 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-Weighted Token Set Cover for Early Hypothesis Pruning in Self-Consistency
Aug 06, 2025Despite its simplicity and efficacy, the high token expenditure of self-consistency can limit its practical utility. Here we investigate if self-consistency can be made more token-efficient for long chain-of-thought reasoning tasks, while preserving its parallelism, through early hypothesis pruning. Concretely, we generate all solutions in parallel, but periodically prune intermediate hypotheses that are deemed unnecessary based on two lightweight indicators: (a) the model's own confidence in individual hypotheses, and (b) lexical coverage of all current hypotheses by candidate subsets that are under consideration for continued retention. We design a fast weighted set cover algorithm that utilizes the two indicators; our evaluation of five LLMs on three math benchmarks shows that this method can improve token efficiency for all models, by 10-35% in many cases.
Optimal Policy Minimum Bayesian Risk
May 22, 2025Inference scaling can help LLMs solve complex reasoning problems through extended runtime computation. On top of targeted supervision for long chain-of-thought (long-CoT) generation, purely inference-time techniques such as best-of-N (BoN) sampling, majority voting, or more generally, minimum Bayes risk decoding (MBRD), can further improve LLM accuracy by generating multiple candidate solutions and aggregating over them. These methods typically leverage additional signals in the form of reward models and risk/similarity functions that compare generated samples, e.g., exact match in some normalized space or standard similarity metrics such as Rouge. Here we present a novel method for incorporating reward and risk/similarity signals into MBRD. Based on the concept of optimal policy in KL-controlled reinforcement learning, our framework provides a simple and well-defined mechanism for leveraging such signals, offering several advantages over traditional inference-time methods: higher robustness, improved accuracy, and well-understood asymptotic behavior. In addition, it allows for the development of a sample-efficient variant of MBRD that can adjust the number of samples to generate according to the difficulty of the problem, without relying on majority vote counts. We empirically demonstrate the advantages of our approach on math (MATH-$500$) and coding (HumanEval) tasks using recent open-source models. We also present a comprehensive analysis of its accuracy-compute trade-offs.
FIRST: Faster Improved Listwise Reranking with Single Token Decoding
Jun 21, 2024



Large Language Models (LLMs) have significantly advanced the field of information retrieval, particularly for reranking. Listwise LLM rerankers have showcased superior performance and generalizability compared to existing supervised approaches. However, conventional listwise LLM reranking methods lack efficiency as they provide ranking output in the form of a generated ordered sequence of candidate passage identifiers. Further, they are trained with the typical language modeling objective, which treats all ranking errors uniformly--potentially at the cost of misranking highly relevant passages. Addressing these limitations, we introduce FIRST, a novel listwise LLM reranking approach leveraging the output logits of the first generated identifier to directly obtain a ranked ordering of the candidates. Further, we incorporate a learning-to-rank loss during training, prioritizing ranking accuracy for the more relevant passages. Empirical results demonstrate that FIRST accelerates inference by 50% while maintaining a robust ranking performance with gains across the BEIR benchmark. Finally, to illustrate the practical effectiveness of listwise LLM rerankers, we investigate their application in providing relevance feedback for retrievers during inference. Our results show that LLM rerankers can provide a stronger distillation signal compared to cross-encoders, yielding substantial improvements in retriever recall after relevance feedback.
Prompts as Auto-Optimized Training Hyperparameters: Training Best-in-Class IR Models from Scratch with 10 Gold Labels
Jun 17, 2024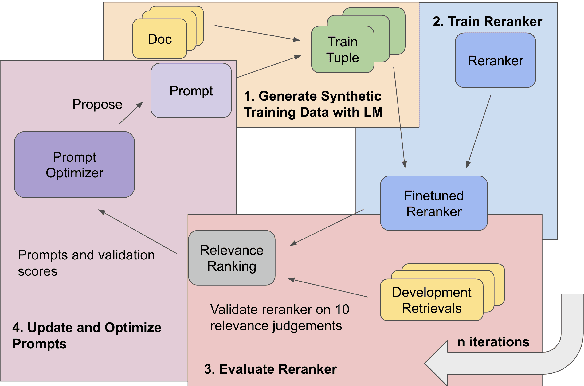
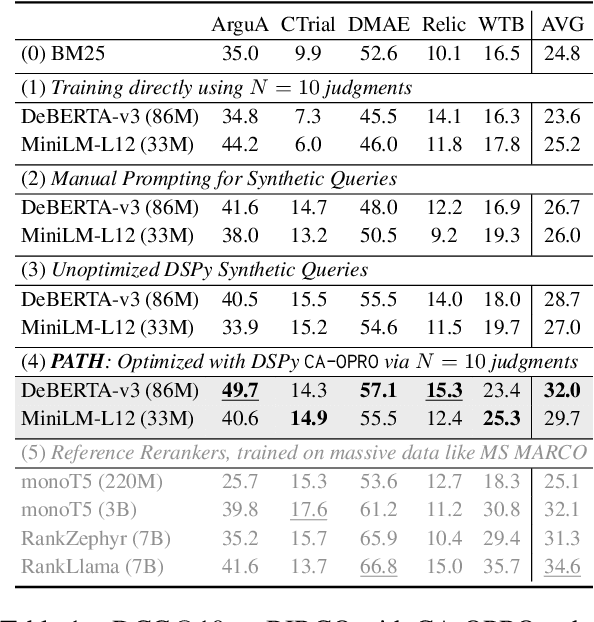
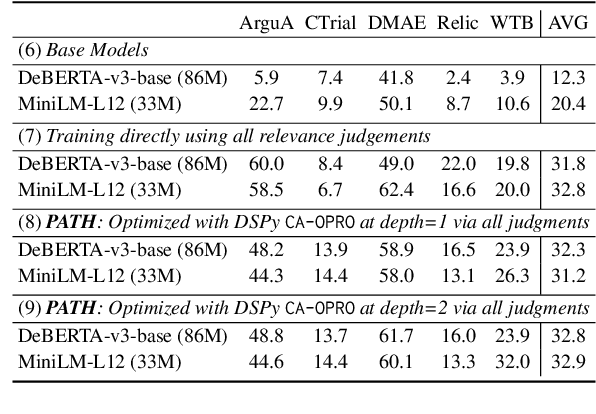

