 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the truncation gap: challenges of learning on dynamic graphs with recurrent architectures
Dec 30, 2024



Systems characterized by evolving interactions, prevalent in social, financial, and biological domains, are effectively modeled as continuous-time dynamic graphs (CTDGs). To manage the scale and complexity of these graph datasets, machine learning (ML) approaches have become essential. However, CTDGs pose challenges for ML because traditional static graph methods do not naturally account for event timings. Newer approaches, such as graph recurrent neural networks (GRNNs), are inherently time-aware and offer advantages over static methods for CTDGs. However, GRNNs face another issue: the short truncation of backpropagation-through-time (BPTT), whose impact has not been properly examined until now. In this work, we demonstrate that this truncation can limit the learning of dependencies beyond a single hop, resulting in reduced performance. Through experiments on a novel synthetic task and real-world datasets, we reveal a performance gap between full backpropagation-through-time (F-BPTT) and the truncated backpropagation-through-time (T-BPTT) commonly used to train GRNN models. We term this gap the "truncation gap" and argue that understanding and addressing it is essential as the importance of CTDGs grows, discussing potential future directions for research in this area.
Fair-OBNC: Correcting Label Noise for Fairer Datasets
Oct 08, 2024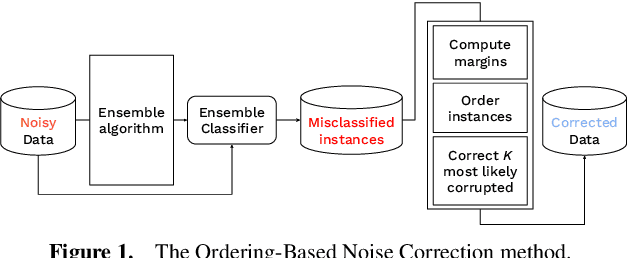
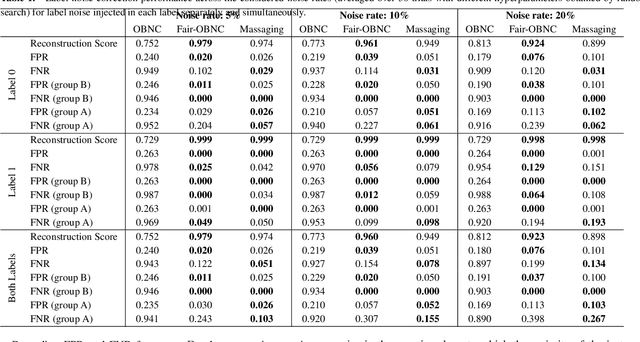
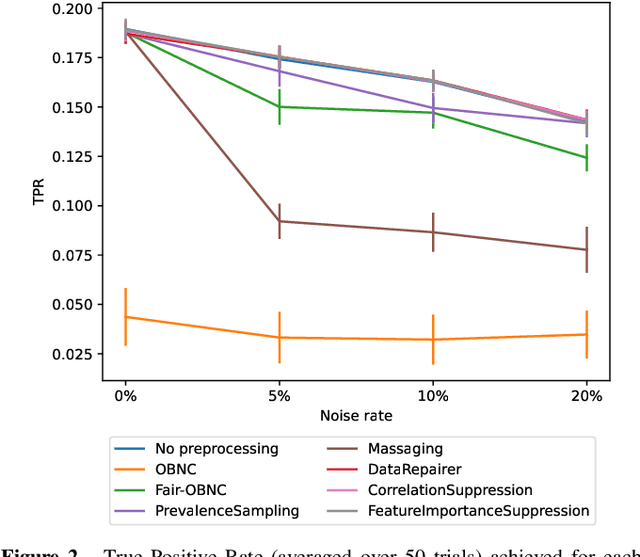
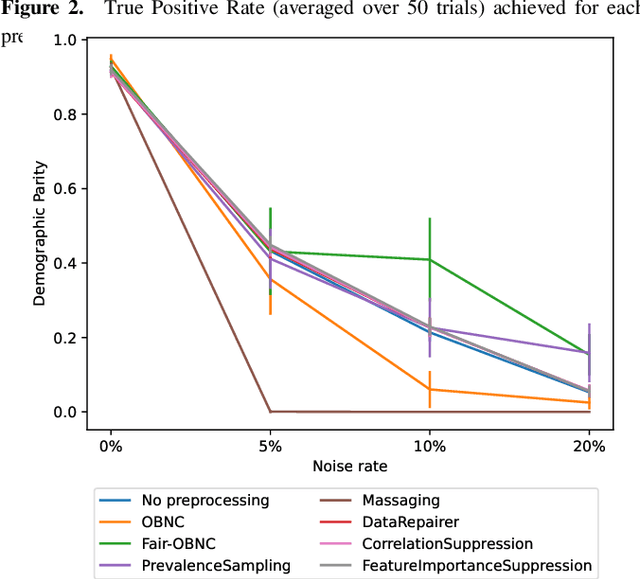
Data used by automated decision-making systems, such as Machine Learning models, often reflects discriminatory behavior that occurred in the past. These biases in the training data are sometimes related to label noise, such as in COMPAS, where more African-American offenders are wrongly labeled as having a higher risk of recidivism when compared to their White counterparts. Models trained on such biased data may perpetuate or even aggravate the biases with respect to sensitive information, such as gender, race, or age. However, while multiple label noise correction approaches are available in the literature, these focus on model performance exclusively. In this work, we propose Fair-OBNC, a label noise correction method with fairness considerations, to produce training datasets with measurable demographic parity. The presented method adapts Ordering-Based Noise Correction, with an adjusted criterion of ordering, based both on the margin of error of an ensemble, and the potential increase in the observed demographic parity of the dataset. We evaluate Fair-OBNC against other different