 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSem-Detect: Semantic Level Detection of AI Generated Peer-Reviews
May 20, 2026How can we distinguish whether a peer review was written by a human or generated by an AI model? We argue that, in this setting, authorship should not be attributed solely from the textual features of a review, but also from the ideas, judgments, and claims it expresses. To this end, we propose Sem-Detect, an authorship detection method for peer reviews that operationalizes this principle by combining textual features with claim-level semantic analysis. Sem-Detect compares a target review against multiple AI-generated reviews of the same paper, leveraging the observation that different AI models tend to converge on similar points, while human reviewers introduce more unique and diverse ones. As a result, Sem-Detect is able to distinguish fully AI reviews from authentic human-written ones, including those that have been refined using an LLM but still reflect human judgment. Across a dataset of over 20,000 peer reviews from ICLR and NeurIPS conferences, Sem-Detect improves over the strongest baseline by 25.5% in TPR@0.1% FPR in the binary setting. Moreover, in the three-class scenario, we empirically show that LLM refinement preserves the semantic signals of human reviews, which remain distinct from the patterns exhibited by fully AI-generated text; as a result, fewer than 3.5% of LLM-refined human reviews are misclassified as AI-generated.
RECAP: Reproducing Copyrighted Data from LLMs Training with an Agentic Pipeline
Oct 29, 2025If we cannot inspect the training data of a large language model (LLM), how can we ever know what it has seen? We believe the most compelling evidence arises when the model itself freely reproduces the target content. As such, we propose RECAP, an agentic pipeline designed to elicit and verify memorized training data from LLM outputs. At the heart of RECAP is a feedback-driven loop, where an initial extraction attempt is evaluated by a secondary language model, which compares the output against a reference passage and identifies discrepancies. These are then translated into minimal correction hints, which are fed back into the target model to guide subsequent generations. In addition, to address alignment-induced refusals, RECAP includes a jailbreaking module that detects and overcomes such barriers. We evaluate RECAP on EchoTrace, a new benchmark spanning over 30 full books, and the results show that RECAP leads to substantial gains over single-iteration approaches. For instance, with GPT-4.1, the average ROUGE-L score for the copyrighted text extraction improved from 0.38 to 0.47 - a nearly 24% increase.
DIS-CO: Discovering Copyrighted Content in VLMs Training Data
Feb 25, 2025How can we verify whether copyrighted content was used to train a large vision-language model (VLM) without direct access to its training data? Motivated by the hypothesis that a VLM is able to recognize images from its training corpus, we propose DIS-CO, a novel approach to infer the inclusion of copyrighted content during the model's development. By repeatedly querying a VLM with specific frames from targeted copyrighted material, DIS-CO extracts the content's identity through free-form text completions. To assess its effectiveness, we introduce MovieTection, a benchmark comprising 14,000 frames paired with detailed captions, drawn from films released both before and after a model's training cutoff. Our results show that DIS-CO significantly improves detection performance, nearly doubling the average AUC of the best prior method on models with logits available. Our findings also highlight a broader concern: all tested models appear to have been exposed to some extent to copyrighted content. Our code and data are available at https://github.com/avduarte333/DIS-CO
