 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking XAI Evaluation: A Human-Centered Audit of Shapley Benchmarks in High-Stakes Settings
Apr 24, 2026Shapley values are a cornerstone of explainable AI, yet their proliferation into competing formulations has created a fragmented landscape with little consensus on practical deployment. While theoretical differences are well-documented, evaluation remains reliant on quantitative proxies whose alignment with human utility is unverified. In this work, we use a unified amortized framework to isolate semantic differences between eight Shapley variants under the low-latency constraints of operational risk workflows. We conduct a large-scale empirical evaluation across four risk datasets and a realistic fraud-detection environment involving professional analysts and 3,735 case reviews. Our results reveal a fundamental misalignment: standard quantitative metrics, such as sparsity and faithfulness, are decoupled from human-perceived clarity and decision utility. Furthermore, while no formulation improved objective analyst performance, explanations consistently increased decision confidence, signaling a critical risk of automation bias in high-stakes settings. These findings suggest that current evaluation proxies are insufficient for predicting downstream human impact, and we provide evidence-based guidance for selecting formulations and metrics in operational decision systems.
MUSE: Multi-Tenant Model Serving With Seamless Model Updates
Feb 12, 2026In binary classification systems, decision thresholds translate model scores into actions. Choosing suitable thresholds relies on the specific distribution of the underlying model scores but also on the specific business decisions of each client using that model. However, retraining models inevitably shifts score distributions, invalidating existing thresholds. In multi-tenant Score-as-a-Service environments, where decision boundaries reside in client-managed infrastructure, this creates a severe bottleneck: recalibration requires coordinating threshold updates across hundreds of clients, consuming excessive human hours and leading to model stagnation. We introduce MUSE, a model serving framework that enables seamless model updates by decoupling model scores from client decision boundaries. Designed for multi-tenancy, MUSE optimizes infrastructure re-use by sharing models via dynamic intent-based routing, combined with a two-level score transformation that maps model outputs to a stable, reference distribution. Deployed at scale by Feedzai, MUSE processes over a thousand events per second, and over 55 billion events in the last 12 months, across several dozens of tenants, while maintaining high-availability and low-latency guarantees. By reducing model lead time from weeks to minutes, MUSE promotes model resilience against shifting attacks, saving millions of dollars in fraud losses and operational costs.
Mind the truncation gap: challenges of learning on dynamic graphs with recurrent architectures
Dec 30, 2024



Systems characterized by evolving interactions, prevalent in social, financial, and biological domains, are effectively modeled as continuous-time dynamic graphs (CTDGs). To manage the scale and complexity of these graph datasets, machine learning (ML) approaches have become essential. However, CTDGs pose challenges for ML because traditional static graph methods do not naturally account for event timings. Newer approaches, such as graph recurrent neural networks (GRNNs), are inherently time-aware and offer advantages over static methods for CTDGs. However, GRNNs face another issue: the short truncation of backpropagation-through-time (BPTT), whose impact has not been properly examined until now. In this work, we demonstrate that this truncation can limit the learning of dependencies beyond a single hop, resulting in reduced performance. Through experiments on a novel synthetic task and real-world datasets, we reveal a performance gap between full backpropagation-through-time (F-BPTT) and the truncated backpropagation-through-time (T-BPTT) commonly used to train GRNN models. We term this gap the "truncation gap" and argue that understanding and addressing it is essential as the importance of CTDGs grows, discussing potential future directions for research in this area.
