 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiConStruct: Causal Concept-based Explanations through Black-Box Distillation
Jan 26, 2024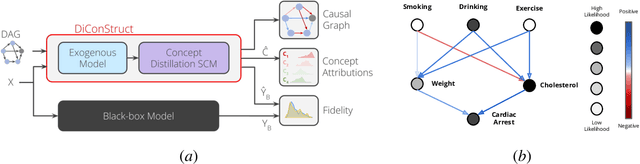
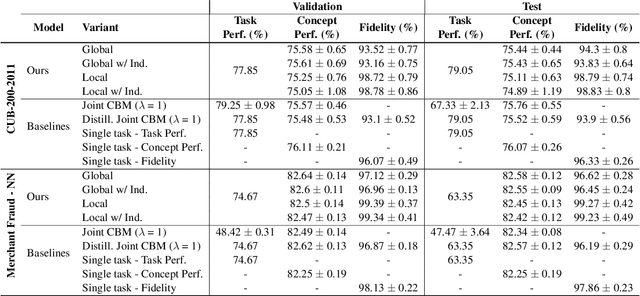
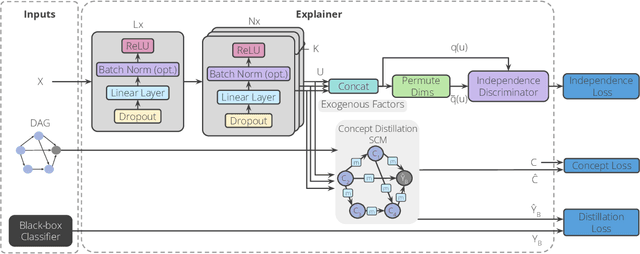
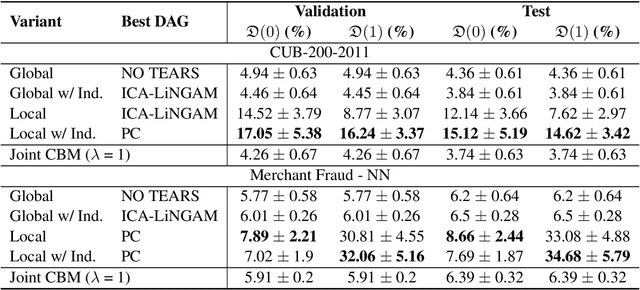
Model interpretability plays a central role in human-AI decision-making systems. Ideally, explanations should be expressed using human-interpretable semantic concepts. Moreover, the causal relations between these concepts should be captured by the explainer to allow for reasoning about the explanations. Lastly, explanation methods should be efficient and not compromise the performance of the predictive task. Despite the rapid advances in AI explainability in recent years, as far as we know to date, no method fulfills these three properties. Indeed, mainstream methods for local concept explainability do not produce causal explanations and incur a trade-off between explainability and prediction performance. We present DiConStruct, an explanation method that is both concept-based and causal, with the goal of creating more interpretable local explanations in the form of structural causal models and concept attributions. Our explainer works as a distillation model to any black-box machine learning model by approximating its predictions while producing the respective explanations. Because of this, DiConStruct generates explanations efficiently while not impacting the black-box prediction task. We validate our method on an image dataset and a tabular dataset, showing that DiConStruct approximates the black-box models with higher fidelity than other concept explainability baselines, while providing explanations that include the causal relations between the concepts.
LaundroGraph: Self-Supervised Graph Representation Learning for Anti-Money Laundering
Oct 25, 2022Anti-money laundering (AML) regulations mandate financial institutions to deploy AML systems based on a set of rules that, when triggered, form the basis of a suspicious alert to be assessed by human analysts. Reviewing these cases is a cumbersome and complex task that requires analysts to navigate a large network of financial interactions to validate suspicious movements. Furthermore, these systems have very high false positive rates (estimated to be over 95\%). The scarcity of labels hinders the use of alternative systems based on supervised learning, reducing their applicability in real-world applications. In this work we present LaundroGraph, a novel self-supervised graph representation learning approach to encode banking customers and financial transactions into meaningful representations. These representations are used to provide insights to assist the AML reviewing process, such as identifying anomalous movements for a given customer. LaundroGraph represents the underlying network of financial interactions as a customer-transaction bipartite graph and trains a graph neural network on a fully self-supervised link prediction task. We empirically demonstrate that our approach outperforms other strong baselines on self-supervised link prediction using a real-world dataset, improving the best non-graph baseline by $12$ p.p. of AUC. The goal is to increase the efficiency of the reviewing process by supplying these AI-powered insights to the analysts upon review. To the best of our knowledge, this is the first fully self-supervised system within the context of AML detection.