We develop a method for training small-scale (under 100M parameter) neural information retrieval models with as few as 10 gold relevance labels. The method depends on generating synthetic queries for documents using a language model (LM), and the key step is that we automatically optimize the LM prompt that is used to generate these queries based on training quality. In experiments with the BIRCO benchmark, we find that models trained with our method outperform RankZephyr and are competitive with RankLLama, both of which are 7B parameter models trained on over 100K labels. These findings point to the power of automatic prompt optimization for synthetic dataset generation.
Self-Refinement of Language Models from External Proxy Metrics Feedback
Feb 27, 2024



It is often desirable for Large Language Models (LLMs) to capture multiple objectives when providing a response. In document-grounded response generation, for example, agent responses are expected to be relevant to a user's query while also being grounded in a given document. In this paper, we introduce Proxy Metric-based Self-Refinement (ProMiSe), which enables an LLM to refine its own initial response along key dimensions of quality guided by external metrics feedback, yielding an overall better final response. ProMiSe leverages feedback on response quality through principle-specific proxy metrics, and iteratively refines its response one principle at a time. We apply ProMiSe to open source language models Flan-T5-XXL and Llama-2-13B-Chat, to evaluate its performance on document-grounded question answering datasets, MultiDoc2Dial and QuAC, demonstrating that self-refinement improves response quality. We further show that fine-tuning Llama-2-13B-Chat on the synthetic dialogue data generated by ProMiSe yields significant performance improvements over the zero-shot baseline as well as a supervised fine-tuned model on human annotated data.
Structured Chain-of-Thought Prompting for Few-Shot Generation of Content-Grounded QA Conversations
Feb 20, 2024
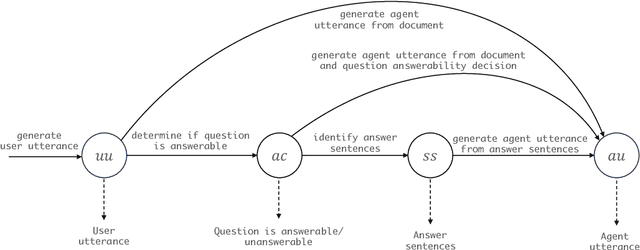


We introduce a structured chain-of-thought (SCoT) prompting approach to generating content-grounded multi-turn question-answer conversations using a pre-trained large language model (LLM). At the core of our proposal is a structured breakdown of the complex task into a number of states in a state machine, so that actions corresponding to various subtasks, e.g., content reading and utterance generation, can be executed in their own dedicated states. Each state leverages a unique set of resources including prompts and (optionally) additional tools to augment the generation process. Our experimental results show that SCoT prompting with designated states for hallucination mitigation increases agent faithfulness to grounding documents by up to 16.8%. When used as training data, our open-domain conversations synthesized from only 6 Wikipedia-based seed demonstrations train strong conversational QA agents; in out-of-domain evaluation, for example, we observe improvements of up to 13.9% over target domain gold data when the latter is augmented with our generated examples.
An Empirical Investigation into the Effect of Parameter Choices in Knowledge Distillation
Jan 12, 2024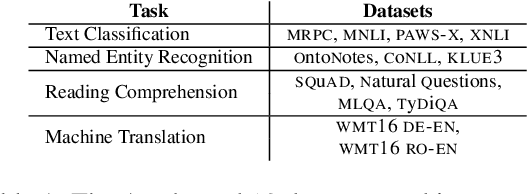



