 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTRAG: A Multi-Turn Conversational Benchmark for Evaluating Retrieval-Augmented Generation Systems
Jan 07, 2025



Retrieval-augmented generation (RAG) has recently become a very popular task for Large Language Models (LLMs). Evaluating them on multi-turn RAG conversations, where the system is asked to generate a response to a question in the context of a preceding conversation is an important and often overlooked task with several additional challenges. We present MTRAG: an end-to-end human-generated multi-turn RAG benchmark that reflects several real-world properties across diverse dimensions for evaluating the full RAG pipeline. MTRAG contains 110 conversations averaging 7.7 turns each across four domains for a total of 842 tasks. We also explore automation paths via synthetic data and LLM-as-a-Judge evaluation. Our human and automatic evaluations show that even state-of-the-art LLM RAG systems struggle on MTRAG. We demonstrate the need for strong retrieval and generation systems that can handle later turns, unanswerable questions, non-standalone questions, and multiple domains. MTRAG is available at https://github.com/ibm/mt-rag-benchmark.
Multi-Document Grounded Multi-Turn Synthetic Dialog Generation
Sep 17, 2024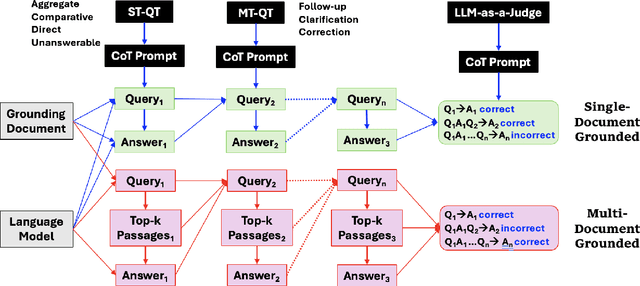
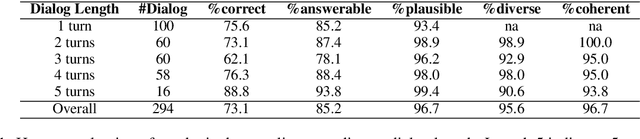
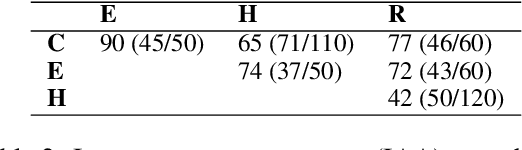
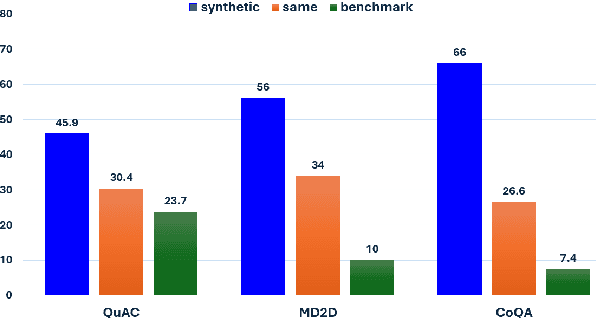
We introduce a technique for multi-document grounded multi-turn synthetic dialog generation that incorporates three main ideas. First, we control the overall dialog flow using taxonomy-driven user queries that are generated with Chain-of-Thought (CoT) prompting. Second, we support the generation of multi-document grounded dialogs by mimicking real-world use of retrievers to update the grounding documents after every user-turn in the dialog. Third, we apply LLM-as-a-Judge to filter out queries with incorrect answers. Human evaluation of the synthetic dialog data suggests that the data is diverse, coherent, and includes mostly correct answers. Both human and automatic evaluations of answerable queries indicate that models fine-tuned on synthetic dialogs consistently out-perform those fine-tuned on existing human generated training data across four publicly available multi-turn document grounded benchmark test sets.