Fair-OBNC: Correcting Label Noise for Fairer Datasets
Oct 08, 2024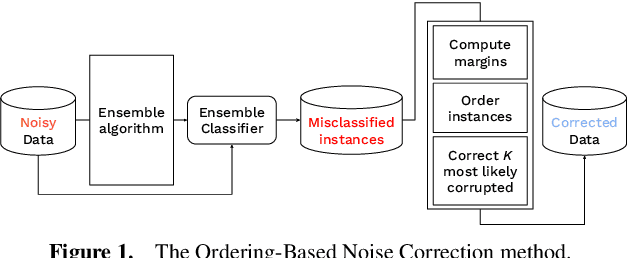
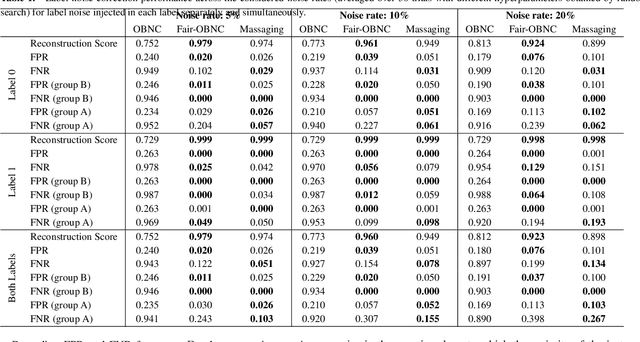
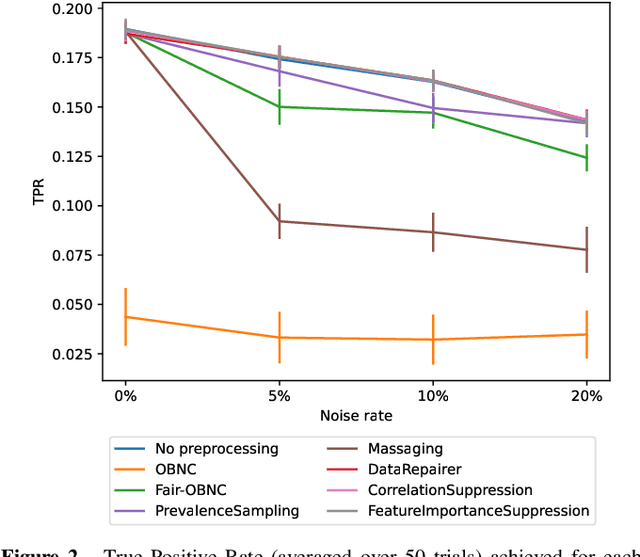
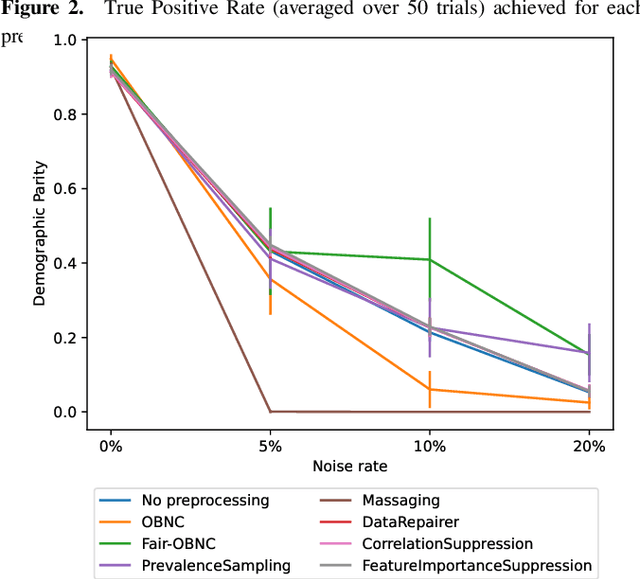
Data used by automated decision-making systems, such as Machine Learning models, often reflects discriminatory behavior that occurred in the past. These biases in the training data are sometimes related to label noise, such as in COMPAS, where more African-American offenders are wrongly labeled as having a higher risk of recidivism when compared to their White counterparts. Models trained on such biased data may perpetuate or even aggravate the biases with respect to sensitive information, such as gender, race, or age. However, while multiple label noise correction approaches are available in the literature, these focus on model performance exclusively. In this work, we propose Fair-OBNC, a label noise correction method with fairness considerations, to produce training datasets with measurable demographic parity. The presented method adapts Ordering-Based Noise Correction, with an adjusted criterion of ordering, based both on the margin of error of an ensemble, and the potential increase in the observed demographic parity of the dataset. We evaluate Fair-OBNC against other different pre-processing techniques, under different scenarios of controlled label noise. Our results show that the proposed method is the overall better alternative within the pool of label correction methods, being capable of attaining better reconstructions of the original labels. Models trained in the corrected data have an increase, on average, of 150% in demographic parity, when compared to models trained in data with noisy labels, across the considered levels of label noise.