pre-processing techniques, under different scenarios of controlled label noise. Our results show that the proposed method is the overall better alternative within the pool of label correction methods, being capable of attaining better reconstructions of the original labels. Models trained in the corrected data have an increase, on average, of 150% in demographic parity, when compared to models trained in data with noisy labels, across the considered levels of label noise.
Aequitas Flow: Streamlining Fair ML Experimentation
May 09, 2024Aequitas Flow is an open-source framework for end-to-end Fair Machine Learning (ML) experimentation in Python. This package fills the existing integration gaps in other Fair ML packages of complete and accessible experimentation. It provides a pipeline for fairness-aware model training, hyperparameter optimization, and evaluation, enabling rapid and simple experiments and result analysis. Aimed at ML practitioners and researchers, the framework offers implementations of methods, datasets, metrics, and standard interfaces for these components to improve extensibility. By facilitating the development of fair ML practices, Aequitas Flow seeks to enhance the adoption of these concepts in AI technologies.
Cost-Sensitive Learning to Defer to Multiple Experts with Workload Constraints
Mar 21, 2024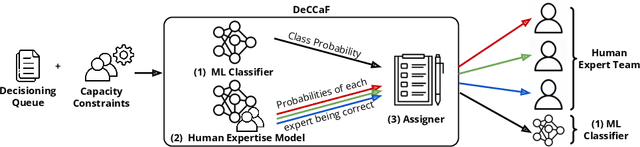
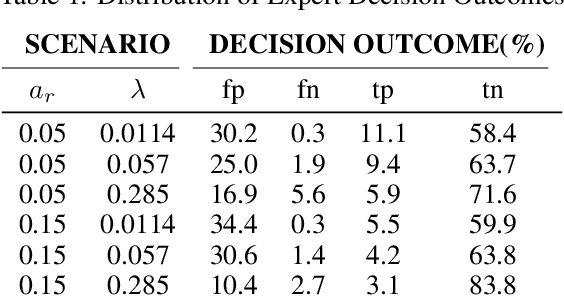
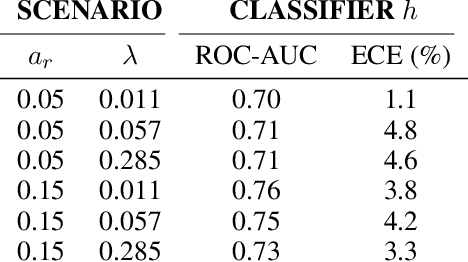
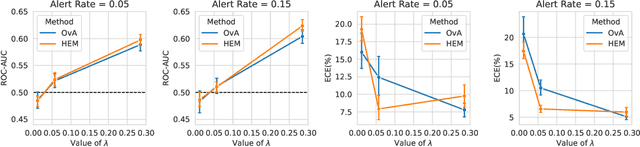
Learning to defer (L2D) aims to improve human-AI collaboration systems by learning how to defer decisions to humans when they are more likely to be correct than an ML classifier. Existing research in L2D overlooks key aspects of real-world systems that impede its practical adoption, namely: i) neglecting cost-sensitive scenarios, where type 1 and type 2 errors have different costs; ii) requiring concurrent human predictions for every instance of the training dataset and iii) not dealing with human work capacity constraints. To address these issues, we propose the deferral under cost and capacity constraints framework (DeCCaF). DeCCaF is a novel L2D approach, employing supervised learning to model the probability of human error under less restrictive data requirements (only one expert prediction per instance) and using constraint programming to globally minimize the error cost subject to workload limitations. We test DeCCaF in a series of cost-sensitive fraud detection scenarios with different teams of 9 synthetic fraud analysts, with individual work capacity constraints. The results demonstrate that our approach performs significantly better than the baselines in a wide array of scenarios, achieving an average 8.4% reduction in the misclassification cost.
