 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Importance of Being Statistically Earnest: A Critical Re-evaluation of GSM-Symbolic
May 28, 2026The GSM-Symbolic benchmark (Mirzadeh et al., 2025) reported consistent performance drops across 25 Large Language Models (LLMs) when tested on template-generated variants of GSM8K problems, concluding that the models lack genuine reasoning capabilities. We argue that this conclusion rests on shaky statistical ground. Re-evaluating 20 open-weight models using Generalised Linear Mixed Models with per-question random effects, we find that only half exhibit statistically significant performance changes under the original prompt format. Moreover, we identify a previously unacknowledged factor: the main GSM-Symbolic dataset contains a systematically shifted distribution of larger integers in problem texts relative to GSM-Base (K-S statistic = 0.12, p < 0.001), contradicting the original authors' claims. Controlling for this large number effect accounts for significance in roughly half the remaining cases. Among models with statistically significant performance deltas, we identify distinct, model-specific failure profiles - including fragility of variable binding, arithmetic limitations, and dual-task interference - underscoring that blanket claims about LLM reasoning are both statistically premature and mechanistically misleading.
Graph Neural Networks for Traffic Forecasting
Apr 27, 2021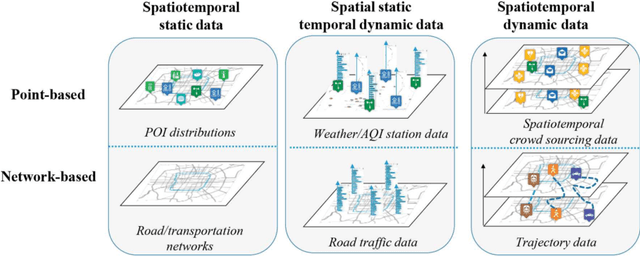
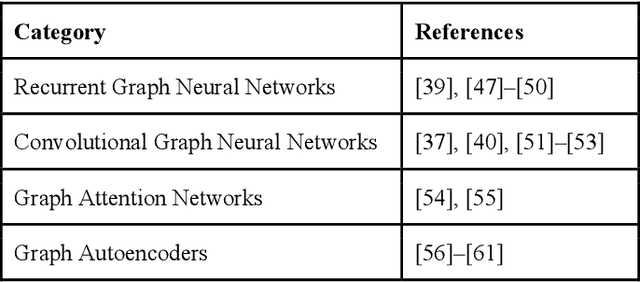

The significant increase in world population and urbanisation has brought several important challenges, in particular regarding the sustainability, maintenance and planning of urban mobility. At the same time, the exponential increase of computing capability and of available sensor and location data have offered the potential for innovative solutions to these challenges. In this work, we focus on the challenge of traffic forecasting and review the recent development and application of graph neural networks (GNN) to this problem. GNNs are a class of deep learning methods that directly process the input as graph data. This leverages more directly the spatial dependencies of traffic data and makes use of the advantages of deep learning producing state-of-the-art results. We introduce and review the emerging topic of GNNs, including their most common variants, with a focus on its application to traffic forecasting. We address the different ways of modelling traffic forecasting as a (temporal) graph, the different approaches developed so far to combine the graph and temporal learning components, as well as current limitations and research opportunities.
Combining Off and On-Policy Training in Model-Based Reinforcement Learning
Feb 24, 2021
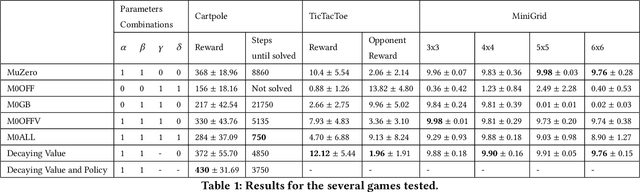
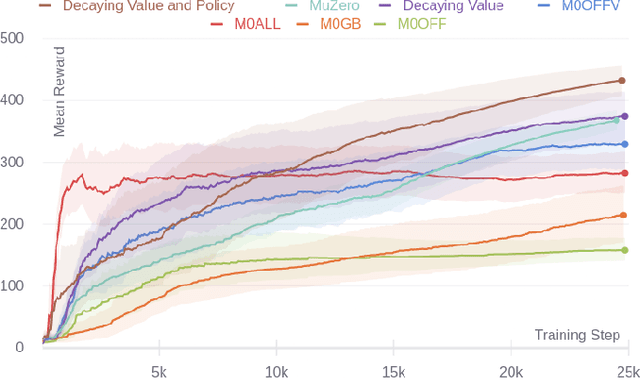

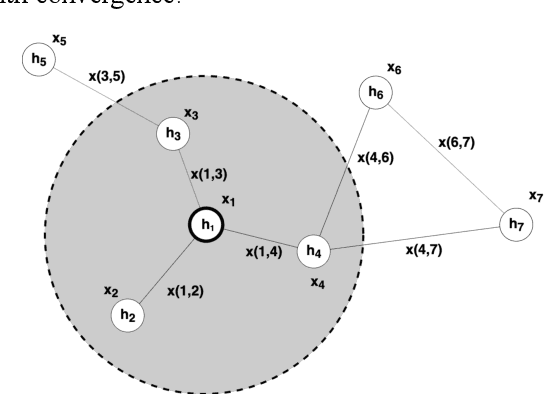
The combination of deep learning and Monte Carlo Tree Search (MCTS) has shown to be effective in various domains, such as board and video games. AlphaGo represented a significant step forward in our ability to learn complex board games, and it was rapidly followed by significant advances, such as AlphaGo Zero and AlphaZero. Recently, MuZero demonstrated that it is possible to master both Atari games and board games by directly learning a model of the environment, which is then used with MCTS to decide what move to play in each position. During tree search, the algorithm simulates games by exploring several possible moves and then picks the action that corresponds to the most promising trajectory. When training, limited use is made of these simulated games since none of their trajectories are directly used as training examples. Even if we consider that not all trajectories from simulated games are useful, there are thousands of potentially useful trajectories that are discarded. Using information from these trajectories would provide more training data, more quickly, leading to faster convergence and higher sample efficiency. Recent work introduced an off-policy value target for AlphaZero that uses data from simulated games. In this work, we propose a way to obtain off-policy targets using data from simulated games in MuZero. We combine these off-policy targets with the on-policy targets already used in MuZero in several ways, and study the impact of these targets and their combinations in three environments with distinct characteristics. When used in the right combinations, our results show that these targets speed up the training process and lead to faster convergence and higher rewards than the ones obtained by MuZero.