We present a large-scale empirical study of how choices of configuration parameters affect performance in knowledge distillation (KD). An example of such a KD parameter is the measure of distance between the predictions of the teacher and the student, common choices for which include the mean squared error (MSE) and the KL-divergence. Although scattered efforts have been made to understand the differences between such options, the KD literature still lacks a systematic study on their general effect on student performance. We take an empirical approach to this question in this paper, seeking to find out the extent to which such choices influence student performance across 13 datasets from 4 NLP tasks and 3 student sizes. We quantify the cost of making sub-optimal choices and identify a single configuration that performs well across the board.
Multistage Collaborative Knowledge Distillation from Large Language Models
Nov 15, 2023



We study semi-supervised sequence prediction tasks where labeled data are too scarce to effectively finetune a model and at the same time few-shot prompting of a large language model (LLM) has suboptimal performance. This happens when a task, such as parsing, is expensive to annotate and also unfamiliar to a pretrained LLM. In this paper, we present a discovery that student models distilled from a prompted LLM can often generalize better than their teacher on such tasks. Leveraging this finding, we propose a new distillation method, multistage collaborative knowledge distillation from an LLM (MCKD), for such tasks. MCKD first prompts an LLM using few-shot in-context learning to produce pseudolabels for unlabeled data. Then, at each stage of distillation, a pair of students are trained on disjoint partitions of the pseudolabeled data. Each student subsequently produces new and improved pseudolabels for the unseen partition to supervise the next round of student(s) with. We show the benefit of multistage cross-partition labeling on two constituency parsing tasks. On CRAFT biomedical parsing, 3-stage MCKD with 50 labeled examples matches the performance of supervised finetuning with 500 examples and outperforms the prompted LLM and vanilla KD by 7.5% and 3.7% parsing F1, respectively.
Ensemble-Instruct: Generating Instruction-Tuning Data with a Heterogeneous Mixture of LMs
Oct 21, 2023



Using in-context learning (ICL) for data generation, techniques such as Self-Instruct (Wang et al., 2023) or the follow-up Alpaca (Taori et al., 2023) can train strong conversational agents with only a small amount of human supervision. One limitation of these approaches is that they resort to very large language models (around 175B parameters) that are also proprietary and non-public. Here we explore the application of such techniques to language models that are much smaller (around 10B--40B parameters) and have permissive licenses. We find the Self-Instruct approach to be less effective at these sizes and propose new ICL methods that draw on two main ideas: (a) Categorization and simplification of the ICL templates to make prompt learning easier for the LM, and (b) Ensembling over multiple LM outputs to help select high-quality synthetic examples. Our algorithm leverages the 175 Self-Instruct seed tasks and employs separate pipelines for instructions that require an input and instructions that do not. Empirical investigations with different LMs show that: (1) Our proposed method yields higher-quality instruction tuning data than Self-Instruct, (2) It improves performances of both vanilla and instruction-tuned LMs by significant margins, and (3) Smaller instruction-tuned LMs generate more useful outputs than their larger un-tuned counterparts. Our codebase is available at https://github.com/IBM/ensemble-instruct.
Inference-time Re-ranker Relevance Feedback for Neural Information Retrieval
May 19, 2023



Neural information retrieval often adopts a retrieve-and-rerank framework: a bi-encoder network first retrieves K (e.g., 100) candidates that are then re-ranked using a more powerful cross-encoder model to rank the better candidates higher. The re-ranker generally produces better candidate scores than the retriever, but is limited to seeing only the top K retrieved candidates, thus providing no improvements in retrieval performance as measured by Recall@K. In this work, we leverage the re-ranker to also improve retrieval by providing inference-time relevance feedback to the retriever. Concretely, we update the retriever's query representation for a test instance using a lightweight inference-time distillation of the re-ranker's prediction for that instance. The distillation loss is designed to bring the retriever's candidate scores closer to those of the re-ranker. A second retrieval step is then performed with the updated query vector. We empirically show that our approach, which can serve arbitrary retrieve-and-rerank pipelines, significantly improves retrieval recall in multiple domains, languages, and modalities.