DiConStruct: Causal Concept-based Explanations through Black-Box Distillation
Jan 26, 2024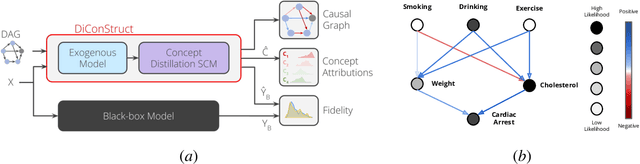
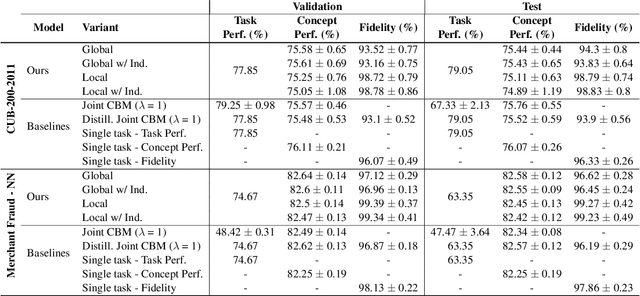
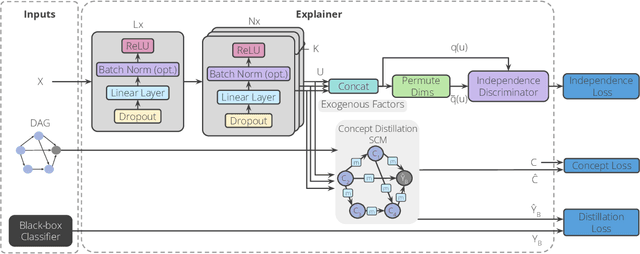
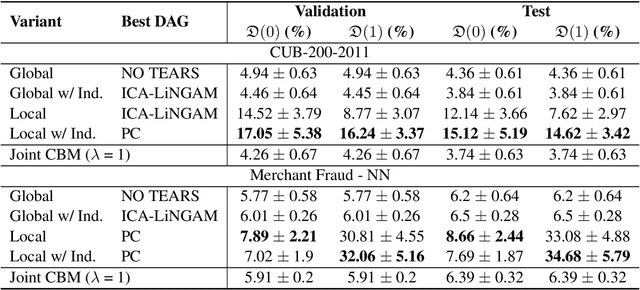
Model interpretability plays a central role in human-AI decision-making systems. Ideally, explanations should be expressed using human-interpretable semantic concepts. Moreover, the causal relations between these concepts should be captured by the explainer to allow for reasoning about the explanations. Lastly, explanation methods should be efficient and not compromise the performance of the predictive task. Despite the rapid advances in AI explainability in recent years, as far as we know to date, no method fulfills these three properties. Indeed, mainstream methods for local concept explainability do not produce causal explanations and incur a trade-off between explainability and prediction performance. We present DiConStruct, an explanation method that is both concept-based and causal, with the goal of creating more interpretable local explanations in the form of structural causal models and concept attributions. Our explainer works as a distillation model to any black-box machine learning model by approximating its predictions while producing the respective explanations. Because of this, DiConStruct generates explanations efficiently while not impacting the black-box prediction task. We validate our method on an image dataset and a tabular dataset, showing that DiConStruct approximates the black-box models with higher fidelity than other concept explainability baselines, while providing explanations that include the causal relations between the concepts.
