 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Cross-Lingual IR from an English Retriever
Paper and Code
Dec 15, 2021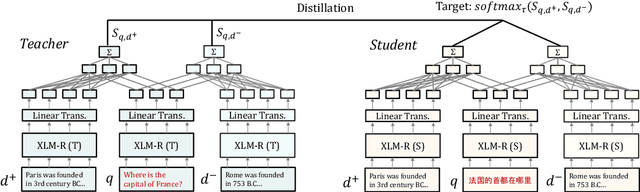
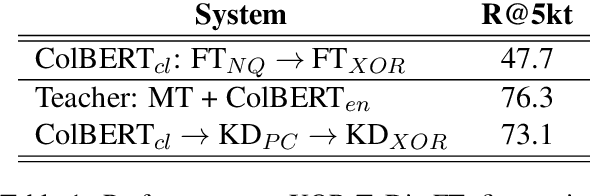
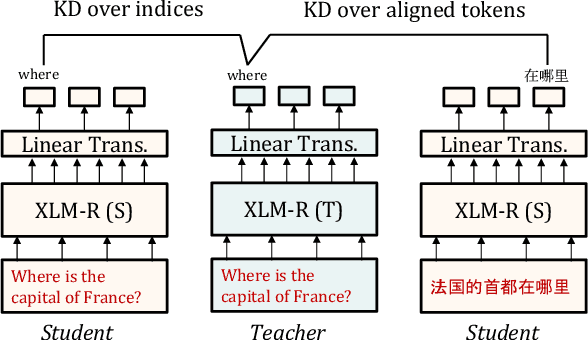
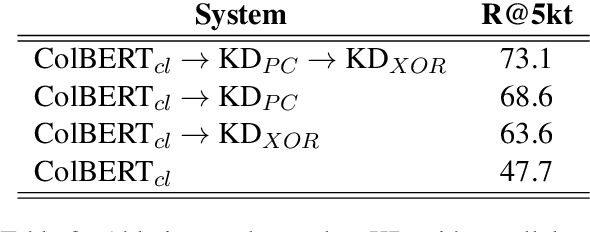
We present a new cross-lingual information retrieval (CLIR) model trained using multi-stage knowledge distillation (KD). The teacher and the student are heterogeneous systems-the former is a pipeline that relies on machine translation and monolingual IR, while the latter executes a single CLIR operation. We show that the student can learn both multilingual representations and CLIR by optimizing two corresponding KD objectives. Learning multilingual representations from an English-only retriever is accomplished using a novel cross-lingual alignment algorithm that greedily re-positions the teacher tokens for alignment. Evaluation on the XOR-TyDi benchmark shows that the proposed model is far more effective than the existing approach of fine-tuning with cross-lingual labeled IR data, with a gain in accuracy of 25.4 Recall@5kt.