Self-Refinement of Language Models from External Proxy Metrics Feedback
Feb 27, 2024



It is often desirable for Large Language Models (LLMs) to capture multiple objectives when providing a response. In document-grounded response generation, for example, agent responses are expected to be relevant to a user's query while also being grounded in a given document. In this paper, we introduce Proxy Metric-based Self-Refinement (ProMiSe), which enables an LLM to refine its own initial response along key dimensions of quality guided by external metrics feedback, yielding an overall better final response. ProMiSe leverages feedback on response quality through principle-specific proxy metrics, and iteratively refines its response one principle at a time. We apply ProMiSe to open source language models Flan-T5-XXL and Llama-2-13B-Chat, to evaluate its performance on document-grounded question answering datasets, MultiDoc2Dial and QuAC, demonstrating that self-refinement improves response quality. We further show that fine-tuning Llama-2-13B-Chat on the synthetic dialogue data generated by ProMiSe yields significant performance improvements over the zero-shot baseline as well as a supervised fine-tuned model on human annotated data.
Ensemble-Instruct: Generating Instruction-Tuning Data with a Heterogeneous Mixture of LMs
Oct 21, 2023



Using in-context learning (ICL) for data generation, techniques such as Self-Instruct (Wang et al., 2023) or the follow-up Alpaca (Taori et al., 2023) can train strong conversational agents with only a small amount of human supervision. One limitation of these approaches is that they resort to very large language models (around 175B parameters) that are also proprietary and non-public. Here we explore the application of such techniques to language models that are much smaller (around 10B--40B parameters) and have permissive licenses. We find the Self-Instruct approach to be less effective at these sizes and propose new ICL methods that draw on two main ideas: (a) Categorization and simplification of the ICL templates to make prompt learning easier for the LM, and (b) Ensembling over multiple LM outputs to help select high-quality synthetic examples. Our algorithm leverages the 175 Self-Instruct seed tasks and employs separate pipelines for instructions that require an input and instructions that do not. Empirical investigations with different LMs show that: (1) Our proposed method yields higher-quality instruction tuning data than Self-Instruct, (2) It improves performances of both vanilla and instruction-tuned LMs by significant margins, and (3) Smaller instruction-tuned LMs generate more useful outputs than their larger un-tuned counterparts. Our codebase is available at https://github.com/IBM/ensemble-instruct.
AMR Parsing with Instruction Fine-tuned Pre-trained Language Models
Apr 24, 2023
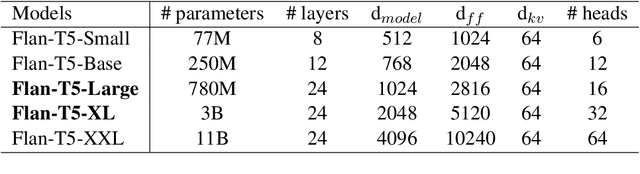
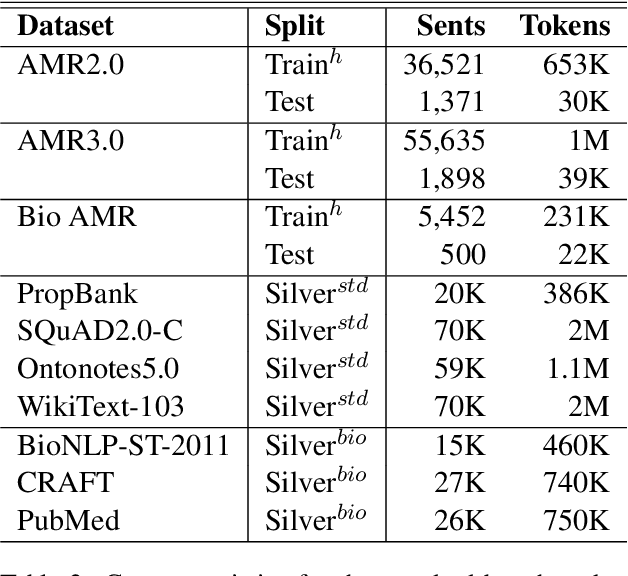
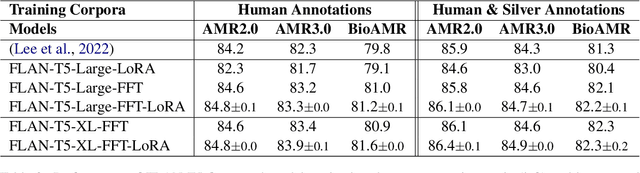
Instruction fine-tuned language models on a collection of instruction annotated datasets (FLAN) have shown highly effective to improve model performance and generalization to unseen tasks. However, a majority of standard parsing tasks including abstract meaning representation (AMR), universal dependency (UD), semantic role labeling (SRL) has been excluded from the FLAN collections for both model training and evaluations. In this paper, we take one of such instruction fine-tuned pre-trained language models, i.e. FLAN-T5, and fine-tune them for AMR parsing. Our extensive experiments on various AMR parsing tasks including AMR2.0, AMR3.0 and BioAMR indicate that FLAN-T5 fine-tuned models out-perform previous state-of-the-art models across all tasks. In addition, full fine-tuning followed by the parameter efficient fine-tuning, LoRA, further improves the model performances, setting new state-of-the-arts in Smatch on AMR2.0 (86.4), AMR3.0 (84.9) and BioAMR (82.3).
