 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAEDFL: Efficient Asynchronous Decentralized Federated Learning with Heterogeneous Devices
Dec 18, 2023Federated Learning (FL) has achieved significant achievements recently, enabling collaborative model training on distributed data over edge devices. Iterative gradient or model exchanges between devices and the centralized server in the standard FL paradigm suffer from severe efficiency bottlenecks on the server. While enabling collaborative training without a central server, existing decentralized FL approaches either focus on the synchronous mechanism that deteriorates FL convergence or ignore device staleness with an asynchronous mechanism, resulting in inferior FL accuracy. In this paper, we propose an Asynchronous Efficient Decentralized FL framework, i.e., AEDFL, in heterogeneous environments with three unique contributions. First, we propose an asynchronous FL system model with an efficient model aggregation method for improving the FL convergence. Second, we propose a dynamic staleness-aware model update approach to achieve superior accuracy. Third, we propose an adaptive sparse training method to reduce communication and computation costs without significant accuracy degradation. Extensive experimentation on four public datasets and four models demonstrates the strength of AEDFL in terms of accuracy (up to 16.3% higher), efficiency (up to 92.9% faster), and computation costs (up to 42.3% lower).
Large-scale Knowledge Distillation with Elastic Heterogeneous Computing Resources
Jul 14, 2022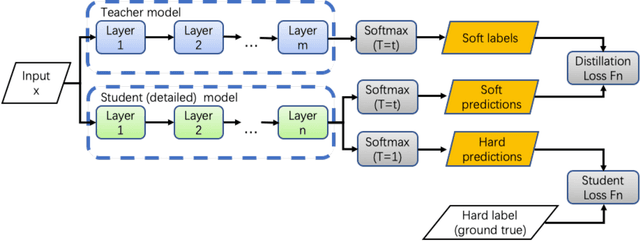

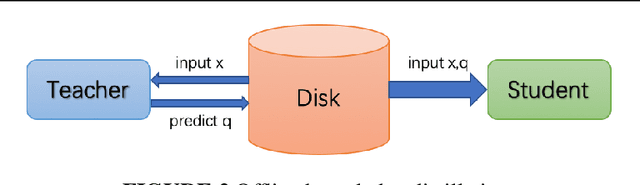
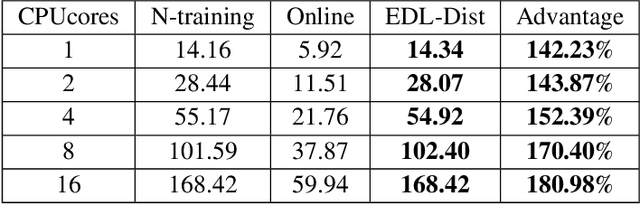
Although more layers and more parameters generally improve the accuracy of the models, such big models generally have high computational complexity and require big memory, which exceed the capacity of small devices for inference and incurs long training time. In addition, it is difficult to afford long training time and inference time of big models even in high performance servers, as well. As an efficient approach to compress a large deep model (a teacher model) to a compact model (a student model), knowledge distillation emerges as a promising approach to deal with the big models. Existing knowledge distillation methods cannot exploit the elastic available computing resources and correspond to low efficiency. In this paper, we propose an Elastic Deep Learning framework for knowledge Distillation, i.e., EDL-Dist. The advantages of EDL-Dist are three-fold. First, the inference and the training process is separated. Second, elastic available computing resources can be utilized to improve the efficiency. Third, fault-tolerance of the training and inference processes is supported. We take extensive experimentation to show that the throughput of EDL-Dist is up to 3.125 times faster than the baseline method (online knowledge distillation) while the accuracy is similar or higher.