Show Me What's Wrong!: Combining Charts and Text to Guide Data Analysis
Oct 02, 2024Analyzing and finding anomalies in multi-dimensional datasets is a cumbersome but vital task across different domains. In the context of financial fraud detection, analysts must quickly identify suspicious activity among transactional data. This is an iterative process made of complex exploratory tasks such as recognizing patterns, grouping, and comparing. To mitigate the information overload inherent to these steps, we present a tool combining automated information highlights, Large Language Model generated textual insights, and visual analytics, facilitating exploration at different levels of detail. We perform a segmentation of the data per analysis area and visually represent each one, making use of automated visual cues to signal which require more attention. Upon user selection of an area, our system provides textual and graphical summaries. The text, acting as a link between the high-level and detailed views of the chosen segment, allows for a quick understanding of relevant details. A thorough exploration of the data comprising the selection can be done through graphical representations. The feedback gathered in a study performed with seven domain experts suggests our tool effectively supports and guides exploratory analysis, easing the identification of suspicious information.
RIFF: Inducing Rules for Fraud Detection from Decision Trees
Aug 23, 2024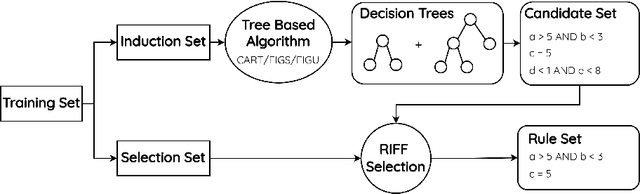

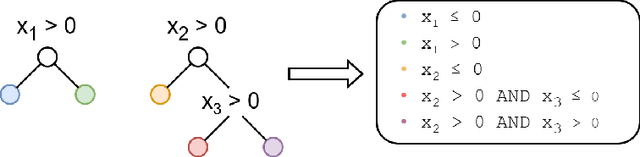
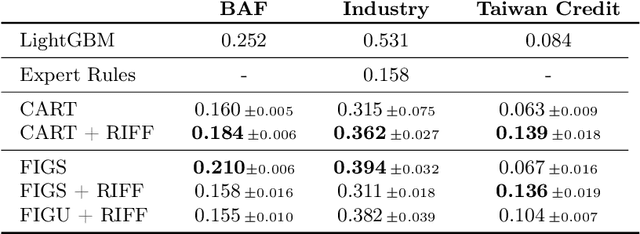
Financial fraud is the cause of multi-billion dollar losses annually. Traditionally, fraud detection systems rely on rules due to their transparency and interpretability, key features in domains where decisions need to be explained. However, rule systems require significant input from domain experts to create and tune, an issue that rule induction algorithms attempt to mitigate by inferring rules directly from data. We explore the application of these algorithms to fraud detection, where rule systems are constrained to have a low false positive rate (FPR) or alert rate, by proposing RIFF, a rule induction algorithm that distills a low FPR rule set directly from decision trees. Our experiments show that the induced rules are often able to maintain or improve performance of the original models for low FPR tasks, while substantially reducing their complexity and outperforming rules hand-tuned by experts.
