 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow Me What's Wrong!: Combining Charts and Text to Guide Data Analysis
Oct 02, 2024Analyzing and finding anomalies in multi-dimensional datasets is a cumbersome but vital task across different domains. In the context of financial fraud detection, analysts must quickly identify suspicious activity among transactional data. This is an iterative process made of complex exploratory tasks such as recognizing patterns, grouping, and comparing. To mitigate the information overload inherent to these steps, we present a tool combining automated information highlights, Large Language Model generated textual insights, and visual analytics, facilitating exploration at different levels of detail. We perform a segmentation of the data per analysis area and visually represent each one, making use of automated visual cues to signal which require more attention. Upon user selection of an area, our system provides textual and graphical summaries. The text, acting as a link between the high-level and detailed views of the chosen segment, allows for a quick understanding of relevant details. A thorough exploration of the data comprising the selection can be done through graphical representations. The feedback gathered in a study performed with seven domain experts suggests our tool effectively supports and guides exploratory analysis, easing the identification of suspicious information.
On the Reduction of Biases in Big Data Sets for the Detection of Irregular Power Usage
Apr 03, 2018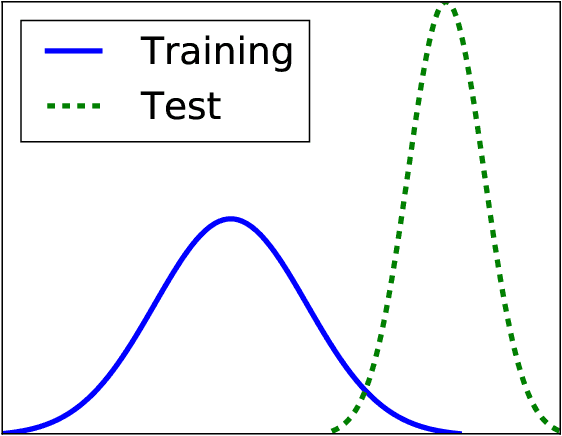



In machine learning, a bias occurs whenever training sets are not representative for the test data, which results in unreliable models. The most common biases in data are arguably class imbalance and covariate shift. In this work, we aim to shed light on this topic in order to increase the