LumberChunker: Long-Form Narrative Document Segmentation
Jun 25, 2024Modern NLP tasks increasingly rely on dense retrieval methods to access up-to-date and relevant contextual information. We are motivated by the premise that retrieval benefits from segments that can vary in size such that a content's semantic independence is better captured. We propose LumberChunker, a method leveraging an LLM to dynamically segment documents, which iteratively prompts the LLM to identify the point within a group of sequential passages where the content begins to shift. To evaluate our method, we introduce GutenQA, a benchmark with 3000 "needle in a haystack" type of question-answer pairs derived from 100 public domain narrative books available on Project Gutenberg. Our experiments show that LumberChunker not only outperforms the most competitive baseline by 7.37% in retrieval performance (DCG@20) but also that, when integrated into a RAG pipeline, LumberChunker proves to be more effective than other chunking methods and competitive baselines, such as the Gemini 1.5M Pro. Our Code and Data are available at https://github.com/joaodsmarques/LumberChunker
DE-COP: Detecting Copyrighted Content in Language Models Training Data
Feb 15, 2024


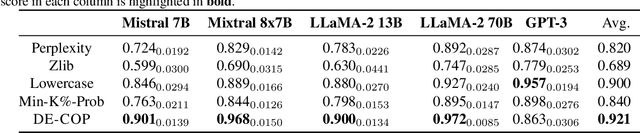
How can we detect if copyrighted content was used in the training process of a language model, considering that the training data is typically undisclosed? We are motivated by the premise that a language model is likely to identify verbatim excerpts from its training text. We propose DE-COP, a method to determine whether a piece of copyrighted content was included in training. DE-COP's core approach is to probe an LLM with multiple-choice questions, whose options include both verbatim text and their paraphrases. We construct BookTection, a benchmark with excerpts from 165 books published prior and subsequent to a model's training cutoff, along with their paraphrases. Our experiments show that DE-COP surpasses the prior best method by 9.6% in detection performance (AUC) on models with logits available. Moreover, DE-COP also achieves an average accuracy of 72% for detecting suspect books on fully black-box models where prior methods give $\approx$ 4% accuracy. Our code and datasets are available at https://github.com/avduarte333/DE-COP_Method
Improving Address Matching using Siamese Transformer Networks
Jul 05, 2023

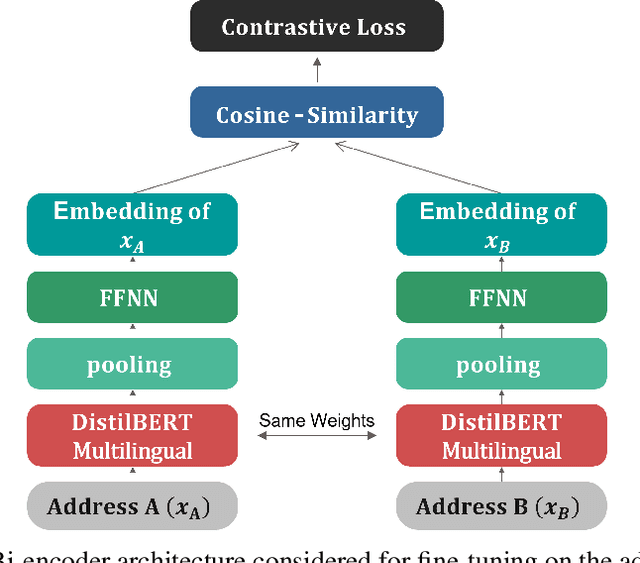
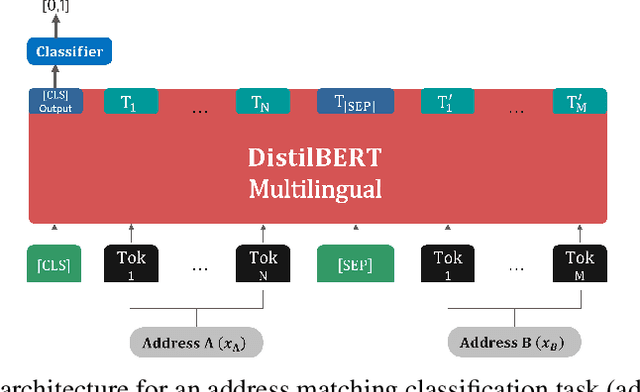
Matching addresses is a critical task for companies and post offices involved in the processing and delivery of packages. The ramifications of incorrectly delivering a package to the wrong recipient are numerous, ranging from harm to the company's reputation to economic and environmental costs. This research introduces a deep learning-based model designed to increase the efficiency of address matching for Portuguese addresses. The model comprises two parts: (i) a bi-encoder, which is fine-tuned to create meaningful embeddings of Portuguese postal addresses, utilized to retrieve the top 10 likely matches of the un-normalized target address from a normalized database, and (ii) a cross-encoder, which is fine-tuned to accurately rerank the 10 addresses obtained by the bi-encoder. The model has been tested on a real-case scenario of Portuguese addresses and exhibits a high degree of accuracy, exceeding 95% at the door level. When utilized with GPU computations, the inference speed is about 4.5 times quicker than other traditional approaches such as BM25. An implementation of this system in a real-world scenario would substantially increase the effectiveness of the distribution process. Such an implementation is currently under investigation.