 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOtter: Generating Tests from Issues to Validate SWE Patches
Feb 07, 2025While there has been plenty of work on generating tests from existing code, there has been limited work on generating tests from issues. A correct test must validate the code patch that resolves the issue. In this work, we focus on the scenario where the code patch does not exist yet. This approach supports two major use-cases. First, it supports TDD (test-driven development), the discipline of "test first, write code later" that has well-documented benefits for human software engineers. Second, it also validates SWE (software engineering) agents, which generate code patches for resolving issues. This paper introduces Otter, an LLM-based solution for generating tests from issues. Otter augments LLMs with rule-based analysis to check and repair their outputs, and introduces a novel self-reflective action planning stage. Experiments show Otter outperforming state-of-the-art systems for generating tests from issues, in addition to enhancing systems that generate patches from issues. We hope that Otter helps make developers more productive at resolving issues and leads to more robust, well-tested code.
Structured Chain-of-Thought Prompting for Few-Shot Generation of Content-Grounded QA Conversations
Feb 20, 2024
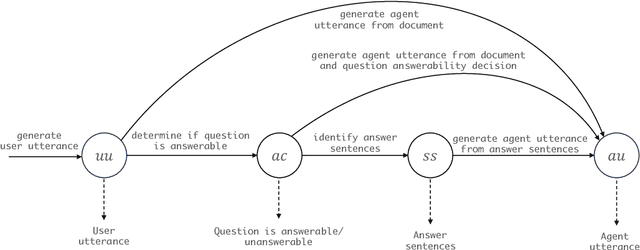


We introduce a structured chain-of-thought (SCoT) prompting approach to generating content-grounded multi-turn question-answer conversations using a pre-trained large language model (LLM). At the core of our proposal is a structured breakdown of the complex task into a number of states in a state machine, so that actions corresponding to various subtasks, e.g., content reading and utterance generation, can be executed in their own dedicated states. Each state leverages a unique set of resources including prompts and (optionally) additional tools to augment the generation process. Our experimental results show that SCoT prompting with designated states for hallucination mitigation increases agent faithfulness to grounding documents by up to 16.8%. When used as training data, our open-domain conversations synthesized from only 6 Wikipedia-based seed demonstrations train strong conversational QA agents; in out-of-domain evaluation, for example, we observe improvements of up to 13.9% over target domain gold data when the latter is augmented with our generated examples.
Evaluating Robustness of Dialogue Summarization Models in the Presence of Naturally Occurring Variations
Nov 15, 2023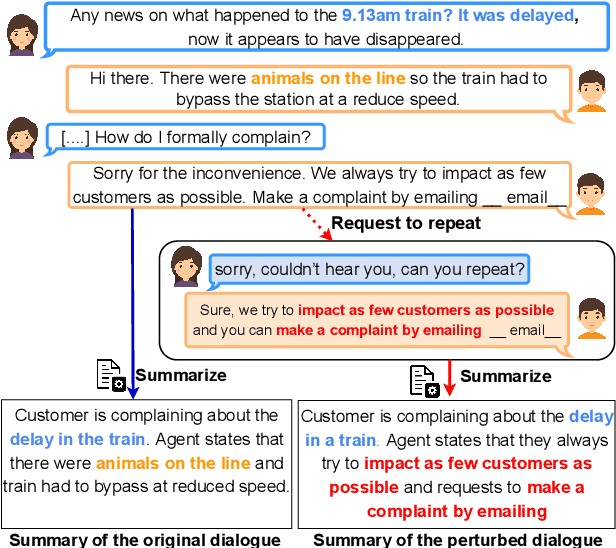
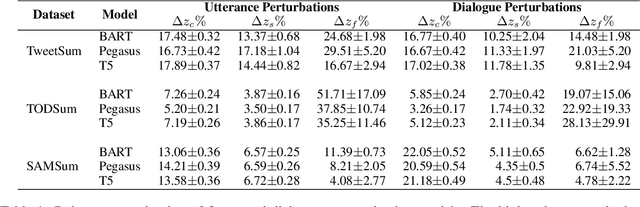
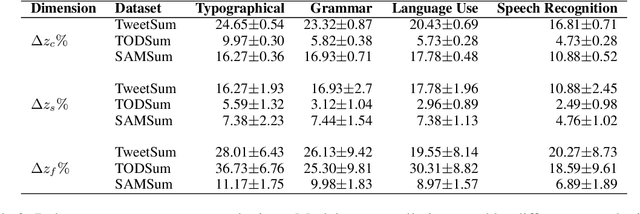
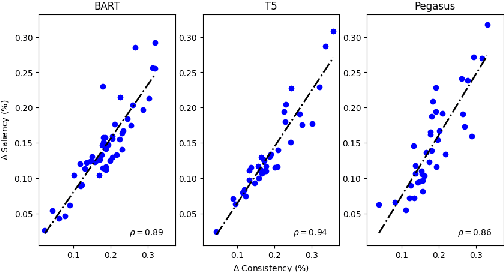
