 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Sensitive Learning to Defer to Multiple Experts with Workload Constraints
Mar 21, 2024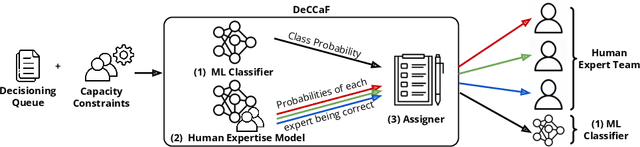
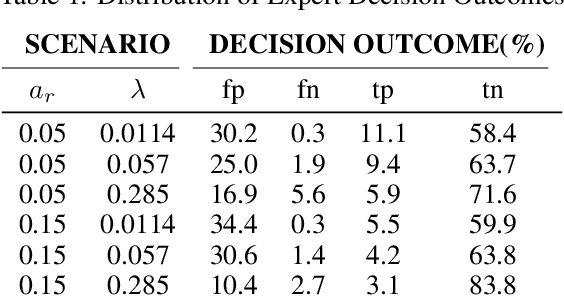
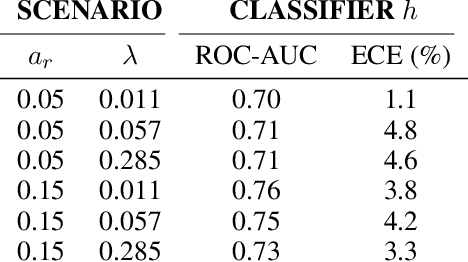
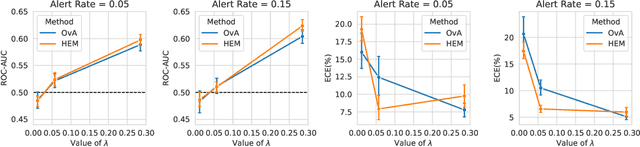
Learning to defer (L2D) aims to improve human-AI collaboration systems by learning how to defer decisions to humans when they are more likely to be correct than an ML classifier. Existing research in L2D overlooks key aspects of real-world systems that impede its practical adoption, namely: i) neglecting cost-sensitive scenarios, where type 1 and type 2 errors have different costs; ii) requiring concurrent human predictions for every instance of the training dataset and iii) not dealing with human work capacity constraints. To address these issues, we propose the deferral under cost and capacity constraints framework (DeCCaF). DeCCaF is a novel L2D approach, employing supervised learning to model the probability of human error under less restrictive data requirements (only one expert prediction per instance) and using constraint programming to globally minimize the error cost subject to workload limitations. We test DeCCaF in a series of cost-sensitive fraud detection scenarios with different teams of 9 synthetic fraud analysts, with individual work capacity constraints. The results demonstrate that our approach performs significantly better than the baselines in a wide array of scenarios, achieving an average 8.4% reduction in the misclassification cost.
FiFAR: A Fraud Detection Dataset for Learning to Defer
Dec 20, 2023Public dataset limitations have significantly hindered the development and benchmarking of learning to defer (L2D) algorithms, which aim to optimally combine human and AI capabilities in hybrid decision-making systems. In such systems, human availability and domain-specific concerns introduce difficulties, while obtaining human predictions for training and evaluation is costly. Financial fraud detection is a high-stakes setting where algorithms and human experts often work in tandem; however, there are no publicly available datasets for L2D concerning this important application of human-AI teaming. To fill this gap in L2D research, we introduce the Financial Fraud Alert Review Dataset (FiFAR), a synthetic bank account fraud detection dataset, containing the predictions of a team of 50 highly complex and varied synthetic fraud analysts, with varied bias and feature dependence. We also provide a realistic definition of human work capacity constraints, an aspect of L2D systems that is often overlooked, allowing for extensive testing of assignment systems under real-world conditions. We use our dataset to develop a capacity-aware L2D method and rejection learning approach under realistic data availability conditions, and benchmark these baselines under an array of 300 distinct testing scenarios. We believe that this dataset will serve as a pivotal instrument in facilitating a systematic, rigorous, reproducible, and transparent evaluation and comparison of L2D methods, thereby fostering the development of more synergistic human-AI collaboration in decision-making systems. The public dataset and detailed synthetic expert information are available at: https://github.com/feedzai/fifar-dataset