 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Off and On-Policy Training in Model-Based Reinforcement Learning
Paper and Code
Feb 24, 2021
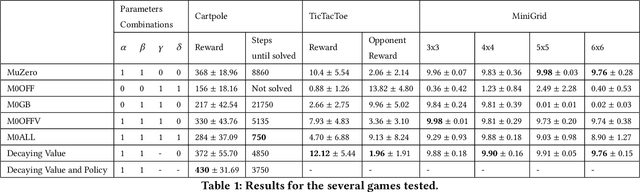
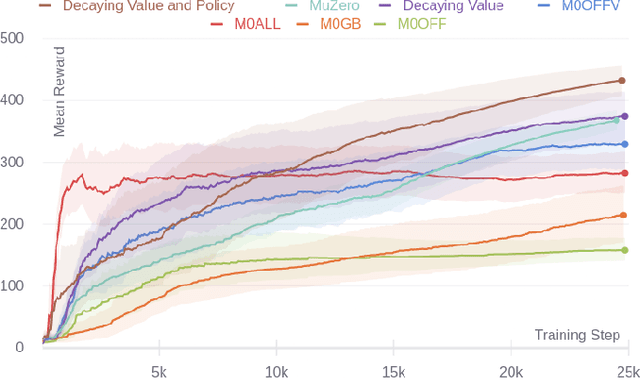

The combination of deep learning and Monte Carlo Tree Search (MCTS) has shown to be effective in various domains, such as board and video games. AlphaGo represented a significant step forward in our ability to learn complex board games, and it was rapidly followed by significant advances, such as AlphaGo Zero and AlphaZero. Recently, MuZero demonstrated that it is possible to master both Atari games and board games by directly learning a model of the environment, which is then used with MCTS to decide what move to play in each position. During tree search, the algorithm simulates games by exploring several possible moves and then picks the action that corresponds to the most promising trajectory. When training, limited use is made of these simulated games since none of their trajectories are directly used as training examples. Even if we consider that not all trajectories from simulated games are useful, there are thousands of potentially useful trajectories that are discarded. Using information from these trajectories would provide more training data, more quickly, leading to faster convergence and higher sample efficiency. Recent work introduced an off-policy value target for AlphaZero that uses data from simulated games. In this work, we propose a way to obtain off-policy targets using data from simulated games in MuZero. We combine these off-policy targets with the on-policy targets already used in MuZero in several ways, and study the impact of these targets and their combinations in three environments with distinct characteristics. When used in the right combinations, our results show that these targets speed up the training process and lead to faster convergence and higher rewards than the ones obtained by MuZero.