FiFAR: A Fraud Detection Dataset for Learning to Defer
Dec 20, 2023Public dataset limitations have significantly hindered the development and benchmarking of learning to defer (L2D) algorithms, which aim to optimally combine human and AI capabilities in hybrid decision-making systems. In such systems, human availability and domain-specific concerns introduce difficulties, while obtaining human predictions for training and evaluation is costly. Financial fraud detection is a high-stakes setting where algorithms and human experts often work in tandem; however, there are no publicly available datasets for L2D concerning this important application of human-AI teaming. To fill this gap in L2D research, we introduce the Financial Fraud Alert Review Dataset (FiFAR), a synthetic bank account fraud detection dataset, containing the predictions of a team of 50 highly complex and varied synthetic fraud analysts, with varied bias and feature dependence. We also provide a realistic definition of human work capacity constraints, an aspect of L2D systems that is often overlooked, allowing for extensive testing of assignment systems under real-world conditions. We use our dataset to develop a capacity-aware L2D method and rejection learning approach under realistic data availability conditions, and benchmark these baselines under an array of 300 distinct testing scenarios. We believe that this dataset will serve as a pivotal instrument in facilitating a systematic, rigorous, reproducible, and transparent evaluation and comparison of L2D methods, thereby fostering the development of more synergistic human-AI collaboration in decision-making systems. The public dataset and detailed synthetic expert information are available at: https://github.com/feedzai/fifar-dataset
Fairness-Aware Data Valuation for Supervised Learning
Mar 29, 2023


Data valuation is a ML field that studies the value of training instances towards a given predictive task. Although data bias is one of the main sources of downstream model unfairness, previous work in data valuation does not consider how training instances may influence both performance and fairness of ML models. Thus, we propose Fairness-Aware Data vauatiOn (FADO), a data valuation framework that can be used to incorporate fairness concerns into a series of ML-related tasks (e.g., data pre-processing, exploratory data analysis, active learning). We propose an entropy-based data valuation metric suited to address our two-pronged goal of maximizing both performance and fairness, which is more computationally efficient than existing metrics. We then show how FADO can be applied as the basis for unfairness mitigation pre-processing techniques. Our methods achieve promising results -- up to a 40 p.p. improvement in fairness at a less than 1 p.p. loss in performance compared to a baseline -- and promote fairness in a data-centric way, where a deeper understanding of data quality takes center stage.
A Case Study on Designing Evaluations of ML Explanations with Simulated User Studies
Feb 15, 2023When conducting user studies to ascertain the usefulness of model explanations in aiding human decision-making, it is important to use real-world use cases, data, and users. However, this process can be resource-intensive, allowing only a limited number of explanation methods to be evaluated. Simulated user evaluations (SimEvals), which use machine learning models as a proxy for human users, have been proposed as an intermediate step to select promising explanation methods. In this work, we conduct the first SimEvals on a real-world use case to evaluate whether explanations can better support ML-assisted decision-making in e-commerce fraud detection. We study whether SimEvals can corroborate findings from a user study conducted in this fraud detection context. In particular, we find that SimEvals suggest that all considered explainers are equally performant, and none beat a baseline without explanations -- this matches the conclusions of the original user study. Such correspondences between our results and the original user study provide initial evidence in favor of using SimEvals before running user studies. We also explore the use of SimEvals as a cheap proxy to explore an alternative user study set-up. We hope that this work motivates further study of when and how SimEvals should be used to aid in the design of real-world evaluations.
Turning the Tables: Biased, Imbalanced, Dynamic Tabular Datasets for ML Evaluation
Nov 28, 2022Evaluating new techniques on realistic datasets plays a crucial role in the development of ML research and its broader adoption by practitioners. In recent years, there has been a significant increase of publicly available unstructured data resources for computer vision and NLP tasks. However, tabular data -- which is prevalent in many high-stakes domains -- has been lagging behind. To bridge this gap, we present Bank Account Fraud (BAF), the first publicly available privacy-preserving, large-scale, realistic suite of tabular datasets. The suite was generated by applying state-of-the-art tabular data generation techniques on an anonymized,real-world bank account opening fraud detection dataset. This setting carries a set of challenges that are commonplace in real-world applications, including temporal dynamics and significant class imbalance. Additionally, to allow practitioners to stress test both performance and fairness of ML methods, each dataset variant of BAF contains specific types of data bias. With this resource, we aim to provide the research community with a more realistic, complete, and robust test bed to evaluate novel and existing methods.
LaundroGraph: Self-Supervised Graph Representation Learning for Anti-Money Laundering
Oct 25, 2022Anti-money laundering (AML) regulations mandate financial institutions to deploy AML systems based on a set of rules that, when triggered, form the basis of a suspicious alert to be assessed by human analysts. Reviewing these cases is a cumbersome and complex task that requires analysts to navigate a large network of financial interactions to validate suspicious movements. Furthermore, these systems have very high false positive rates (estimated to be over 95\%). The scarcity of labels hinders the use of alternative systems based on supervised learning, reducing their applicability in real-world applications. In this work we present LaundroGraph, a novel self-supervised graph representation learning approach to encode banking customers and financial transactions into meaningful representations. These representations are used to provide insights to assist the AML reviewing process, such as identifying anomalous movements for a given customer. LaundroGraph represents the underlying network of financial interactions as a customer-transaction bipartite graph and trains a graph neural network on a fully self-supervised link prediction task. We empirically demonstrate that our approach outperforms other strong baselines on self-supervised link prediction using a real-world dataset, improving the best non-graph baseline by $12$ p.p. of AUC. The goal is to increase the efficiency of the reviewing process by supplying these AI-powered insights to the analysts upon review. To the best of our knowledge, this is the first fully self-supervised system within the context of AML detection.