Distributed intelligence on the Edge-to-Cloud Continuum: A systematic literature review
Apr 29, 2022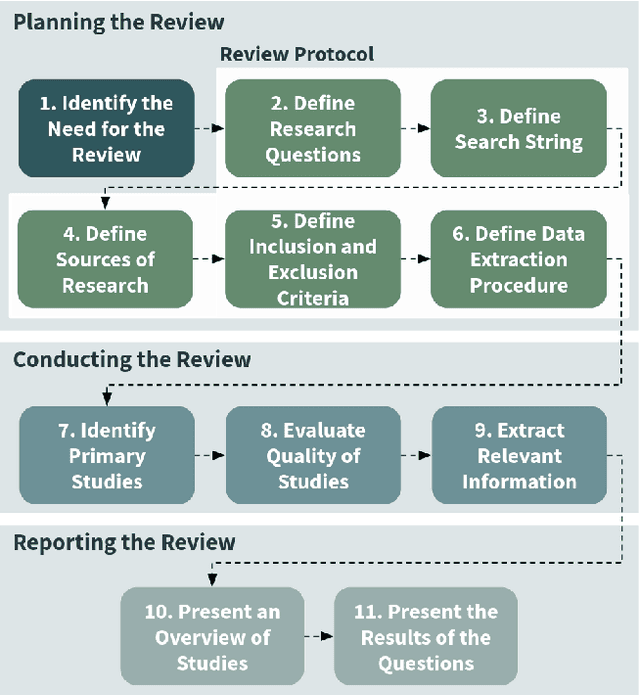
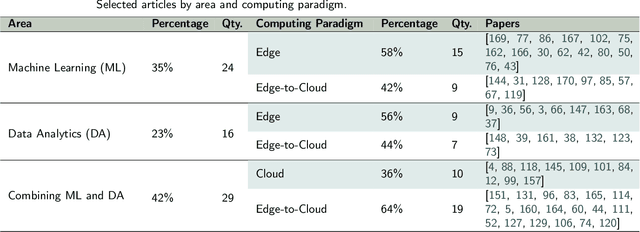
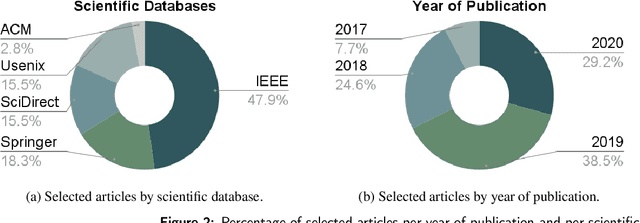
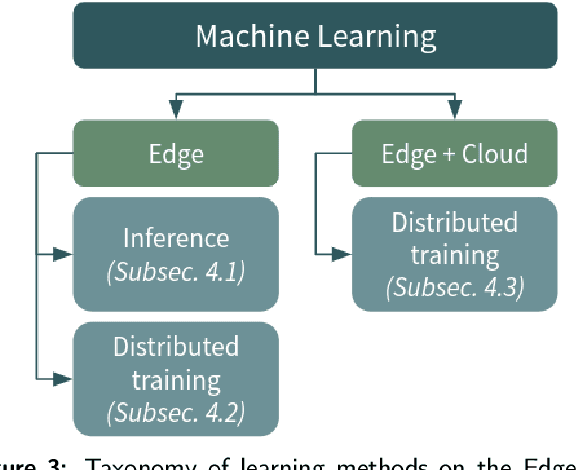
The explosion of data volumes generated by an increasing number of applications is strongly impacting the evolution of distributed digital infrastructures for data analytics and machine learning (ML). While data analytics used to be mainly performed on cloud infrastructures, the rapid development of IoT infrastructures and the requirements for low-latency, secure processing has motivated the development of edge analytics. Today, to balance various trade-offs, ML-based analytics tends to increasingly leverage an interconnected ecosystem that allows complex applications to be executed on hybrid infrastructures where IoT Edge devices are interconnected to Cloud/HPC systems in what is called the Computing Continuum, the Digital Continuum, or the Transcontinuum.Enabling learning-based analytics on such complex infrastructures is challenging. The large scale and optimized deployment of learning-based workflows across the Edge-to-Cloud Continuum requires extensive and reproducible experimental analysis of the application execution on representative testbeds. This is necessary to help understand the performance trade-offs that result from combining a variety of learning paradigms and supportive frameworks. A thorough experimental analysis requires the assessment of the impact of multiple factors, such as: model accuracy, training time, network overhead, energy consumption, processing latency, among others.This review aims at providing a comprehensive vision of the main state-of-the-art libraries and frameworks for machine learning and data analytics available today. It describes the main learning paradigms enabling learning-based analytics on the Edge-to-Cloud Continuum. The main simulation, emulation, deployment systems, and testbeds for experimental research on the Edge-to-Cloud Continuum available today are also surveyed. Furthermore, we analyze how the selected systems provide support for experiment reproducibility. We conclude our review with a detailed discussion of relevant open research challenges and of future directions in this domain such as: holistic understanding of performance; performance optimization of applications;efficient deployment of Artificial Intelligence (AI) workflows on highly heterogeneous infrastructures; and reproducible analysis of experiments on the Computing Continuum.