Dialogue summarization task involves summarizing long conversations while preserving the most salient information. Real-life dialogues often involve naturally occurring variations (e.g., repetitions, hesitations) and existing dialogue summarization models suffer from performance drop on such conversations. In this study, we systematically investigate the impact of such variations on state-of-the-art dialogue summarization models using publicly available datasets. To simulate real-life variations, we introduce two types of perturbations: utterance-level perturbations that modify individual utterances with errors and language variations, and dialogue-level perturbations that add non-informative exchanges (e.g., repetitions, greetings). We conduct our analysis along three dimensions of robustness: consistency, saliency, and faithfulness, which capture different aspects of the summarization model's performance. We find that both fine-tuned and instruction-tuned models are affected by input variations, with the latter being more susceptible, particularly to dialogue-level perturbations. We also validate our findings via human evaluation. Finally, we investigate if the robustness of fine-tuned models can be improved by training them with a fraction of perturbed data and observe that this approach is insufficient to address robustness challenges with current models and thus warrants a more thorough investigation to identify better solutions. Overall, our work highlights robustness challenges in dialogue summarization and provides insights for future research.
Towards End-to-End Integration of Dialog History for Improved Spoken Language Understanding
Apr 11, 2022

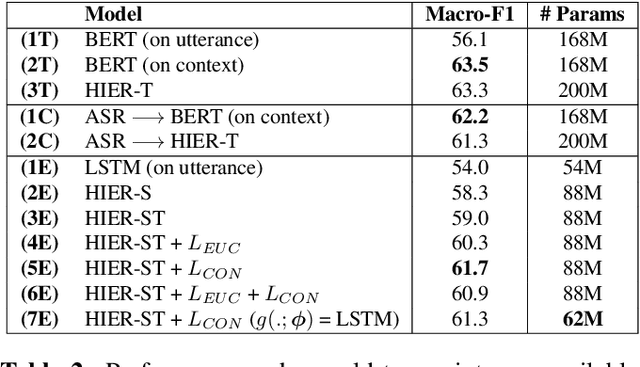

Dialog history plays an important role in spoken language understanding (SLU) performance in a dialog system. For end-to-end (E2E) SLU, previous work has used dialog history in text form, which makes the model dependent on a cascaded automatic speech recognizer (ASR). This rescinds the benefits of an E2E system which is intended to be compact and robust to ASR errors. In this paper, we propose a hierarchical conversation model that is capable of directly using dialog history in speech form, making it fully E2E. We also distill semantic knowledge from the available gold conversation transcripts by jointly training a similar text-based conversation model with an explicit tying of acoustic and semantic embeddings. We also propose a novel technique that we call DropFrame to deal with the long training time incurred by adding dialog history in an E2E manner. On the HarperValleyBank dialog dataset, our E2E history integration outperforms a history independent baseline by 7.7% absolute F1 score on the task of dialog action recognition. Our model performs competitively with the state-of-the-art history based cascaded baseline, but uses 48% fewer parameters. In the absence of gold transcripts to fine-tune an ASR model, our model outperforms this baseline by a significant margin of 10% absolute F1 score.
