 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKIF: A Framework for Virtual Integration of Heterogeneous Knowledge Bases using Wikidata
Mar 15, 2024We present a knowledge integration framework (called KIF) that uses Wikidata as a lingua franca to integrate heterogeneous knowledge bases. These can be triplestores, relational databases, CSV files, etc., which may or may not use the Wikidata dialect of RDF. KIF leverages Wikidata's data model and vocabulary plus user-defined mappings to expose a unified view of the integrated bases while keeping track of the context and provenance of their statements. The result is a virtual knowledge base which behaves like an "extended Wikidata" and which can be queried either through an efficient filter interface or using SPARQL. We present the design and implementation of KIF, discuss how we have used it to solve a real integration problem in the domain of chemistry (involving Wikidata, PubChem, and IBM CIRCA), and present experimental results on the performance and overhead of KIF.
An Ensemble Approach for Automated Theorem Proving Based on Efficient Name Invariant Graph Neural Representations
May 15, 2023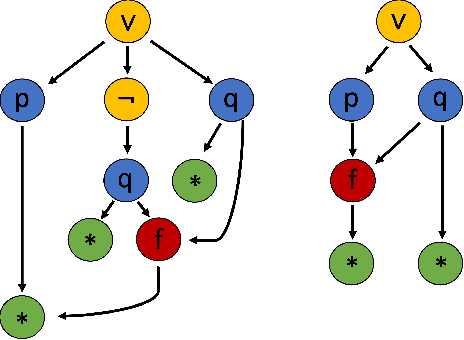
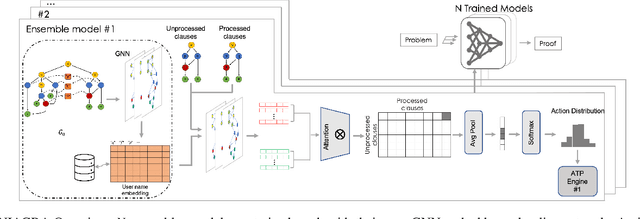

Using reinforcement learning for automated theorem proving has recently received much attention. Current approaches use representations of logical statements that often rely on the names used in these statements and, as a result, the models are generally not transferable from one domain to another. The size of these representations and whether to include the whole theory or part of it are other important decisions that affect the performance of these approaches as well as their runtime efficiency. In this paper, we present NIAGRA; an ensemble Name InvAriant Graph RepresentAtion. NIAGRA addresses this problem by using 1) improved Graph Neural Networks for learning name-invariant formula representations that is tailored for their unique characteristics and 2) an efficient ensemble approach for automated theorem proving. Our experimental evaluation shows state-of-the-art performance on multiple datasets from different domains with improvements up to 10% compared to the best learning-based approaches. Furthermore, transfer learning experiments show that our approach significantly outperforms other learning-based approaches by up to 28%.
A Benchmark for Generalizable and Interpretable Temporal Question Answering over Knowledge Bases
Jan 15, 2022
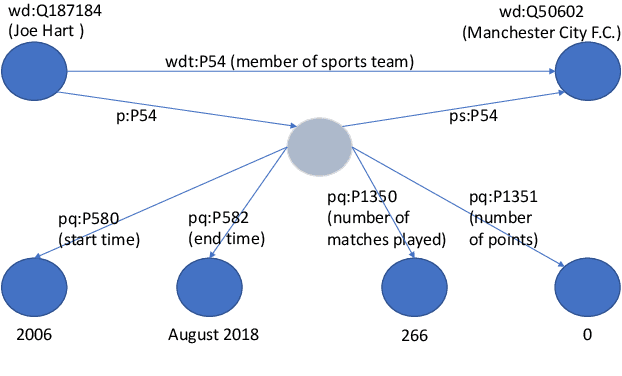