overall attention to this issue in the field of machine learning. We propose a scalable novel framework for reducing multiple biases in high-dimensional data sets in order to train more reliable predictors. We apply our methodology to the detection of irregular power usage from real, noisy industrial data. In emerging markets, irregular power usage, and electricity theft in particular, may range up to 40% of the total electricity distributed. Biased data sets are of particular issue in this domain. We show that reducing these biases increases the accuracy of the trained predictors. Our models have the potential to generate significant economic value in a real world application, as they are being deployed in a commercial software for the detection of irregular power usage.
Identifying Irregular Power Usage by Turning Predictions into Holographic Spatial Visualizations
Sep 09, 2017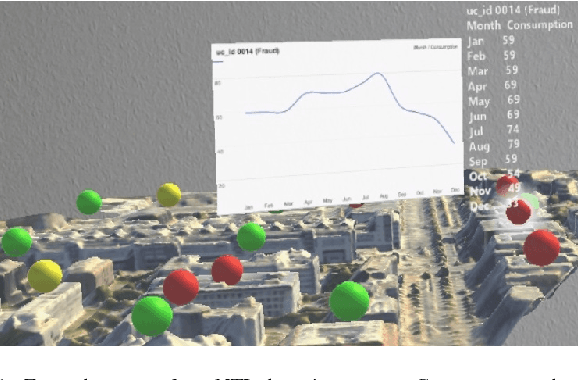
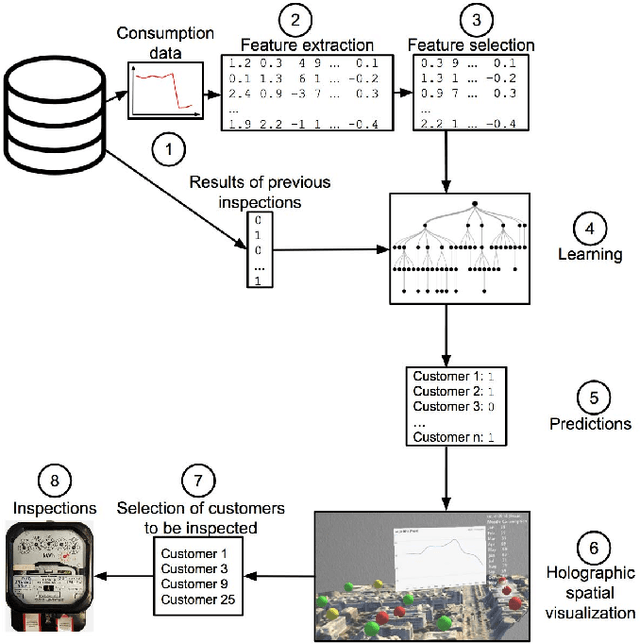

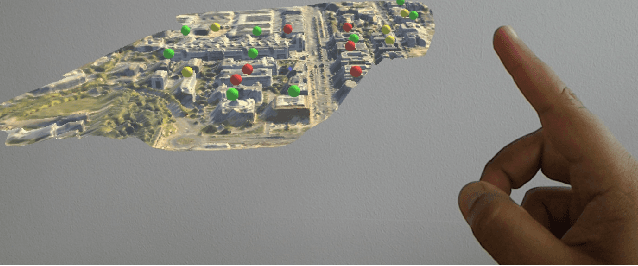
Power grids are critical infrastructure assets that face non-technical losses (NTL) such as electricity theft or faulty meters. NTL may range up to 40% of the total electricity distributed in emerging countries. Industrial NTL detection systems are still largely based on expert knowledge when deciding whether to carry out costly on-site inspections of customers. Electricity providers are reluctant to move to large-scale deployments of automated systems that learn NTL profiles from data due to the latter's propensity to suggest a large number of unnecessary inspections. In this paper, we propose a novel system that combines automated statistical decision making with expert knowledge. First, we propose a machine learning framework that classifies customers into NTL or non-NTL using a variety of features derived from the customers' consumption data. The