Deep-Graph-Sprints: Accelerated Representation Learning in Continuous-Time Dynamic Graphs
Jul 10, 2024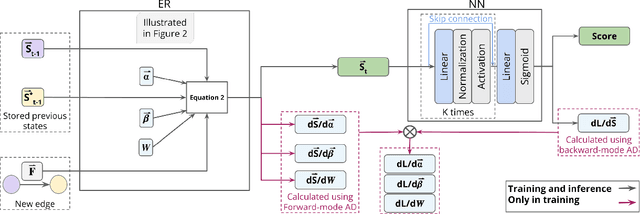



Continuous-time dynamic graphs (CTDGs) are essential for modeling interconnected, evolving systems. Traditional methods for extracting knowledge from these graphs often depend on feature engineering or deep learning. Feature engineering is limited by the manual and time-intensive nature of crafting features, while deep learning approaches suffer from high inference latency, making them impractical for real-time applications. This paper introduces Deep-Graph-Sprints (DGS), a novel deep learning architecture designed for efficient representation learning on CTDGs with low-latency inference requirements. We benchmark DGS against state-of-the-art feature engineering and graph neural network methods using five diverse datasets. The results indicate that DGS achieves competitive performance while improving inference speed up to 12x compared to other deep learning approaches on our tested benchmarks. Our method effectively bridges the gap between deep representation learning and low-latency application requirements for CTDGs.
Aequitas Flow: Streamlining Fair ML Experimentation
May 09, 2024Aequitas Flow is an open-source framework for end-to-end Fair Machine Learning (ML) experimentation in Python. This package fills the existing integration gaps in other Fair ML packages of complete and accessible experimentation. It provides a pipeline for fairness-aware model training, hyperparameter optimization, and evaluation, enabling rapid and simple experiments and result analysis. Aimed at ML practitioners and researchers, the framework offers implementations of methods, datasets, metrics, and standard interfaces for these components to improve extensibility. By facilitating the development of fair ML practices, Aequitas Flow seeks to enhance the adoption of these concepts in AI technologies.
Cost-Sensitive Learning to Defer to Multiple Experts with Workload Constraints
Mar 21, 2024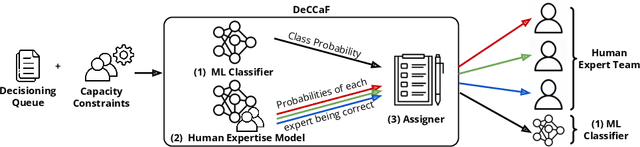
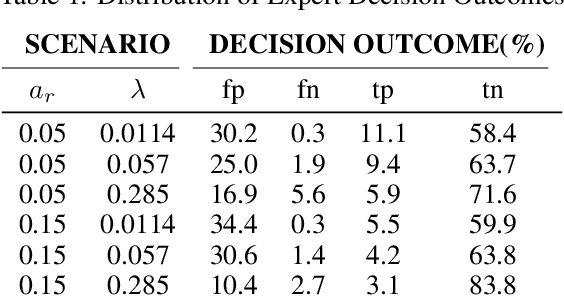
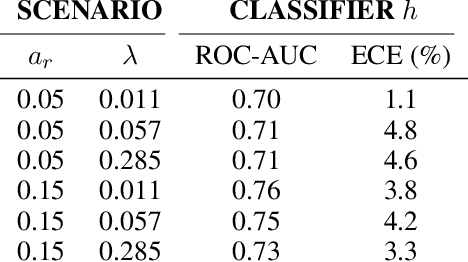
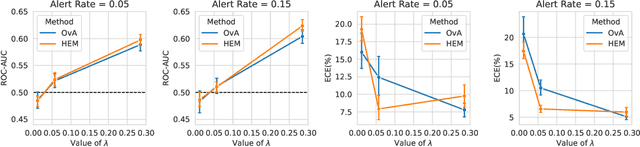
Learning to defer (L2D) aims to improve human-AI collaboration systems by learning how to defer decisions to humans when they are more likely to be correct than an ML classifier. Existing research in L2D overlooks key aspects of real-world systems that impede its practical adoption, namely: i) neglecting cost-sensitive scenarios, where type 1 and type 2 errors have different costs; ii) requiring concurrent human predictions for every instance of the training dataset and iii) not dealing with human work capacity constraints. To address these issues, we propose the deferral under cost and capacity constraints framework (DeCCaF). DeCCaF is a novel L2D approach, employing supervised learning to model the probability of human error under less restrictive data requirements (only one expert prediction per instance) and using constraint programming to globally minimize the error cost subject to workload limitations. We test DeCCaF in a series of cost-sensitive fraud detection scenarios with different teams of 9 synthetic fraud analysts, with individual work capacity constraints. The results demonstrate that our approach performs significantly better than the baselines in a wide array of scenarios, achieving an average 8.4% reduction in the misclassification cost.