Integrating Dialog History into End-to-End Spoken Language Understanding Systems
Aug 18, 2021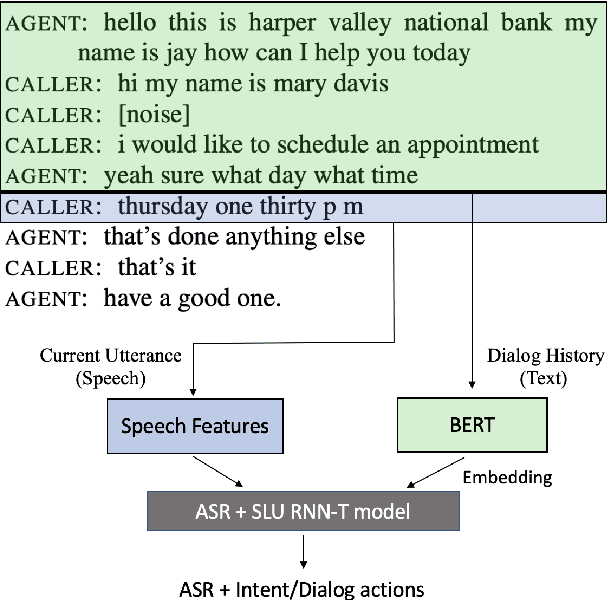

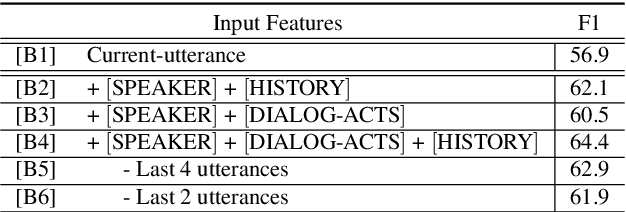
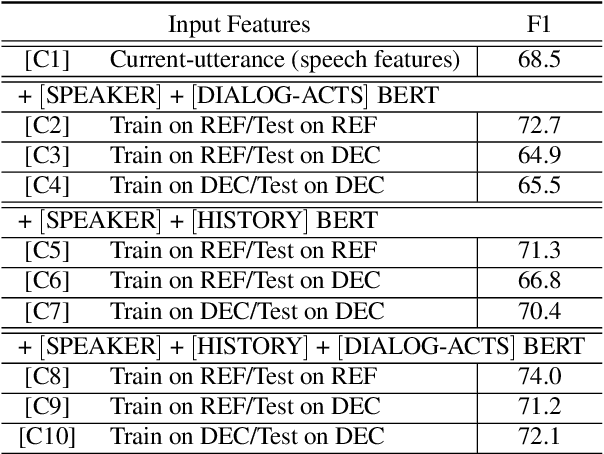
End-to-end spoken language understanding (SLU) systems that process human-human or human-computer interactions are often context independent and process each turn of a conversation independently. Spoken conversations on the other hand, are very much context dependent, and dialog history contains useful information that can improve the processing of each conversational turn. In this paper, we investigate the importance of dialog history and how it can be effectively integrated into end-to-end SLU systems. While processing a spoken utterance, our proposed RNN transducer (RNN-T) based SLU model has access to its dialog history in the form of decoded transcripts and SLU labels of previous turns. We encode the dialog history as BERT embeddings, and use them as an additional input to the SLU model along with the speech features for the current utterance. We evaluate our approach on a recently released spoken dialog data set, the HarperValleyBank corpus. We observe significant improvements: 8% for dialog action and 30% for caller intent recognition tasks, in comparison to a competitive context independent end-to-end baseline system.