methodology used is specifically tailored to the level of noise in the data. Second, in order to allow human experts to feed their knowledge in the decision loop, we propose a method for visualizing prediction results at various granularity levels in a spatial hologram. Our approach allows domain experts to put the classification results into the context of the data and to incorporate their knowledge for making the final decisions of which customers to inspect. This work has resulted in appreciable results on a real-world data set of 3.6M customers. Our system is being deployed in a commercial NTL detection software.
Large-Scale Detection of Non-Technical Losses in Imbalanced Data Sets
Jul 25, 2017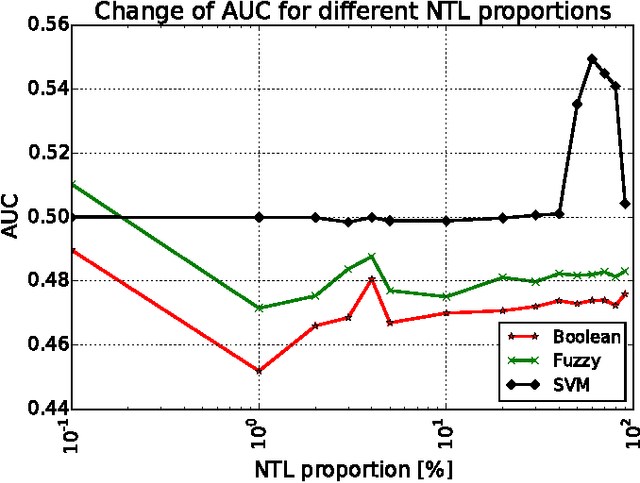
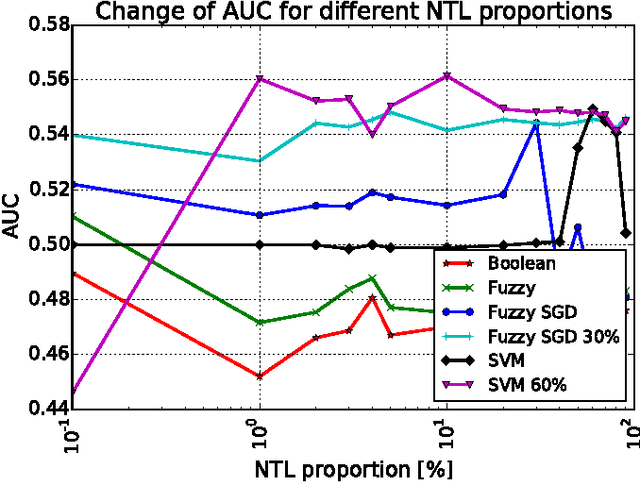
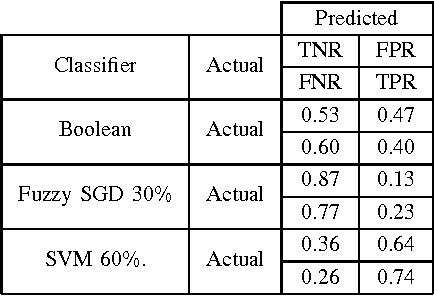
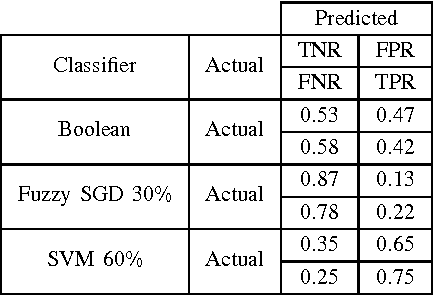
Non-technical losses (NTL) such as electricity theft cause significant harm to our economies, as in some countries they may range up to 40% of the total electricity distributed. Detecting NTLs requires costly on-site inspections. Accurate prediction of NTLs for customers using machine learning is therefore crucial. To date, related research largely ignore that the two classes of regular and non-regular customers are highly imbalanced, that NTL proportions may change and mostly consider small data sets, often not allowing to deploy the results in production. In this paper, we present a comprehensive approach to assess three NTL detection models for different NTL proportions in large real world data sets of 100Ks of customers: Boolean rules, fuzzy logic and Support Vector Machine. This work has resulted in appreciable results that are about to be deployed in a leading industry solution. We believe that the considerations and observations made in this contribution are necessary for future smart meter research in order to report their effectiveness on imbalanced and large real world data sets.
