 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-augmented Risk Assessment (KaRA): a hybrid-intelligence framework for supporting knowledge-intensive risk assessment of prospect candidates
Mar 09, 2023



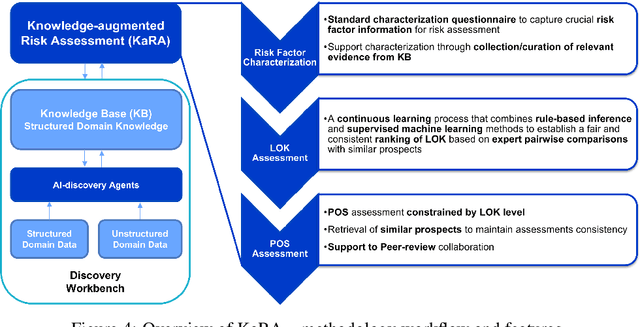
Evaluating the potential of a prospective candidate is a common task in multiple decision-making processes in different industries. We refer to a prospect as something or someone that could potentially produce positive results in a given context, e.g., an area where an oil company could find oil, a compound that, when synthesized, results in a material with required properties, and so on. In many contexts, assessing the Probability of Success (PoS) of prospects heavily depends on experts' knowledge, often leading to biased and inconsistent assessments. We have developed the framework named KARA (Knowledge-augmented Risk Assessment) to address these issues. It combines multiple AI techniques that consider SMEs (Subject Matter Experts) feedback on top of a structured domain knowledge-base to support risk assessment processes of prospect candidates in knowledge-intensive contexts.
Position Paper on Dataset Engineering to Accelerate Science
Mar 09, 2023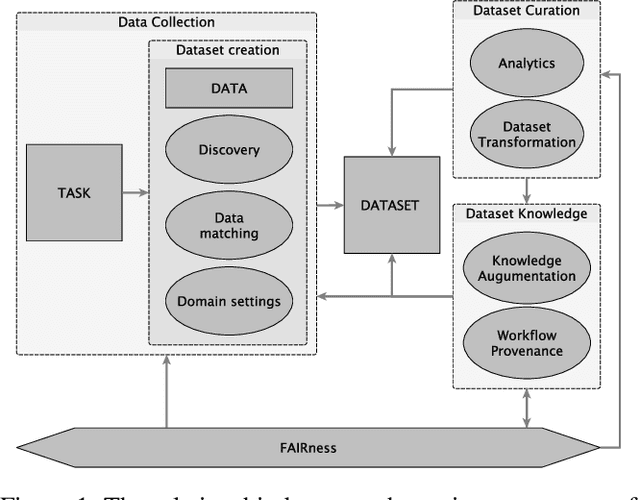
Data is a critical element in any discovery process. In the last decades, we observed exponential growth in the volume of available data and the technology to manipulate it. However, data is only practical when one can structure it for a well-defined task. For instance, we need a corpus of text broken into sentences to train a natural language machine-learning model. In this work, we will use the token \textit{dataset} to designate a structured set of data built to perform a well-defined task. Moreover, the dataset will be used in most cases as a blueprint of an entity that at any moment can be stored as a table. Specifically, in science, each area has unique forms to organize, gather and handle its datasets. We believe that datasets must be a first-class entity in any knowledge-intensive process, and all workflows should have exceptional attention to datasets' lifecycle, from their gathering to uses and evolution. We advocate that science and engineering discovery processes are extreme instances of the need for such organization on datasets, claiming for new approaches and tooling. Furthermore, these requirements are more evident when the discovery workflow uses artificial intelligence methods to empower the subject-matter expert. In this work, we discuss an approach to bringing datasets as a critical entity in the discovery process in science. We illustrate some concepts using material discovery as a use case. We chose this domain because it leverages many significant problems that can be generalized to other science fields.
Toward Human-AI Co-creation to Accelerate Material Discovery
Nov 05, 2022


There is an increasing need in our society to achieve faster advances in Science to tackle urgent problems, such as climate changes, environmental hazards, sustainable energy systems, pandemics, among others. In certain domains like chemistry, scientific discovery carries the extra burden of assessing risks of the proposed novel solutions before moving to the experimental stage. Despite several recent advances in Machine Learning and AI to address some of these challenges, there is still a gap in technologies to support end-to-end discovery applications, integrating the myriad of available technologies into a coherent, orchestrated, yet flexible discovery process. Such applications need to handle complex knowledge management at scale, enabling knowledge consumption and production in a timely and efficient way for subject matter experts (SMEs). Furthermore, the discovery of novel functional materials strongly relies on the development of exploration strategies in the chemical space. For instance, generative models have gained attention within the scientific community due to their ability to generate enormous volumes of novel molecules across material domains. These models exhibit extreme creativity that often translates in low viability of the generated candidates. In this work, we propose a workbench framework that aims at enabling the human-AI co-creation to reduce the time until the first discovery and the opportunity costs involved. This framework relies on a knowledge base with domain and process knowledge, and user-interaction components to acquire knowledge and advise the SMEs. Currently,the framework supports four main activities: generative modeling, dataset triage, molecule adjudication, and risk assessment.