DiConStruct: Causal Concept-based Explanations through Black-Box Distillation
Jan 26, 2024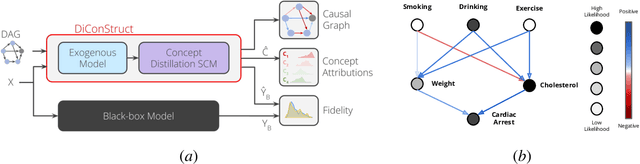
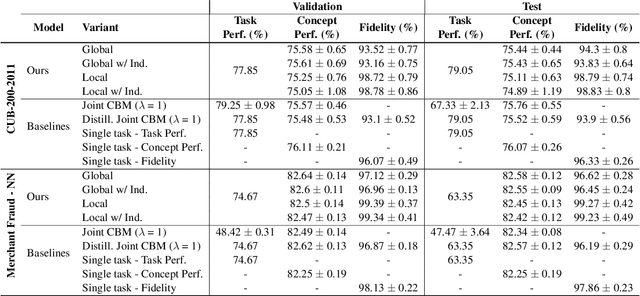
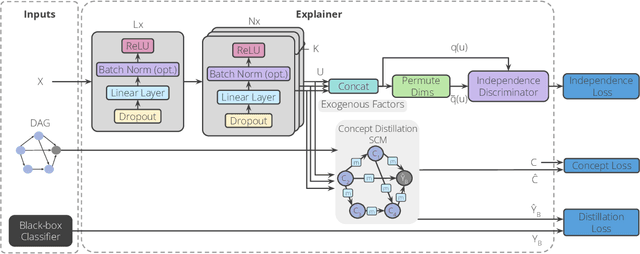
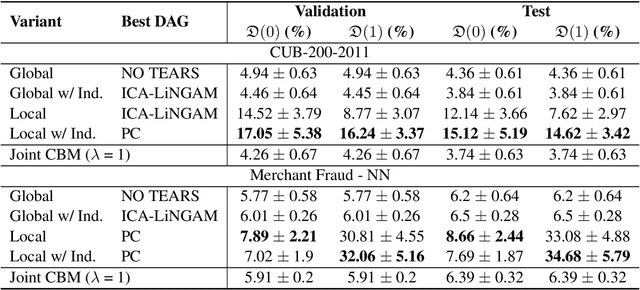
Model interpretability plays a central role in human-AI decision-making systems. Ideally, explanations should be expressed using human-interpretable semantic concepts. Moreover, the causal relations between these concepts should be captured by the explainer to allow for reasoning about the explanations. Lastly, explanation methods should be efficient and not compromise the performance of the predictive task. Despite the rapid advances in AI explainability in recent years, as far as we know to date, no method fulfills these three properties. Indeed, mainstream methods for local concept explainability do not produce causal explanations and incur a trade-off between explainability and prediction performance. We present DiConStruct, an explanation method that is both concept-based and causal, with the goal of creating more interpretable local explanations in the form of structural causal models and concept attributions. Our explainer works as a distillation model to any black-box machine learning model by approximating its predictions while producing the respective explanations. Because of this, DiConStruct generates explanations efficiently while not impacting the black-box prediction task. We validate our method on an image dataset and a tabular dataset, showing that DiConStruct approximates the black-box models with higher fidelity than other concept explainability baselines, while providing explanations that include the causal relations between the concepts.