Reproducible Performance Optimization of Complex Applications on the Edge-to-Cloud Continuum
Aug 04, 2021



In more and more application areas, we are witnessing the emergence of complex workflows that combine computing, analytics and learning. They often require a hybrid execution infrastructure with IoT devices interconnected to cloud/HPC systems (aka Computing Continuum). Such workflows are subject to complex constraints and requirements in terms of performance, resource usage, energy consumption and financial costs. This makes it challenging to optimize their configuration and deployment. We propose a methodology to support the optimization of real-life applications on the Edge-to-Cloud Continuum. We implement it as an extension of E2Clab, a previously proposed framework supporting the complete experimental cycle across the Edge-to-Cloud Continuum. Our approach relies on a rigorous analysis of possible configurations in a controlled testbed environment to understand their behaviour and related performance trade-offs. We illustrate our methodology by optimizing Pl@ntNet, a world-wide plant identification application. Our methodology can be generalized to other applications in the Edge-to-Cloud Continuum.
Hyperspherical embedding for novel class classification
Feb 05, 2021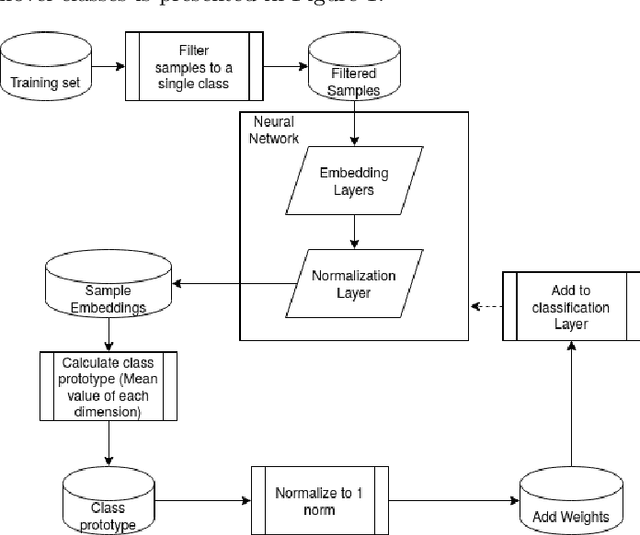

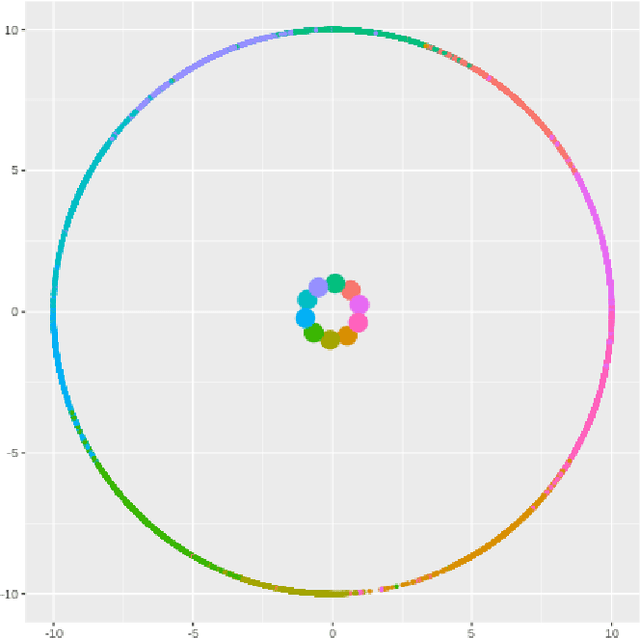
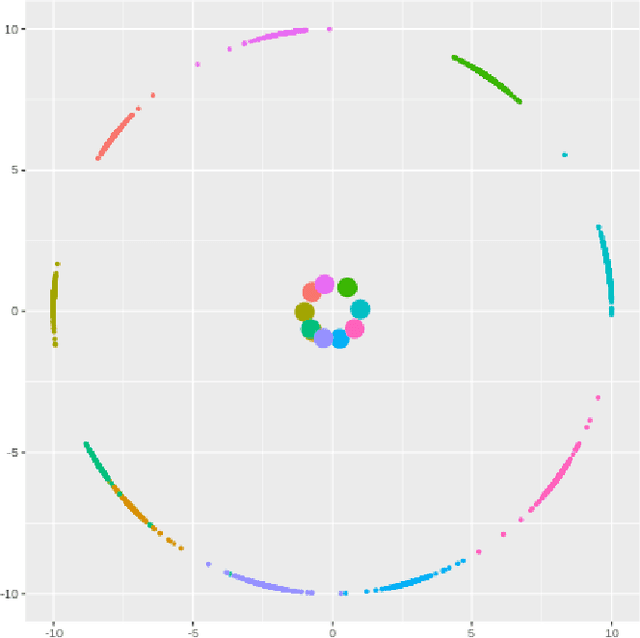
Deep learning models have become increasingly useful in many different industries. On the domain of image classification, convolutional neural networks proved the ability to learn robust features for the closed set problem, as shown in many different datasets, such as MNIST FASHIONMNIST, CIFAR10, CIFAR100, and IMAGENET. These approaches use deep neural networks with dense layers with softmax activation functions in order to learn features that can separate classes in a latent space. However, this traditional approach is not useful for identifying classes unseen on the training set, known as the open set problem. A similar problem occurs in scenarios involving learning on small data. To tackle both problems, few-shot learning has been proposed. In particular, metric learning learns features that obey constraints of a metric distance in the latent space in order to perform classification. However, while this approach proves to be useful for the open set problem, current