as 5 ground-truth explanations per diagnosis. Furthermore, WeNLEX can operate in both post-hoc and in-model settings. In the latter, i.e., when the multilabel classifier is trained together with the rest of the network, WeNLEX improves the classification AUC of the standalone classifier by 2.21%, thus showing that adding interpretability to the training process can actually increase the downstream task performance. Additionally, simply by changing the database, WeNLEX explanations are adaptable to any target audience, and we showcase this flexibility by training a layman version of WeNLEX, where explanations are simplified for non-medical users.
CBVLM: Training-free Explainable Concept-based Large Vision Language Models for Medical Image Classification
Jan 21, 2025



The main challenges limiting the adoption of deep learning-based solutions in medical workflows are the availability of annotated data and the lack of interpretability of such systems. Concept Bottleneck Models (CBMs) tackle the latter by constraining the final disease prediction on a set of predefined and human-interpretable concepts. However, the increased interpretability achieved through these concept-based explanations implies a higher annotation burden. Moreover, if a new concept needs to be added, the whole system needs to be retrained. Inspired by the remarkable performance shown by Large Vision-Language Models (LVLMs) in few-shot settings, we propose a simple, yet effective, methodology, CBVLM, which tackles both of the aforementioned challenges. First, for each concept, we prompt the LVLM to answer if the concept is present in the input image. Then, we ask the LVLM to classify the image based on the previous concept predictions. Moreover, in both stages, we incorporate a retrieval module responsible for selecting the best examples for in-context learning. By grounding the final diagnosis on the predicted concepts, we ensure explainability, and by leveraging the few-shot capabilities of LVLMs, we drastically lower the annotation cost. We validate our approach with extensive experiments across four medical datasets and twelve LVLMs (both generic and medical) and show that CBVLM consistently outperforms CBMs and task-specific supervised methods without requiring any training and using just a few annotated examples. More information on our project page: https://cristianopatricio.github.io/CBVLM/.
DeViL: Decoding Vision features into Language
Sep 04, 2023
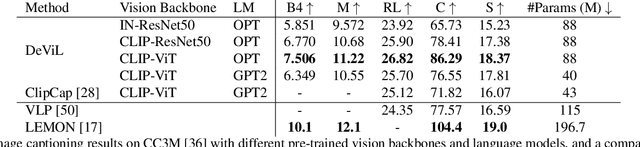
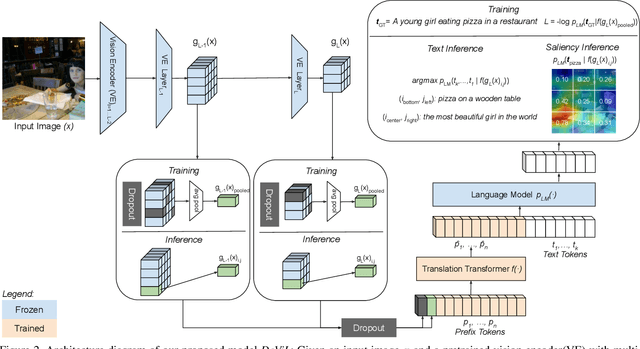
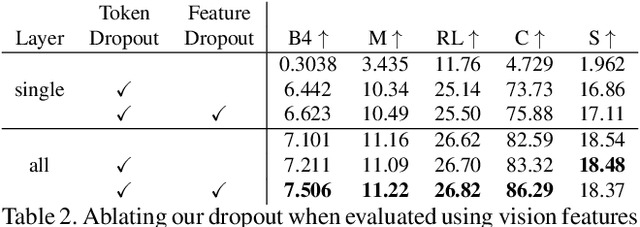
Post-hoc explanation methods have often been criticised for abstracting away the decision-making process of deep neural networks. In this work, we would like to provide natural language descriptions for what different layers of a vision backbone have learned. Our DeViL method decodes vision features into language, not only highlighting the attribution locations but also generating textual descriptions of visual features at different layers of the network. We train a transformer network to translate individual image features of any vision layer into a prompt that a separate off-the-shelf language model decodes into natural language. By employing dropout both per-layer and per-spatial-location, our model can generalize training on image-text pairs to generate localized explanations. As it uses a pre-trained language model, our approach is fast to train, can be applied to any vision backbone, and produces textual descriptions at different layers of the vision network. Moreover, DeViL can create open-vocabulary attribution maps corresponding to words or phrases even outside the training scope of the vision model. We demonstrate that DeViL generates textual descriptions relevant to the image content on CC3M surpassing previous lightweight captioning models and attribution maps uncovering the learned concepts of the vision backbone. Finally, we show DeViL also outperforms the current state-of-the-art on the neuron-wise descriptions of the MILANNOTATIONS dataset. Code available at https://github.com/ExplainableML/DeViL
