 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling the geospatial evolution of COVID-19 using spatio-temporal convolutional sequence-to-sequence neural networks
May 06, 2021
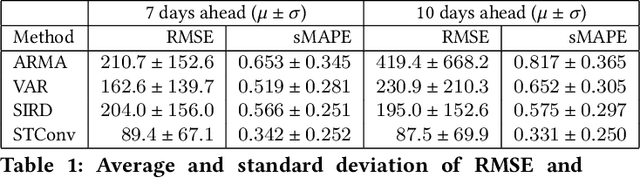
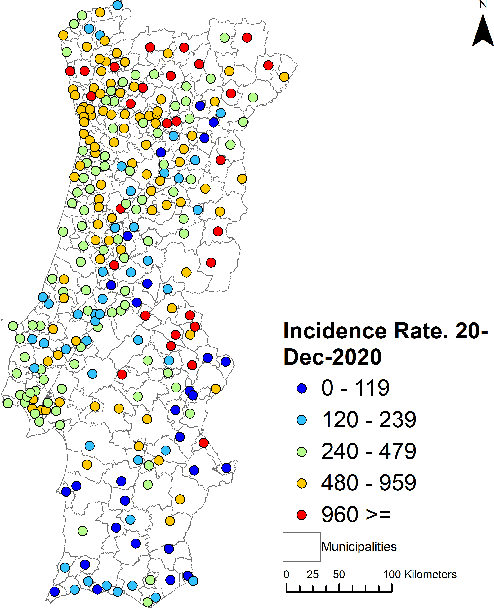
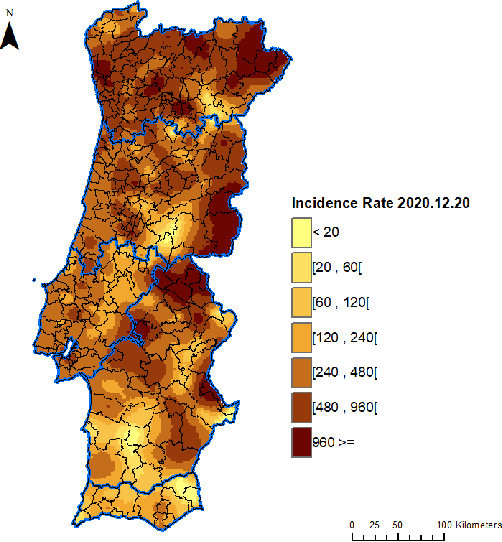
Europe was hit hard by the COVID-19 pandemic and Portugal was one of the most affected countries, having suffered three waves in the first twelve months. Approximately between Jan 19th and Feb 5th 2021 Portugal was the country in the world with the largest incidence rate, with 14-days incidence rates per 100,000 inhabitants in excess of 1000. Despite its importance, accurate prediction of the geospatial evolution of COVID-19 remains a challenge, since existing analytical methods fail to capture the complex dynamics that result from both the contagion within a region and the spreading of the infection from infected neighboring regions. We use a previously developed methodology and official municipality level data from the Portuguese Directorate-General for Health (DGS), relative to the first twelve months of the pandemic, to compute an estimate of the incidence rate in each location of mainland Portugal. The resulting sequence of incidence rate maps was then used as a gold standard to test the effectiveness of different approaches in the prediction of the spatial-temporal evolution of the incidence rate. Four different methods were tested: a simple cell level autoregressive moving average (ARMA) model, a cell level vector autoregressive (VAR) model, a municipality-by-municipality compartmental SIRD model followed by direct block sequential simulation and a convolutional sequence-to-sequence neural network model based on the STConvS2S architecture. We conclude that the convolutional sequence-to-sequence neural network is the best performing method, when predicting the medium-term future incidence rate, using the available information.
Combining Off and On-Policy Training in Model-Based Reinforcement Learning
Feb 24, 2021
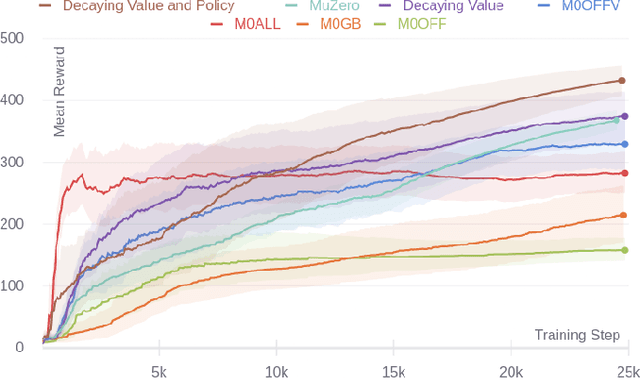

The combination of deep learning and Monte Carlo Tree Search (MCTS) has shown to be effective in various domains, such as board and video games. AlphaGo represented a significant step forward in our ability to learn complex board games, and it was rapidly followed by significant advances, such as AlphaGo Zero and AlphaZero. Recently, MuZero demonstrated that it is possible to master both Atari games and board games by directly learning a model of the environment, which is then used with MCTS to decide what move to play in each position. During tree search, the algorithm simulates games by exploring several possible moves and then picks the action that corresponds to the most promising trajectory. When training, limited use is made of these simulated games since none of their trajectories are directly used as training examples. Even if we consider that not all trajectories from simulated games are useful, there are thousands of potentially useful trajectories that are discarded. Using information from these trajectories would provide more training data, more quickly, leading to faster convergence and higher sample efficiency. Recent work introduced an off-policy value target for AlphaZero that uses data from simulated games. In this work, we propose a way to obtain off-policy targets using data from simulated games in MuZero. We combine these off-policy targets with the on-policy targets already used in MuZero in several ways, and study the impact of these targets and their combinations in three environments with distinct characteristics. When used in the right combinations, our results show that these targets speed up the training process and lead to faster convergence and higher rewards than the ones obtained by MuZero.