 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRECAP: Reproducing Copyrighted Data from LLMs Training with an Agentic Pipeline
Oct 29, 2025If we cannot inspect the training data of a large language model (LLM), how can we ever know what it has seen? We believe the most compelling evidence arises when the model itself freely reproduces the target content. As such, we propose RECAP, an agentic pipeline designed to elicit and verify memorized training data from LLM outputs. At the heart of RECAP is a feedback-driven loop, where an initial extraction attempt is evaluated by a secondary language model, which compares the output against a reference passage and identifies discrepancies. These are then translated into minimal correction hints, which are fed back into the target model to guide subsequent generations. In addition, to address alignment-induced refusals, RECAP includes a jailbreaking module that detects and overcomes such barriers. We evaluate RECAP on EchoTrace, a new benchmark spanning over 30 full books, and the results show that RECAP leads to substantial gains over single-iteration approaches. For instance, with GPT-4.1, the average ROUGE-L score for the copyrighted text extraction improved from 0.38 to 0.47 - a nearly 24% increase.
Deep Feedback Models
Sep 19, 2025Deep Feedback Models (DFMs) are a new class of stateful neural networks that combine bottom up input with high level representations over time. This feedback mechanism introduces dynamics into otherwise static architectures, enabling DFMs to iteratively refine their internal state and mimic aspects of biological decision making. We model this process as a differential equation solved through a recurrent neural network, stabilized via exponential decay to ensure convergence. To evaluate their effectiveness, we measure DFMs under two key conditions: robustness to noise and generalization with limited data. In both object recognition and segmentation tasks, DFMs consistently outperform their feedforward counterparts, particularly in low data or high noise regimes. In addition, DFMs translate to medical imaging settings, while being robust against various types of noise corruption. These findings highlight the importance of feedback in achieving stable, robust, and generalizable learning. Code is available at https://github.com/DCalhas/deep_feedback_models.
CountPath: Automating Fragment Counting in Digital Pathology
Mar 13, 2025Quality control of medical images is a critical component of digital pathology, ensuring that diagnostic images meet required standards. A pre-analytical task within this process is the verification of the number of specimen fragments, a process that ensures that the number of fragments on a slide matches the number documented in the macroscopic report. This step is important to ensure that the slides contain the appropriate diagnostic material from the grossing process, thereby guaranteeing the accuracy of subsequent microscopic examination and diagnosis. Traditionally, this assessment is performed manually, requiring significant time and effort while being subject to significant variability due to its subjective nature. To address these challenges, this study explores an automated approach to fragment counting using the YOLOv9 and Vision Transformer models. Our results demonstrate that the automated system achieves a level of performance comparable to expert assessments, offering a reliable and efficient alternative to manual counting. Additionally, we present findings on interobserver variability, showing that the automated approach achieves an accuracy of 86%, which falls within the range of variation observed among experts (82-88%), further supporting its potential for integration into routine pathology workflows.
Are ECGs enough? Deep learning classification of cardiac anomalies using only electrocardiograms
Mar 11, 2025Electrocardiography (ECG) is an essential tool for diagnosing multiple cardiac anomalies: it provides valuable clinical insights, while being affordable, fast and available in many settings. However, in the current literature, the role of ECG analysis is often unclear: many approaches either rely on additional imaging modalities, such as Computed Tomography Pulmonary Angiography (CTPA), which may not always be available, or do not effectively generalize across different classification problems. Furthermore, the availability of public ECG datasets is limited and, in practice, these datasets tend to be small, making it essential to optimize learning strategies. In this study, we investigate the performance of multiple neural network architectures in order to assess the impact of various approaches. Moreover, we check whether these practices enhance model generalization when transfer learning is used to translate information learned in larger ECG datasets, such as PTB-XL and CPSC18, to a smaller, more challenging dataset for pulmonary embolism (PE) detection. By leveraging transfer learning, we analyze the extent to which we can improve learning efficiency and predictive performance on limited data. Code available at https://github.com/joaodsmarques/Are-ECGs-enough-Deep-Learning-Classifiers .
DIS-CO: Discovering Copyrighted Content in VLMs Training Data
Feb 25, 2025How can we verify whether copyrighted content was used to train a large vision-language model (VLM) without direct access to its training data? Motivated by the hypothesis that a VLM is able to recognize images from its training corpus, we propose DIS-CO, a novel approach to infer the inclusion of copyrighted content during the model's development. By repeatedly querying a VLM with specific frames from targeted copyrighted material, DIS-CO extracts the content's identity through free-form text completions. To assess its effectiveness, we introduce MovieTection, a benchmark comprising 14,000 frames paired with detailed captions, drawn from films released both before and after a model's training cutoff. Our results show that DIS-CO significantly improves detection performance, nearly doubling the average AUC of the best prior method on models with logits available. Our findings also highlight a broader concern: all tested models appear to have been exposed to some extent to copyrighted content. Our code and data are available at https://github.com/avduarte333/DIS-CO
The Role of Recurrency in Image Segmentation for Noisy and Limited Sample Settings
Dec 20, 2024The biological brain has inspired multiple advances in machine learning. However, most state-of-the-art models in computer vision do not operate like the human brain, simply because they are not capable of changing or improving their decisions/outputs based on a deeper analysis. The brain is recurrent, while these models are not. It is therefore relevant to explore what would be the impact of adding recurrent mechanisms to existing state-of-the-art architectures and to answer the question of whether recurrency can improve existing architectures. To this end, we build on a feed-forward segmentation model and explore multiple types of recurrency for image segmentation. We explore self-organizing, relational, and memory retrieval types of recurrency that minimize a specific energy function. In our experiments, we tested these models on artificial and medical imaging data, while analyzing the impact of high levels of noise and few-shot learning settings. Our results do not validate our initial hypothesis that recurrent models should perform better in these settings, suggesting that these recurrent architectures, by themselves, are not sufficient to surpass state-of-the-art feed-forward versions and that additional work needs to be done on the topic.