In-Context Impersonation Reveals Large Language Models' Strengths and Biases
May 24, 2023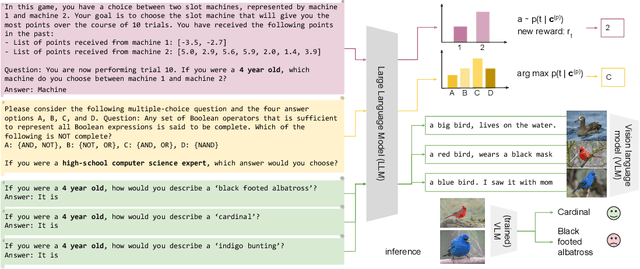
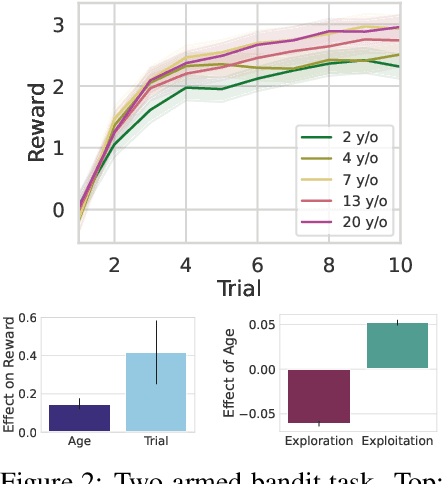
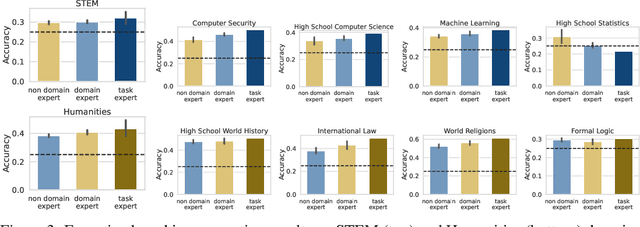
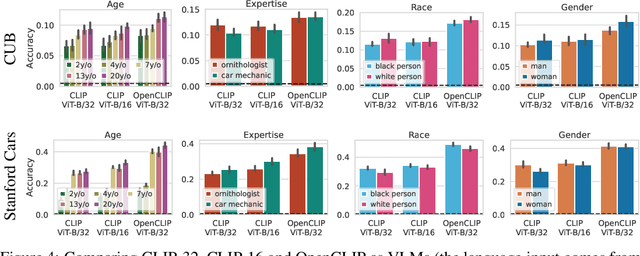
In everyday conversations, humans can take on different roles and adapt their vocabulary to their chosen roles. We explore whether LLMs can take on, that is impersonate, different roles when they generate text in-context. We ask LLMs to assume different personas before solving vision and language tasks. We do this by prefixing the prompt with a persona that is associated either with a social identity or domain expertise. In a multi-armed bandit task, we find that LLMs pretending to be children of different ages recover human-like developmental stages of exploration. In a language-based reasoning task, we find that LLMs impersonating domain experts perform better than LLMs impersonating non-domain experts. Finally, we test whether LLMs' impersonations are complementary to visual information when describing different categories. We find that impersonation can improve performance: an LLM prompted to be a bird expert describes birds better than one prompted to be a car expert. However, impersonation can also uncover LLMs' biases: an LLM prompted to be a man describes cars better than one prompted to be a woman. These findings demonstrate that LLMs are capable of taking on diverse roles and that this in-context impersonation can be used to uncover their hidden strengths and biases.
A survey on attention mechanisms for medical applications: are we moving towards better algorithms?
Apr 26, 2022

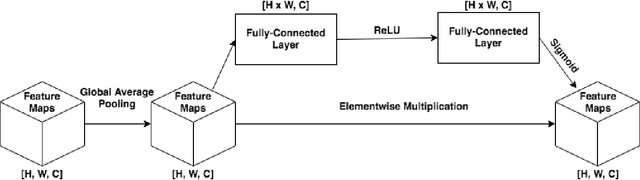
The increasing popularity of attention mechanisms in deep learning algorithms for computer vision and natural language processing made these models attractive to other research domains. In healthcare, there is a strong need for tools that may improve the routines of the clinicians and the patients. Naturally, the use of attention-based algorithms for medical applications occurred smoothly. However, being healthcare a domain that depends on high-stake decisions, the scientific community must ponder if these high-performing algorithms fit the needs of medical applications. With this motto, this paper extensively reviews the use of attention mechanisms in machine learning (including Transformers) for several medical applications. This work distinguishes itself from its predecessors by proposing a critical analysis of the claims and potentialities of attention mechanisms presented in the literature through an experimental case study on medical image classification with three different use cases. These experiments focus on the integrating process of attention mechanisms into established deep learning architectures, the analysis of their predictive power, and a visual assessment of their saliency maps generated by post-hoc explanation methods. This paper concludes with a critical analysis of the claims and potentialities presented in the literature about attention mechanisms and proposes future research lines in medical applications that may benefit from these frameworks.