 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition Paper on Dataset Engineering to Accelerate Science
Mar 09, 2023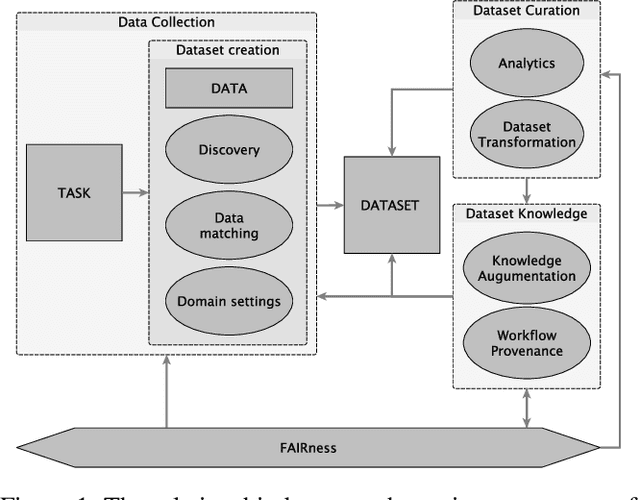
Data is a critical element in any discovery process. In the last decades, we observed exponential growth in the volume of available data and the technology to manipulate it. However, data is only practical when one can structure it for a well-defined task. For instance, we need a corpus of text broken into sentences to train a natural language machine-learning model. In this work, we will use the token \textit{dataset} to designate a structured set of data built to perform a well-defined task. Moreover, the dataset will be used in most cases as a blueprint of an entity that at any moment can be stored as a table. Specifically, in science, each area has unique forms to organize, gather and handle its datasets. We believe that datasets must be a first-class entity in any knowledge-intensive process, and all workflows should have exceptional attention to datasets' lifecycle, from their gathering to uses and evolution. We advocate that science and engineering discovery processes are extreme instances of the need for such organization on datasets, claiming for new approaches and tooling. Furthermore, these requirements are more evident when the discovery workflow uses artificial intelligence methods to empower the subject-matter expert. In this work, we discuss an approach to bringing datasets as a critical entity in the discovery process in science. We illustrate some concepts using material discovery as a use case. We chose this domain because it leverages many significant problems that can be generalized to other science fields.
Modeling the geospatial evolution of COVID-19 using spatio-temporal convolutional sequence-to-sequence neural networks
May 06, 2021
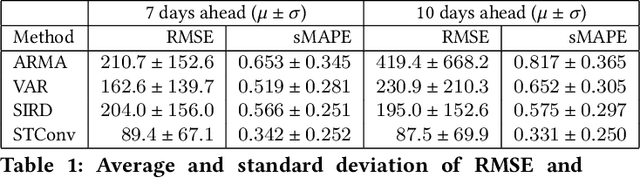
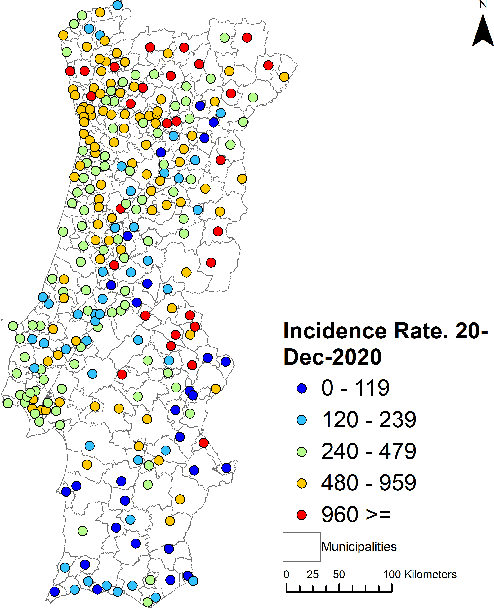
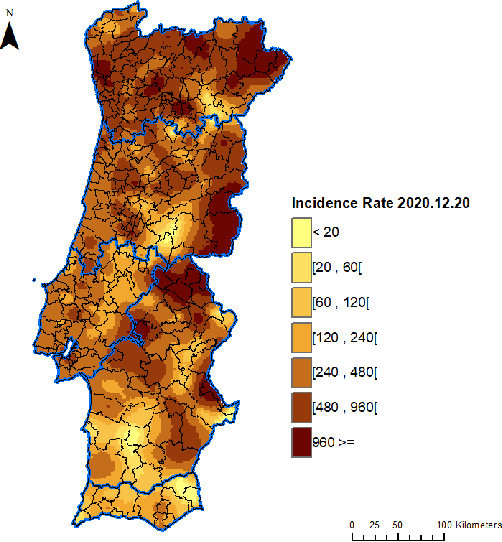
Europe was hit hard by the COVID-19 pandemic and Portugal was one of the most affected countries, having suffered three waves in the first twelve months. Approximately between Jan 19th and Feb 5th 2021 Portugal was the country in the world with the largest incidence rate, with 14-days incidence rates per 100,000 inhabitants in excess of 1000. Despite its importance, accurate prediction of the geospatial evolution of COVID-19 remains a challenge, since existing analytical methods fail to capture the complex dynamics that result from both