Knowledge Base Question Answering (KBQA) tasks that involve complex reasoning are emerging as an important research direction. However, most existing KBQA datasets focus primarily on generic multi-hop reasoning over explicit facts, largely ignoring other reasoning types such as temporal, spatial, and taxonomic reasoning. In this paper, we present a benchmark dataset for temporal reasoning, TempQA-WD, to encourage research in extending the present approaches to target a more challenging set of complex reasoning tasks. Specifically, our benchmark is a temporal question answering dataset with the following advantages: (a) it is based on Wikidata, which is the most frequently curated, openly available knowledge base, (b) it includes intermediate sparql queries to facilitate the evaluation of semantic parsing based approaches for KBQA, and (c) it generalizes to multiple knowledge bases: Freebase and Wikidata. The TempQA-WD dataset is available at https://github.com/IBM/tempqa-wd.
Bridging the Gap between Semantics and Multimedia Processing
Dec 02, 2019
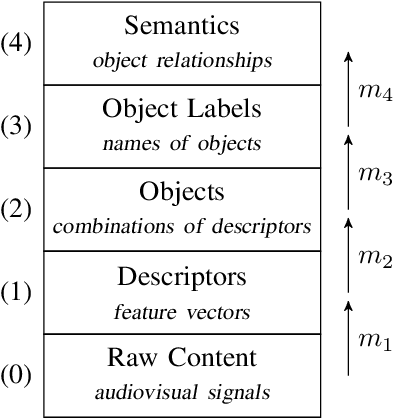
In this paper, we give an overview of the semantic gap problem in multimedia and discuss how machine learning and symbolic AI can be combined to narrow this gap. We describe the gap in terms of a classical architecture for multimedia processing and discuss a structured approach to bridge it. This approach combines machine learning (for mapping signals to objects) and symbolic AI (for linking objects to meanings). Our main goal is to raise awareness and discuss the challenges involved in this structured approach to multimedia understanding, especially in the view of the latest developments in machine learning and symbolic AI.
An Introduction to Symbolic Artificial Intelligence Applied to Multimedia
Nov 28, 2019

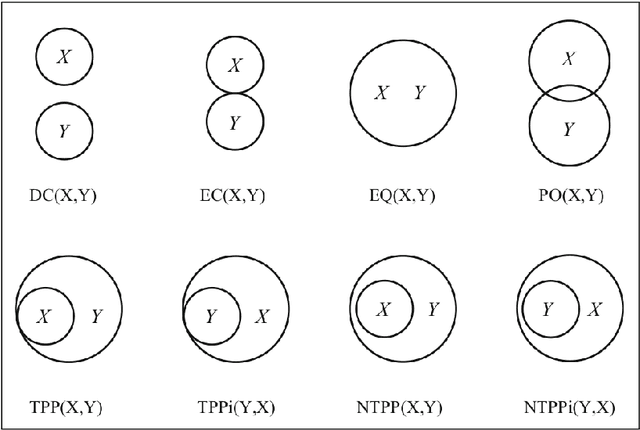
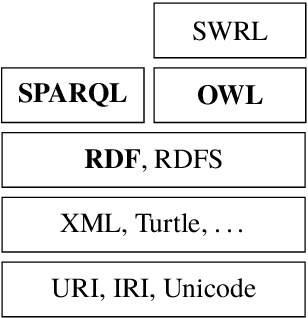
In this chapter, we give an introduction to symbolic artificial intelligence (AI) and discuss its relation and application to multimedia. We begin by defining what symbolic AI is, what distinguishes it from non-symbolic approaches, such as machine learning, and how it can used in the construction of advanced multimedia applications. We then introduce description logic (DL) and use it to discuss symbolic representation and reasoning. DL is the logical underpinning of OWL, the most successful family of ontology languages. After discussing DL, we present OWL and related Semantic Web technologies, such as RDF and SPARQL. We conclude the chapter by discussing a hybrid model for multimedia representation, called Hyperknowledge. Throughout the text, we make references to technologies and extensions specifically designed to solve the kinds of problems that arise in multimedia representation.