Explaining Neural Network Predictions on Sentence Pairs via Learning Word-Group Masks
Apr 13, 2021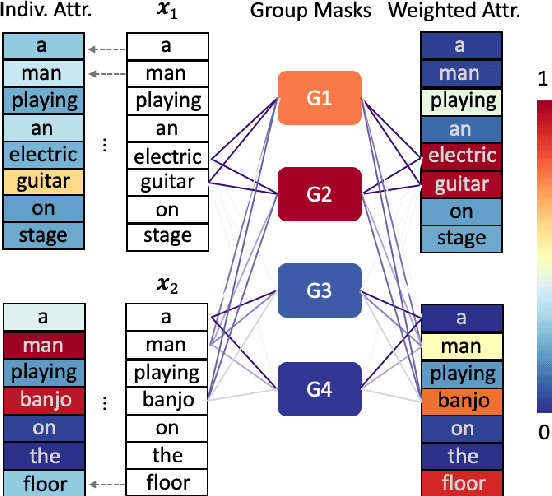
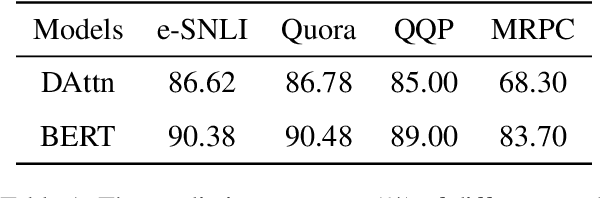
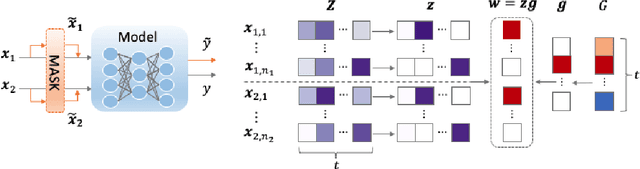
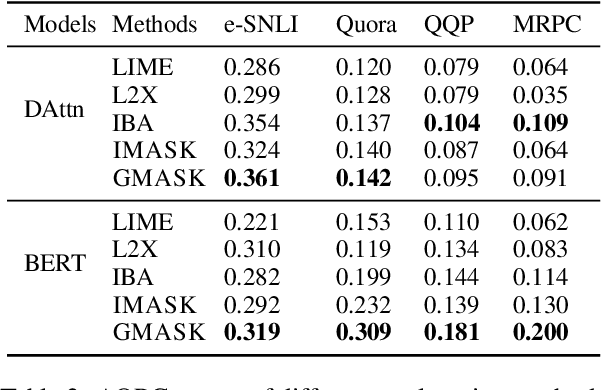
Explaining neural network models is important for increasing their trustworthiness in real-world applications. Most existing methods generate post-hoc explanations for neural network models by identifying individual feature attributions or detecting interactions between adjacent features. However, for models with text pairs as inputs (e.g., paraphrase identification), existing methods are not sufficient to capture feature interactions between two texts and their simple extension of computing all word-pair interactions between two texts is computationally inefficient. In this work, we propose the Group Mask (GMASK) method to implicitly detect word correlations by grouping correlated words from the input text pair together and measure their contribution to the corresponding NLP tasks as a whole. The proposed method is evaluated with two different model architectures (decomposable attention model and BERT) across four datasets, including natural language inference and paraphrase identification tasks. Experiments show the effectiveness of GMASK in providing faithful explanations to these models.
