 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Transformer Placement in Variational Autoencoders for Tabular Data Generation
Jan 28, 2026Tabular data remains a challenging domain for generative models. In particular, the standard Variational Autoencoder (VAE) architecture, typically composed of multilayer perceptrons, struggles to model relationships between features, especially when handling mixed data types. In contrast, Transformers, through their attention mechanism, are better suited for capturing complex feature interactions. In this paper, we empirically investigate the impact of integrating Transformers into different components of a VAE. We conduct experiments on 57 datasets from the OpenML CC18 suite and draw two main conclusions. First, results indicate that positioning Transformers to leverage latent and decoder representations leads to a trade-off between fidelity and diversity. Second, we observe a high similarity between consecutive blocks of a Transformer in all components. In particular, in the decoder, the relationship between the input and output of a Transformer is approximately linear.
Tabular data generation with tensor contraction layers and transformers
Dec 06, 2024



Generative modeling for tabular data has recently gained significant attention in the Deep Learning domain. Its objective is to estimate the underlying distribution of the data. However, estimating the underlying distribution of tabular data has its unique challenges. Specifically, this data modality is composed of mixed types of features, making it a non-trivial task for a model to learn intra-relationships between them. One approach to address mixture is to embed each feature into a continuous matrix via tokenization, while a solution to capture intra-relationships between variables is via the transformer architecture. In this work, we empirically investigate the potential of using embedding representations on tabular data generation, utilizing tensor contraction layers and transformers to model the underlying distribution of tabular data within Variational Autoencoders. Specifically, we compare four architectural approaches: a baseline VAE model, two variants that focus on tensor contraction layers and transformers respectively, and a hybrid model that integrates both techniques. Our empirical study, conducted across multiple datasets from the OpenML CC18 suite, compares models over density estimation and Machine Learning efficiency metrics. The main takeaway from our results is that leveraging embedding representations with the help of tensor contraction layers improves density estimation metrics, albeit maintaining competitive performance in terms of machine learning efficiency.
Model Optimization in Imbalanced Regression
Jun 20, 2022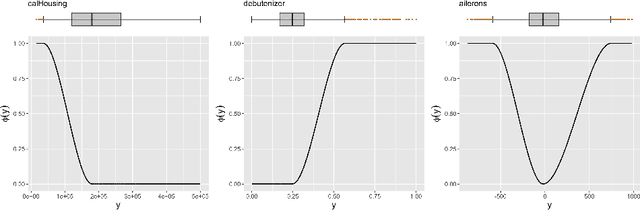
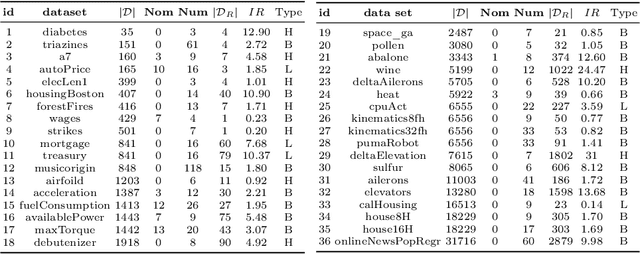

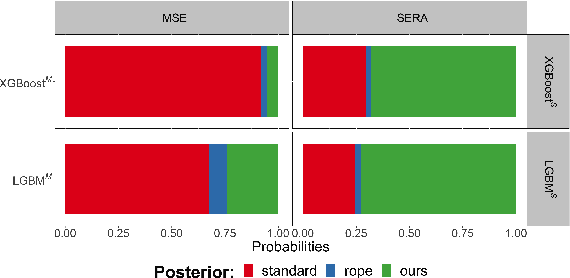
Imbalanced domain learning aims to produce accurate models in predicting instances that, though underrepresented, are of utmost importance for the domain. Research in this field has been mainly focused on classification tasks. Comparatively, the number of studies carried out in the context of regression tasks is negligible. One of the main reasons for this is the lack of loss functions capable of focusing on minimizing the errors of extreme (rare) values. Recently, an evaluation metric was introduced: Squared Error Relevance Area (SERA). This metric posits a bigger emphasis on the errors committed at extreme values while also accounting for the performance in the overall target variable domain, thus preventing severe bias. However, its effectiveness as an optimization metric is unknown. In this paper, our goal is to study the impacts of using SERA as an optimization criterion in imbalanced regression tasks. Using gradient boosting algorithms as proof of concept, we perform an experimental study with 36 data sets of different domains and sizes. Results show that models that used SERA as an objective function are practically better than the models produced by their respective standard boosting algorithms at the prediction of extreme values. This confirms that SERA can be embedded as a loss function into optimization-based learning algorithms for imbalanced regression scenarios.