the contagion within a region and the spreading of the infection from infected neighboring regions. We use a previously developed methodology and official municipality level data from the Portuguese Directorate-General for Health (DGS), relative to the first twelve months of the pandemic, to compute an estimate of the incidence rate in each location of mainland Portugal. The resulting sequence of incidence rate maps was then used as a gold standard to test the effectiveness of different approaches in the prediction of the spatial-temporal evolution of the incidence rate. Four different methods were tested: a simple cell level autoregressive moving average (ARMA) model, a cell level vector autoregressive (VAR) model, a municipality-by-municipality compartmental SIRD model followed by direct block sequential simulation and a convolutional sequence-to-sequence neural network model based on the STConvS2S architecture. We conclude that the convolutional sequence-to-sequence neural network is the best performing method, when predicting the medium-term future incidence rate, using the available information.
Provenance Data in the Machine Learning Lifecycle in Computational Science and Engineering
Oct 21, 2019
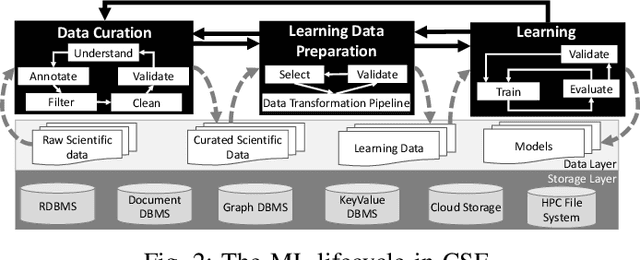
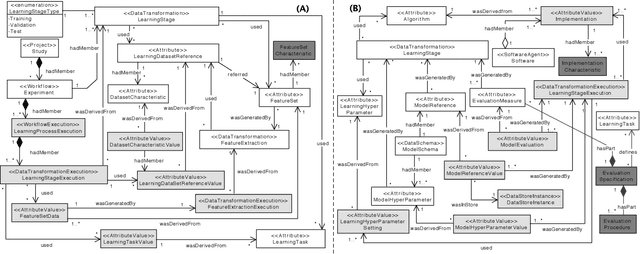
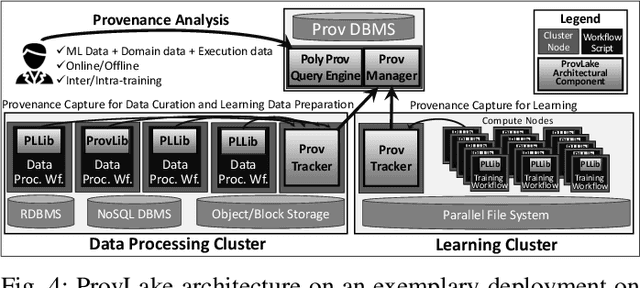
Machine Learning (ML) has become essential in several industries. In Computational Science and Engineering (CSE), the complexity of the ML lifecycle comes from the large variety of data, scientists' expertise, tools, and workflows. If data are not tracked properly during the lifecycle, it becomes unfeasible to recreate a ML model from scratch or to explain to stakeholders how it was created. The main limitation of provenance tracking solutions is that they cannot cope with provenance capture and integration of domain and ML data processed in the multiple workflows in the lifecycle while keeping the provenance capture overhead low. To handle this problem, in this paper we contribute with a detailed characterization of provenance data in the ML lifecycle in CSE; a new provenance data representation, called PROV-ML, built on top of W3C PROV and ML Schema; and extensions to a system that tracks provenance from multiple workflows to address the characteristics of ML and CSE, and to allow for provenance queries with a standard vocabulary. We show a practical use in a real case in the Oil and Gas industry, along with its evaluation using 48 GPUs in parallel.