Neighborhood Features Help Detecting Non-Technical Losses in Big Data Sets
Jul 25, 2017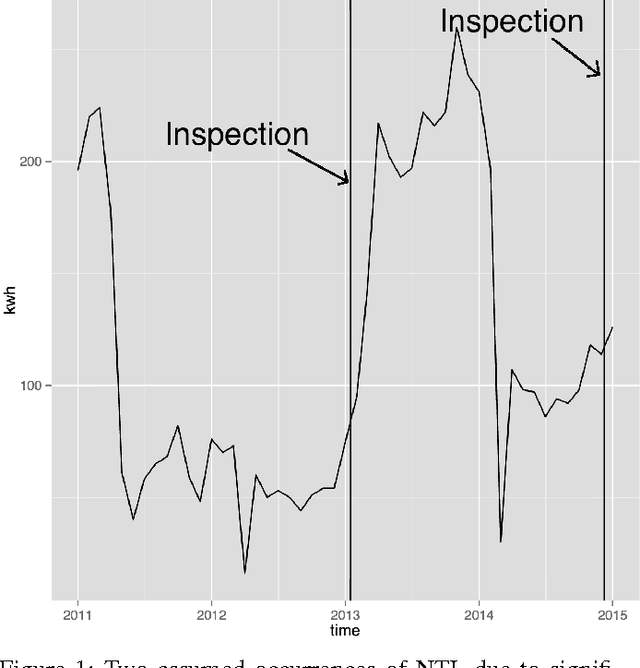
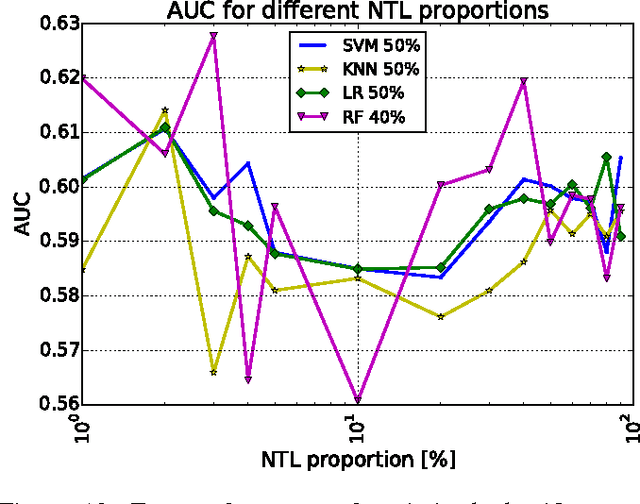
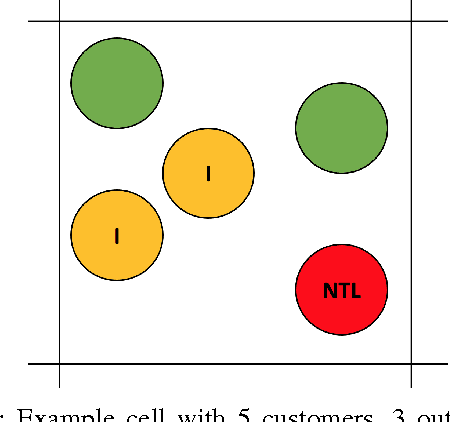
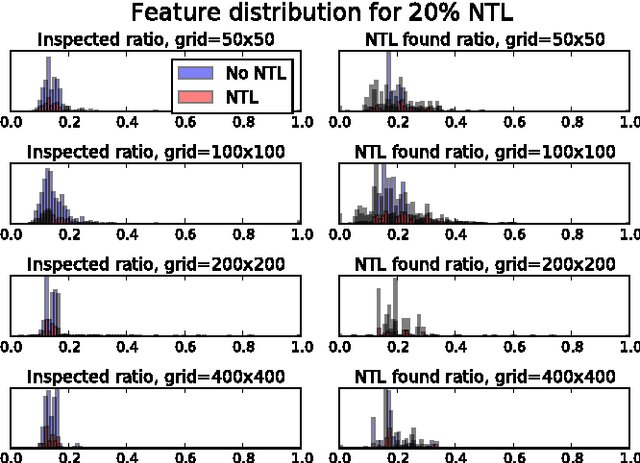
Electricity theft is a major problem around the world in both developed and developing countries and may range up to 40% of the total electricity distributed. More generally, electricity theft belongs to non-technical losses (NTL), which are losses that occur during the distribution of electricity in power grids. In this paper, we build features from the neighborhood of customers. We first split the area in which the customers are located into grids of different sizes. For each grid cell we then compute the proportion of inspected customers and the proportion of NTL found among the inspected customers. We then analyze the distributions of features generated and show why they are useful to predict NTL. In addition, we compute features from the consumption time series of customers. We also use master data features of customers, such as their customer class and voltage of their connection. We compute these features for a Big Data base of 31M meter readings, 700K customers and 400K inspection results. We then use these features to train four machine learning algorithms that are particularly suitable for Big Data sets because of their parallelizable structure: logistic regression, k-nearest neighbors, linear support vector machine and random forest. Using the neighborhood features instead of only analyzing the time series has resulted in appreciable results for Big Data sets for varying NTL proportions of 1%-90%. This work can therefore be deployed to a wide range of different regions around the world.