Does Dialog Length matter for Next Response Selection task? An Empirical Study
Jan 24, 2021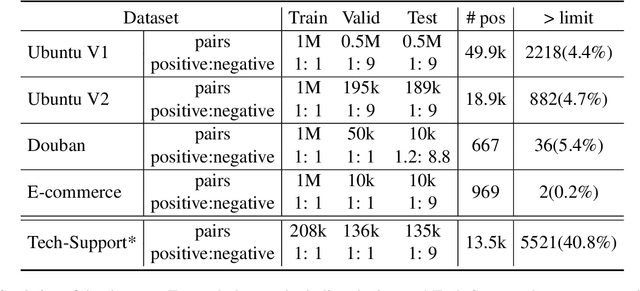
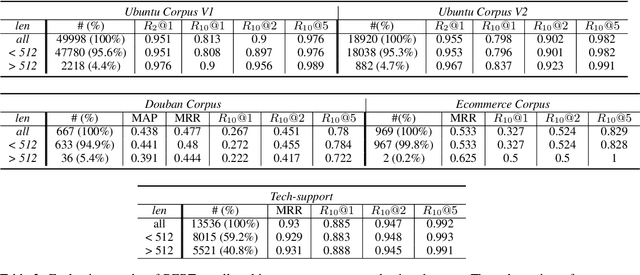
In the last few years, the release of BERT, a multilingual transformer based model, has taken the NLP community by storm. BERT-based models have achieved state-of-the-art results on various NLP tasks, including dialog tasks. One of the limitation of BERT is the lack of ability to handle long text sequence. By default, BERT has a maximum wordpiece token sequence length of 512. Recently, there has been renewed interest to tackle the BERT limitation to handle long text sequences with the addition of new self-attention based architectures. However, there has been little to no research on the impact of this limitation with respect to dialog tasks. Dialog tasks are inherently different from other NLP tasks due to: a) the presence of multiple utterances from multiple speakers, which may be interlinked to each other across different turns and b) longer length of dialogs. In this work, we empirically evaluate the impact of dialog length on the performance of BERT model for the Next Response Selection dialog task on four publicly available and one internal multi-turn dialog datasets. We observe that there is little impact on performance with long dialogs and even the simplest approach of truncating input works really well.
Conversational Document Prediction to Assist Customer Care Agents
Oct 05, 2020
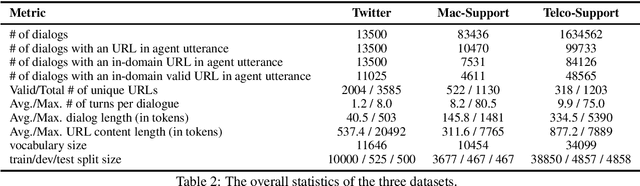

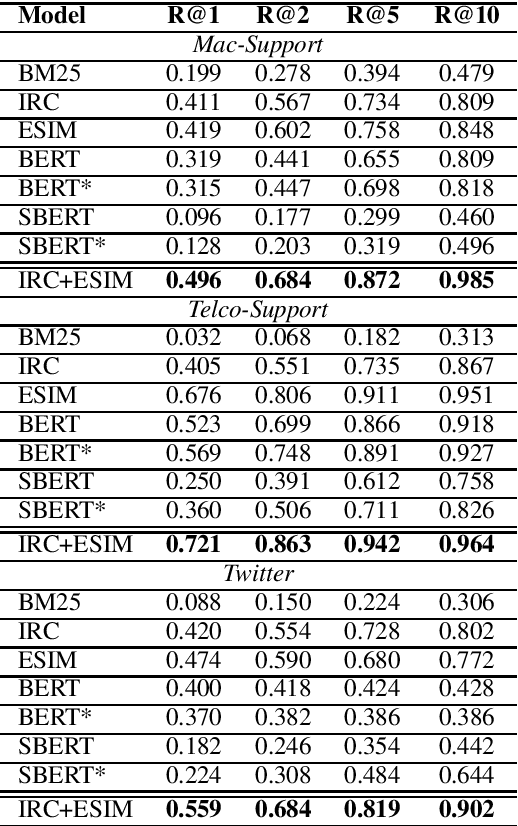
A frequent pattern in customer care conversations is the agents responding with appropriate webpage URLs that address users' needs. We study the task of predicting the documents that customer care agents can use to facilitate users' needs. We also introduce a new public dataset which supports the aforementioned problem. Using this dataset and two others, we investigate state-of-the art deep learning (DL) and information retrieval (IR) models for the task. Additionally, we analyze the practicality of such systems in terms of inference time complexity. Our show that an hybrid IR+DL approach provides the best of both worlds.