A Benchmark for Generalizable and Interpretable Temporal Question Answering over Knowledge Bases
Jan 15, 2022
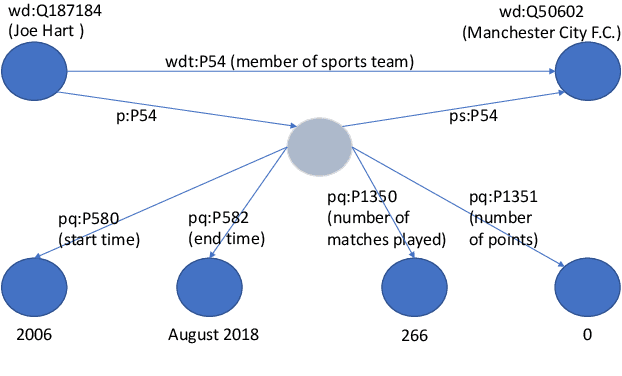


Knowledge Base Question Answering (KBQA) tasks that involve complex reasoning are emerging as an important research direction. However, most existing KBQA datasets focus primarily on generic multi-hop reasoning over explicit facts, largely ignoring other reasoning types such as temporal, spatial, and taxonomic reasoning. In this paper, we present a benchmark dataset for temporal reasoning, TempQA-WD, to encourage research in extending the present approaches to target a more challenging set of complex reasoning tasks. Specifically, our benchmark is a temporal question answering dataset with the following advantages: (a) it is based on Wikidata, which is the most frequently curated, openly available knowledge base, (b) it includes intermediate sparql queries to facilitate the evaluation of semantic parsing based approaches for KBQA, and (c) it generalizes to multiple knowledge bases: Freebase and Wikidata. The TempQA-WD dataset is available at https://github.com/IBM/tempqa-wd.
DocAMR: Multi-Sentence AMR Representation and Evaluation
Dec 15, 2021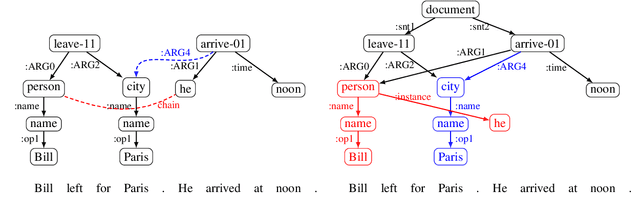
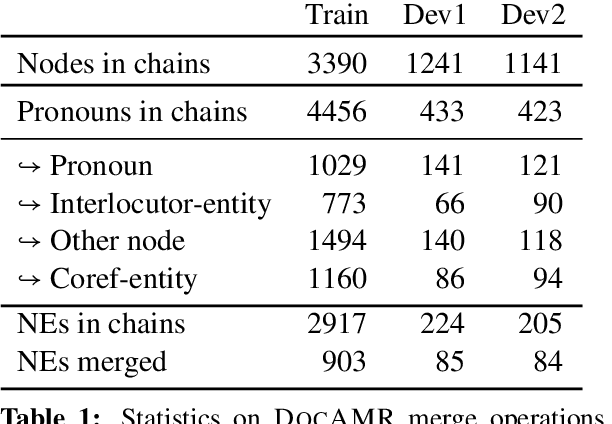
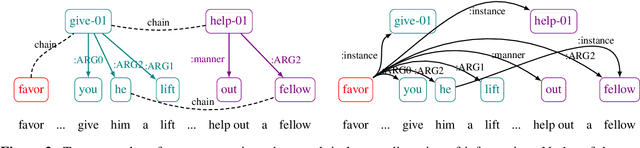
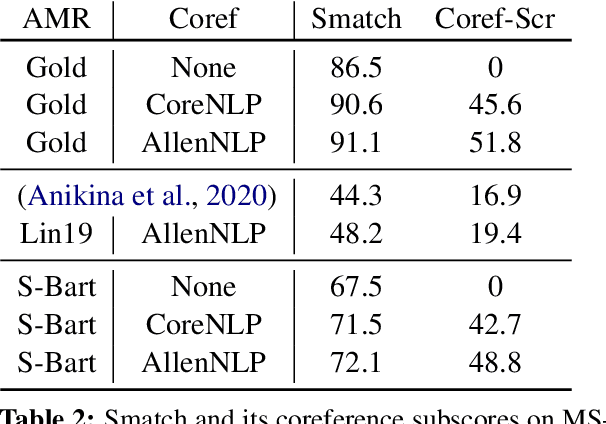
Despite extensive research on parsing of English sentences into Abstraction Meaning Representation (AMR) graphs, which are compared to gold graphs via the Smatch metric, full-document parsing into a unified graph representation lacks well-defined representation and evaluation. Taking