implementation requires pair-wise training, where both positive and negative examples of similar images are presented during the training phase, which limits the applicability of these approaches in large data or large class scenarios given the combinatorial nature of the possible inputs.In this paper, we present a constraint-based approach applied to the representations in the latent space under the normalized softmax loss, proposed by[18]. We experimentally validate the proposed approach for the classification of unseen classes on different datasets using both metric learning and the normalized softmax loss, on disjoint and joint scenarios. Our results show that not only our proposed strategy can be efficiently trained on larger set of classes, as it does not require pairwise learning, but also present better classification results than the metric learning strategies surpassing its accuracy by a significant margin.
Workflow Provenance in the Lifecycle of Scientific Machine Learning
Sep 30, 2020

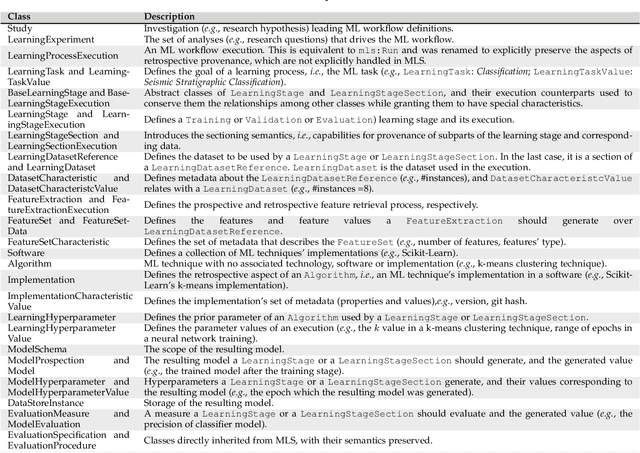

Machine Learning (ML) has already fundamentally changed several businesses. More recently, it has also been profoundly impacting the computational science and engineering domains, like geoscience, climate science, and health science. In these domains, users need to perform comprehensive data analyses combining scientific data and ML models to provide for critical requirements, such as reproducibility, model explainability, and experiment data understanding. However, scientific ML is multidisciplinary, heterogeneous, and affected by the physical constraints of the domain, making such analyses even more challenging. In this work, we leverage workflow provenance techniques to build a holistic view to support the lifecycle of scientific ML. We contribute with (i) characterization of the lifecycle and taxonomy for data analyses; (ii) design principles to build this view, with a W3C PROV compliant data representation and a reference system architecture; and (iii) lessons learned after an evaluation in an Oil & Gas case using an HPC cluster with 393 nodes and 946 GPUs. The experiments show that the principles enable queries that integrate domain semantics with ML models while keeping low overhead (<1%), high scalability, and an order of magnitude of query acceleration under certain workloads against without our representation.
