 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow Me What's Wrong!: Combining Charts and Text to Guide Data Analysis
Oct 02, 2024Analyzing and finding anomalies in multi-dimensional datasets is a cumbersome but vital task across different domains. In the context of financial fraud detection, analysts must quickly identify suspicious activity among transactional data. This is an iterative process made of complex exploratory tasks such as recognizing patterns, grouping, and comparing. To mitigate the information overload inherent to these steps, we present a tool combining automated information highlights, Large Language Model generated textual insights, and visual analytics, facilitating exploration at different levels of detail. We perform a segmentation of the data per analysis area and visually represent each one, making use of automated visual cues to signal which require more attention. Upon user selection of an area, our system provides textual and graphical summaries. The text, acting as a link between the high-level and detailed views of the chosen segment, allows for a quick understanding of relevant details. A thorough exploration of the data comprising the selection can be done through graphical representations. The feedback gathered in a study performed with seven domain experts suggests our tool effectively supports and guides exploratory analysis, easing the identification of suspicious information.
Cost-Sensitive Learning to Defer to Multiple Experts with Workload Constraints
Mar 21, 2024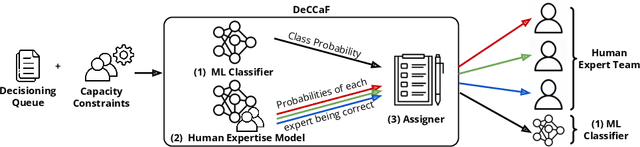
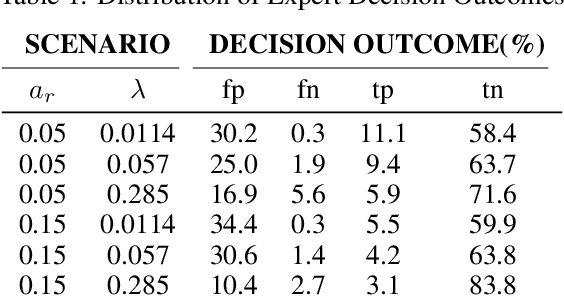
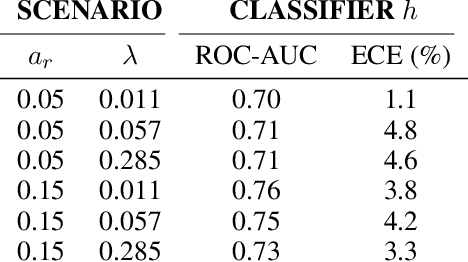
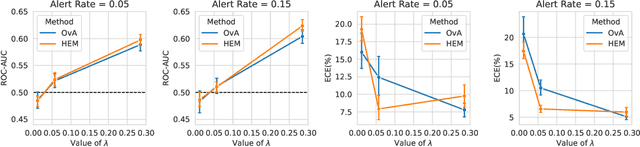
Learning to defer (L2D) aims to improve human-AI collaboration systems by learning how to defer decisions to humans when they are more likely to be correct than an ML classifier. Existing research in L2D overlooks key aspects of real-world systems that impede its practical adoption, namely: i) neglecting cost-sensitive scenarios, where type 1 and type 2 errors have different costs; ii) requiring concurrent human predictions for every instance of the training dataset and iii) not dealing with human work capacity constraints. To address these issues, we propose the deferral under cost and capacity constraints framework (DeCCaF). DeCCaF is a novel L2D approach, employing supervised learning to model the probability of human error under less restrictive data requirements (only one expert prediction per instance) and using constraint programming to globally minimize the error cost subject to workload limitations. We test DeCCaF in a series of cost-sensitive fraud detection scenarios with different teams of 9 synthetic fraud analysts, with individual work capacity constraints. The results demonstrate that our approach performs significantly better than the baselines in a wide array of scenarios, achieving an average 8.4% reduction in the misclassification cost.