Effects of Naturalistic Variation in Goal-Oriented Dialog
Oct 05, 2020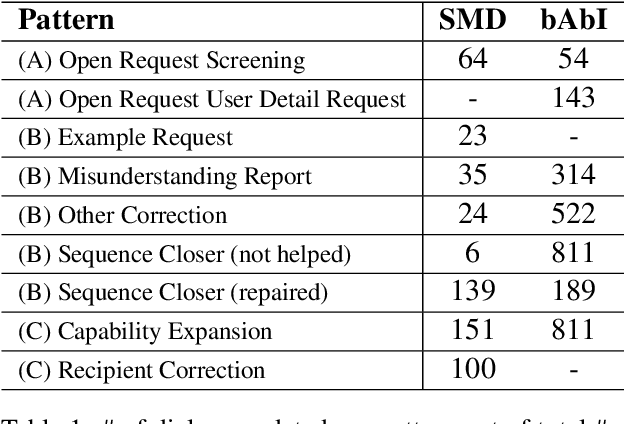
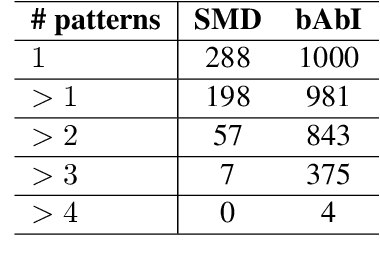
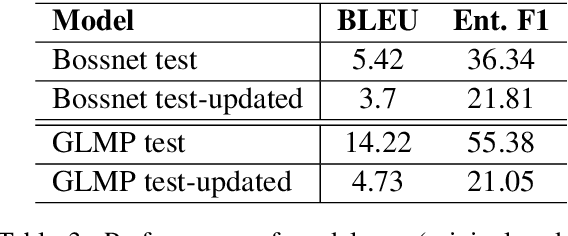
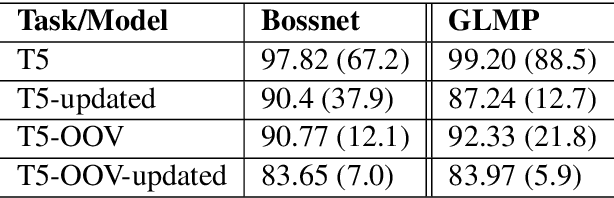
Existing benchmarks used to evaluate the performance of end-to-end neural dialog systems lack a key component: natural variation present in human conversations. Most datasets are constructed through crowdsourcing, where the crowd workers follow a fixed template of instructions while enacting the role of a user/agent. This results in straight-forward, somewhat routine, and mostly trouble-free conversations, as crowd workers do not think to represent the full range of actions that occur naturally with real users. In this work, we investigate the impact of naturalistic variation on two goal-oriented datasets: bAbI dialog task and Stanford Multi-Domain Dataset (SMD). We also propose new and more effective testbeds for both datasets, by introducing naturalistic variation by the user. We observe that there is a significant drop in performance (more than 60% in Ent. F1 on SMD and 85% in per-dialog accuracy on bAbI task) of recent state-of-the-art end-to-end neural methods such as BossNet and GLMP on both datasets.
Learning End-to-End Goal-Oriented Dialog with Maximal User Task Success and Minimal Human Agent Use
Jul 17, 2019Neural end-to-end goal-oriented dialog systems showed promise to reduce the workload of human agents for customer service, as well as reduce wait time for users. However, their inability to handle new user behavior at deployment has limited their usage in real world. In this work, we propose an end-to-end trainable method for neural goal-oriented dialog systems which handles new user behaviors at deployment by transferring the dialog to a human agent intelligently. The proposed method has three goals: 1) maximize user's task success by transferring to human agents, 2) minimize the load on the human agents by transferring to them only when it is essential and 3) learn online from the human agent's responses to reduce human agents load further. We evaluate our proposed method on a modified-bAbI dialog task that simulates the scenario of new user behaviors occurring at test time. Experimental results show that our proposed method is effective in achieving the desired goals.
* Author final version of article accepted for publication in TACL - https://www.mitpressjournals.org/doi/full/10.1162/tacl_a_00274 and oral presentation at ACL 2019