advantage of a super-sentential level of coreference annotation from previous work, we introduce a simple algorithm for deriving a unified graph representation, avoiding the pitfalls of information loss from over-merging and lack of coherence from under-merging. Next, we describe improvements to the Smatch metric to make it tractable for comparing document-level graphs, and use it to re-evaluate the best published document-level AMR parser. We also present a pipeline approach combining the top performing AMR parser and coreference resolution systems, providing a strong baseline for future research.
Learning Cross-Lingual IR from an English Retriever
Dec 15, 2021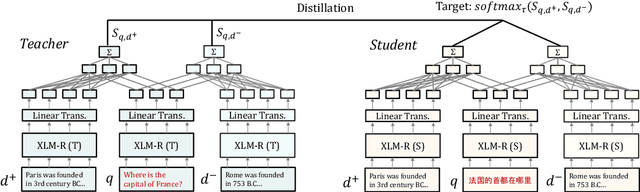
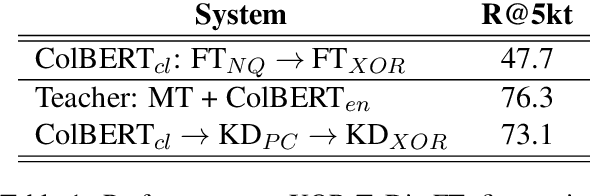
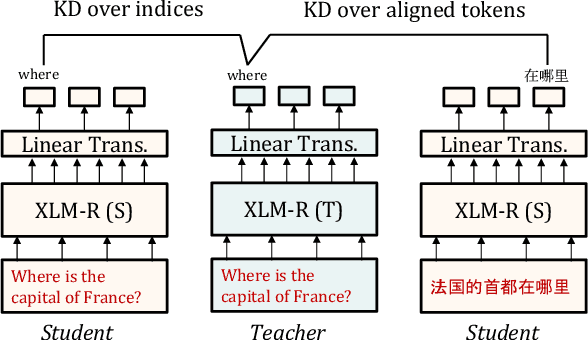
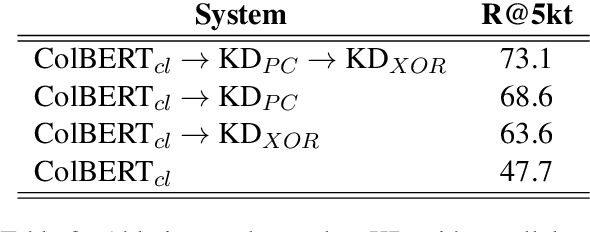
We present a new cross-lingual information retrieval (CLIR) model trained using multi-stage knowledge distillation (KD). The teacher and the student are heterogeneous systems-the former is a pipeline that relies on machine translation and monolingual IR, while the latter executes a single CLIR operation. We show that the student can learn both multilingual representations and CLIR by optimizing two corresponding KD objectives. Learning multilingual representations from an English-only retriever is accomplished using a novel cross-lingual alignment algorithm that greedily re-positions the teacher tokens for alignment. Evaluation on the XOR-TyDi benchmark shows that the proposed model is far more effective than the existing approach of fine-tuning with cross-lingual labeled IR data, with a gain in accuracy of 25.4 Recall@5kt.
