 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKIF: A Framework for Virtual Integration of Heterogeneous Knowledge Bases using Wikidata
Mar 15, 2024We present a knowledge integration framework (called KIF) that uses Wikidata as a lingua franca to integrate heterogeneous knowledge bases. These can be triplestores, relational databases, CSV files, etc., which may or may not use the Wikidata dialect of RDF. KIF leverages Wikidata's data model and vocabulary plus user-defined mappings to expose a unified view of the integrated bases while keeping track of the context and provenance of their statements. The result is a virtual knowledge base which behaves like an "extended Wikidata" and which can be queried either through an efficient filter interface or using SPARQL. We present the design and implementation of KIF, discuss how we have used it to solve a real integration problem in the domain of chemistry (involving Wikidata, PubChem, and IBM CIRCA), and present experimental results on the performance and overhead of KIF.
Workflow Provenance in the Lifecycle of Scientific Machine Learning
Sep 30, 2020

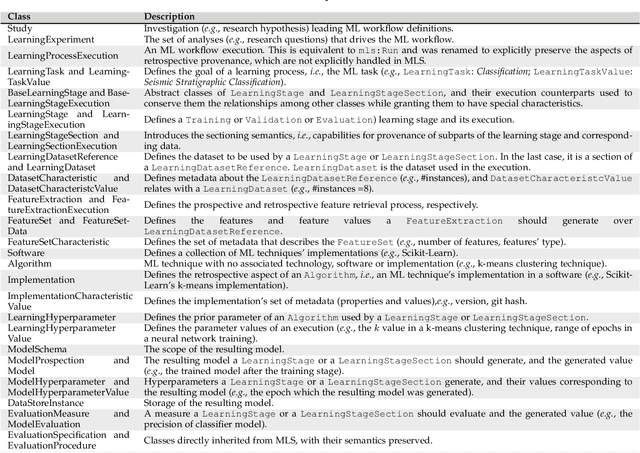

Machine Learning (ML) has already fundamentally changed several businesses. More recently, it has also been profoundly impacting the computational science and engineering domains, like geoscience, climate science, and health science. In these domains, users need to perform comprehensive data analyses combining scientific data and ML models to provide for critical requirements, such as reproducibility, model explainability, and experiment data understanding. However, scientific ML is multidisciplinary, heterogeneous, and affected by the physical constraints of the domain, making such analyses even more challenging. In this work, we leverage workflow provenance techniques to build a holistic view to support the lifecycle of scientific ML. We contribute with (i) characterization of the lifecycle and taxonomy for data analyses; (ii) design principles to build this view, with a W3C PROV compliant data representation and a reference system architecture; and (iii) lessons learned after an evaluation in an Oil & Gas case using an HPC cluster with 393 nodes and 946 GPUs. The experiments show that the principles enable queries that integrate domain semantics with ML models while keeping low overhead (<1%), high scalability, and an order of magnitude of query acceleration under certain workloads against without our representation.
Provenance Data in the Machine Learning Lifecycle in Computational Science and Engineering
Oct 21, 2019
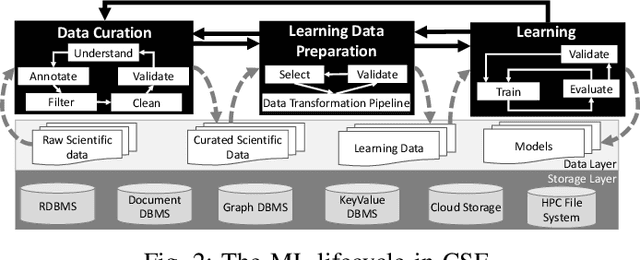
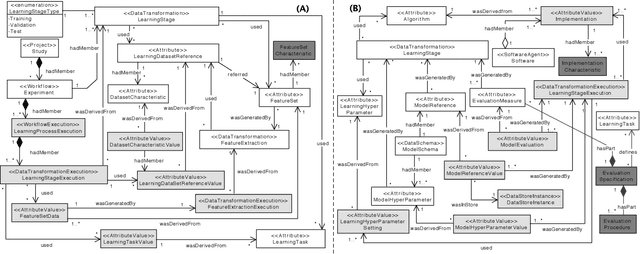
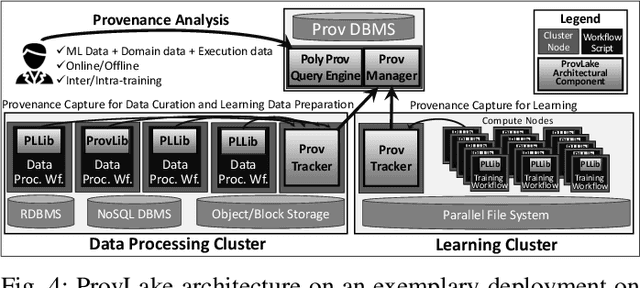
Machine Learning (ML) has become essential in several industries. In Computational Science and Engineering (CSE), the complexity of the ML lifecycle comes from the large variety of data, scientists' expertise, tools, and workflows. If data are not tracked properly during the lifecycle, it becomes unfeasible to recreate a ML model from scratch or to explain to stakeholders how it was created. The main limitation of provenance tracking solutions is that they cannot cope with provenance capture and integration of domain and ML data processed in the multiple workflows in the lifecycle while keeping the provenance capture overhead low. To handle this problem, in this paper we contribute with a detailed characterization of provenance data in the ML lifecycle in CSE; a new provenance data representation, called PROV-ML, built on top of W3C PROV and ML Schema; and extensions to a system that tracks provenance from multiple workflows to address the characteristics of ML and CSE, and to allow for provenance queries with a standard vocabulary. We show a practical use in a real case in the Oil and Gas industry, along with its evaluation using 48 GPUs in parallel.