Provenance Data in the Machine Learning Lifecycle in Computational Science and Engineering
Oct 21, 2019
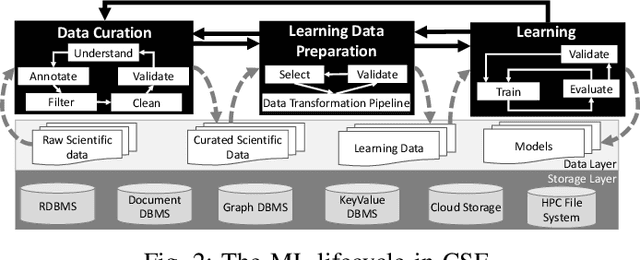
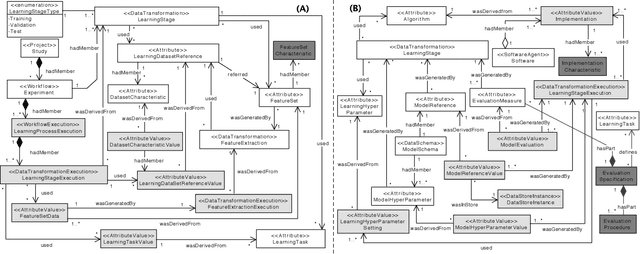
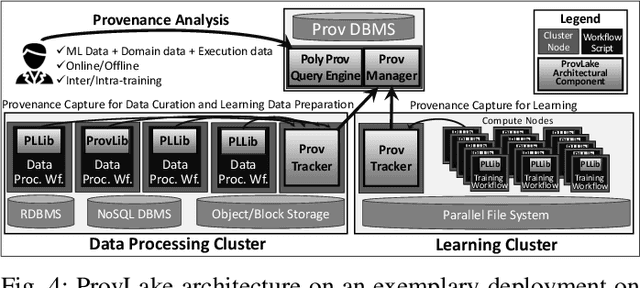
Machine Learning (ML) has become essential in several industries. In Computational Science and Engineering (CSE), the complexity of the ML lifecycle comes from the large variety of data, scientists' expertise, tools, and workflows. If data are not tracked properly during the lifecycle, it becomes unfeasible to recreate a ML model from scratch or to explain to stakeholders how it was created. The main limitation of provenance tracking solutions is that they cannot cope with provenance capture and integration of domain and ML data processed in the multiple workflows in the lifecycle while keeping the provenance capture overhead low. To handle this problem, in this paper we contribute with a detailed characterization of provenance data in the ML lifecycle in CSE; a new provenance data representation, called PROV-ML, built on top of W3C PROV and ML Schema; and extensions to a system that tracks provenance from multiple workflows to address the characteristics of ML and CSE, and to allow for provenance queries with a standard vocabulary. We show a practical use in a real case in the Oil and Gas industry, along with its evaluation using 48 GPUs in parallel.
Parallel Computation of PDFs on Big Spatial Data Using Spark
May 08, 2018

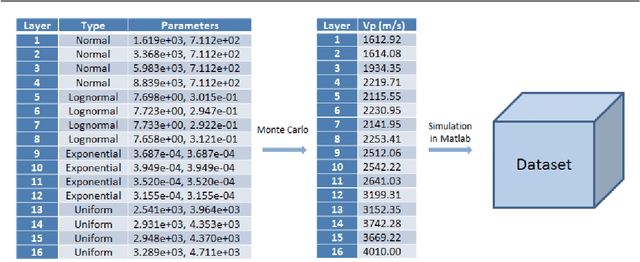
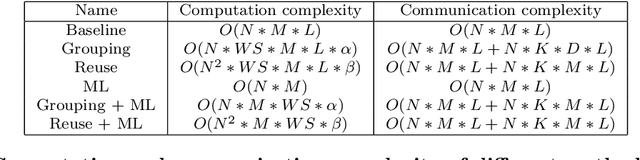
We consider big spatial data, which is typically produced in scientific areas such as geological or seismic interpretation. The spatial data can be produced by observation (e.g. using sensors or soil instrument) or numerical simulation programs and correspond to points that represent a 3D soil cube area. However, errors in signal processing and modeling create some uncertainty, and thus a lack of accuracy in identifying geological or seismic phenomenons. Such uncertainty must be carefully analyzed. To analyze uncertainty, the main solution is to compute a Probability Density Function (PDF) of each point in the spatial cube area. However, computing PDFs on big spatial data can be very time consuming (from several hours to even months on a parallel computer). In this paper, we propose a new solution to efficiently compute such PDFs in parallel using Spark, with three methods: data grouping, machine learning prediction and sampling. We evaluate our solution by extensive experiments on different computer clusters using big data ranging from hundreds of GB to several TB. The experimental results show that our solution scales up very well and can reduce the execution time by a factor of 33 (in the order of seconds or minutes) compared with a baseline method.