Maximum Bayes Smatch Ensemble Distillation for AMR Parsing
Dec 14, 2021
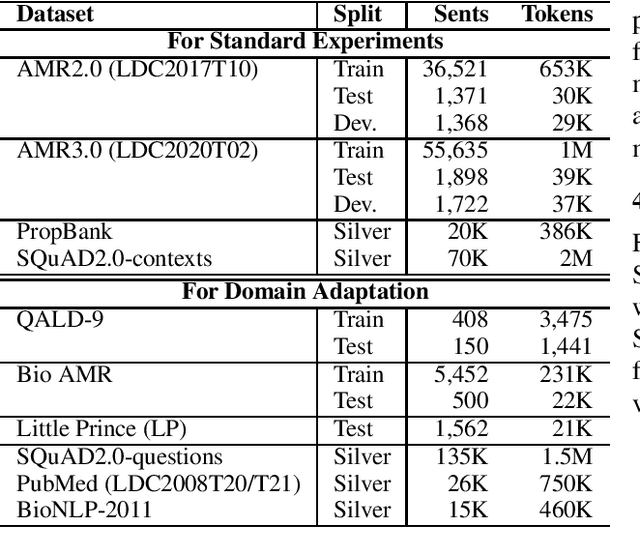

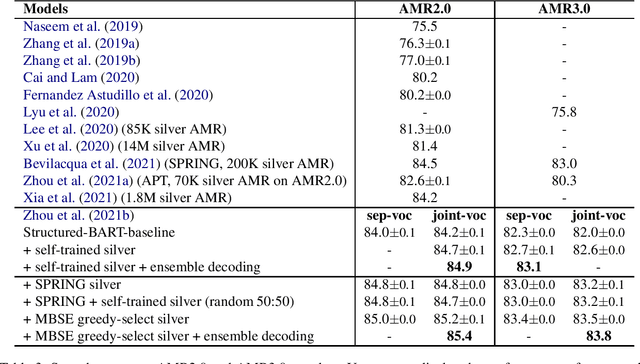
AMR parsing has experienced an unprecendented increase in performance in the last three years, due to a mixture of effects including architecture improvements and transfer learning. Self-learning techniques have also played a role in pushing performance forward. However, for most recent high performant parsers, the effect of self-learning and silver data generation seems to be fading. In this paper we show that it is possible to overcome this diminishing returns of silver data by combining Smatch-based ensembling techniques with ensemble distillation. In an extensive experimental setup, we push single model English parser performance above 85 Smatch for the first time and return to substantial gains. We also attain a new state-of-the-art for cross-lingual AMR parsing for Chinese, German, Italian and Spanish. Finally we explore the impact of the proposed distillation technique on domain adaptation, and show that it can produce gains rivaling those of human annotated data for QALD-9 and achieve a new state-of-the-art for BioAMR.
Structure-aware Fine-tuning of Sequence-to-sequence Transformers for Transition-based AMR Parsing
Oct 29, 2021

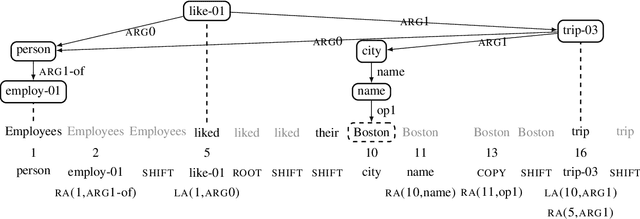

Predicting linearized Abstract Meaning Representation (AMR) graphs using pre-trained sequence-to-sequence Transformer models has recently led to large improvements on AMR parsing benchmarks. These parsers are simple and avoid explicit modeling of structure but lack desirable properties such as graph well-formedness guarantees or built-in graph-sentence alignments. In this work we explore the integration of general pre-trained sequence-to-sequence language models and a structure-aware transition-based approach. We depart from a pointer-based transition system and propose a simplified transition set, designed to better exploit pre-trained language models for structured fine-tuning. We also explore modeling the parser state within the pre-trained encoder-decoder architecture and different vocabulary strategies for the same purpose. We provide a detailed comparison with recent progress in AMR parsing and show that the proposed parser retains the desirable properties of previous transition-based approaches, while being simpler and reaching the new parsing state of the art for AMR 2.0, without the need for graph re-categorization.