Explicitly Modeling Pre-Cortical Vision with a Neuro-Inspired Front-End Improves CNN Robustness
Sep 25, 2024While convolutional neural networks (CNNs) excel at clean image classification, they struggle to classify images corrupted with different common corruptions, limiting their real-world applicability. Recent work has shown that incorporating a CNN front-end block that simulates some features of the primate primary visual cortex (V1) can improve overall model robustness. Here, we expand on this approach by introducing two novel biologically-inspired CNN model families that incorporate a new front-end block designed to simulate pre-cortical visual processing. RetinaNet, a hybrid architecture containing the novel front-end followed by a standard CNN back-end, shows a relative robustness improvement of 12.3% when compared to the standard model; and EVNet, which further adds a V1 block after the pre-cortical front-end, shows a relative gain of 18.5%. The improvement in robustness was observed for all the different corruption categories, though accompanied by a small decrease in clean image accuracy, and generalized to a different back-end architecture. These findings show that simulating multiple stages of early visual processing in CNN early layers provides cumulative benefits for model robustness.
LumberChunker: Long-Form Narrative Document Segmentation
Jun 25, 2024Modern NLP tasks increasingly rely on dense retrieval methods to access up-to-date and relevant contextual information. We are motivated by the premise that retrieval benefits from segments that can vary in size such that a content's semantic independence is better captured. We propose LumberChunker, a method leveraging an LLM to dynamically segment documents, which iteratively prompts the LLM to identify the point within a group of sequential passages where the content begins to shift. To evaluate our method, we introduce GutenQA, a benchmark with 3000 "needle in a haystack" type of question-answer pairs derived from 100 public domain narrative books available on Project Gutenberg. Our experiments show that LumberChunker not only outperforms the most competitive baseline by 7.37% in retrieval performance (DCG@20) but also that, when integrated into a RAG pipeline, LumberChunker proves to be more effective than other chunking methods and competitive baselines, such as the Gemini 1.5M Pro. Our Code and Data are available at https://github.com/joaodsmarques/LumberChunker
Finding Regions of Interest in Whole Slide Images Using Multiple Instance Learning
Apr 11, 2024Whole Slide Images (WSI), obtained by high-resolution digital scanning of microscope slides at multiple scales, are the cornerstone of modern Digital Pathology. However, they represent a particular challenge to AI-based/AI-mediated analysis because pathology labeling is typically done at slide-level, instead of tile-level. It is not just that medical diagnostics is recorded at the specimen level, the detection of oncogene mutation is also experimentally obtained, and recorded by initiatives like The Cancer Genome Atlas (TCGA), at the slide level. This configures a dual challenge: a) accurately predicting the overall cancer phenotype and b) finding out what cellular morphologies are associated with it at the tile level. To address these challenges, a weakly supervised Multiple Instance Learning (MIL) approach was explored for two prevalent cancer types, Invasive Breast Carcinoma (TCGA-BRCA) and Lung Squamous Cell Carcinoma (TCGA-LUSC). This approach was explored for tumor detection at low magnification levels and TP53 mutations at various levels. Our results show that a novel additive implementation of MIL matched the performance of reference implementation (AUC 0.96), and was only slightly outperformed by Attention MIL (AUC 0.97). More interestingly from the perspective of the molecular pathologist, these different AI architectures identify distinct sensitivities to morphological features (through the detection of Regions of Interest, RoI) at different amplification levels. Tellingly, TP53 mutation was most sensitive to features at the higher applications where cellular morphology is resolved.
DE-COP: Detecting Copyrighted Content in Language Models Training Data
Feb 15, 2024


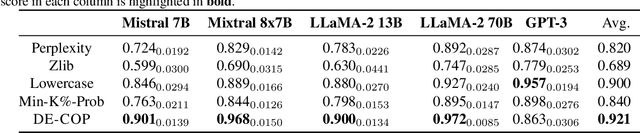
How can we detect if copyrighted content was used in the training process of a language model, considering that the training data is typically undisclosed? We are motivated by the premise that a language model is likely to identify verbatim excerpts from its training text. We propose DE-COP, a method to determine whether a piece of copyrighted content was included in training. DE-COP's core approach is to probe an LLM with multiple-choice questions, whose options include both verbatim text and their paraphrases. We construct BookTection, a benchmark with excerpts from 165 books published prior and subsequent to a model's training cutoff, along with their paraphrases. Our experiments show that DE-COP surpasses the prior best method by 9.6% in detection performance (AUC) on models with logits available. Moreover, DE-COP also achieves an average accuracy of 72% for detecting suspect books on fully black-box models where prior methods give $\approx$ 4% accuracy. Our code and datasets are available at https://github.com/avduarte333/DE-COP_Method