Modeling the geospatial evolution of COVID-19 using spatio-temporal convolutional sequence-to-sequence neural networks
May 06, 2021
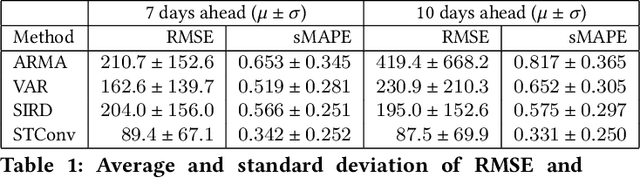
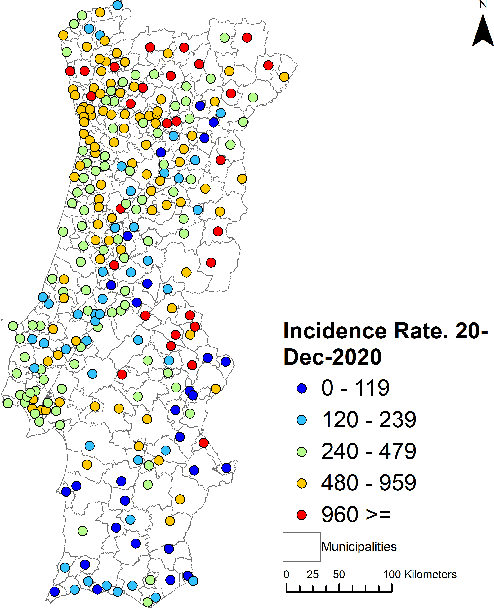
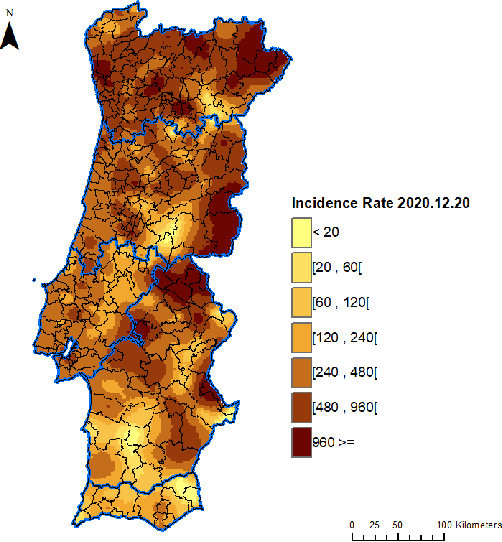
Europe was hit hard by the COVID-19 pandemic and Portugal was one of the most affected countries, having suffered three waves in the first twelve months. Approximately between Jan 19th and Feb 5th 2021 Portugal was the country in the world with the largest incidence rate, with 14-days incidence rates per 100,000 inhabitants in excess of 1000. Despite its importance, accurate prediction of the geospatial evolution of COVID-19 remains a challenge, since existing analytical methods fail to capture the complex dynamics that result from both the contagion within a region and the spreading of the infection from infected neighboring regions. We use a previously developed methodology and official municipality level data from the Portuguese Directorate-General for Health (DGS), relative to the first twelve months of the pandemic, to compute an estimate of the incidence rate in each location of mainland Portugal. The resulting sequence of incidence rate maps was then used as a gold standard to test the effectiveness of different approaches in the prediction of the spatial-temporal evolution of the incidence rate. Four different methods were tested: a simple cell level autoregressive moving average (ARMA) model, a cell level vector autoregressive (VAR) model, a municipality-by-municipality compartmental SIRD model followed by direct block sequential simulation and a convolutional sequence-to-sequence neural network model based on the STConvS2S architecture. We conclude that the convolutional sequence-to-sequence neural network is the best performing method, when predicting the medium-term future incidence rate, using the available information.