 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 3-D Full-Wave Model to Study the Impact of Soybean Components and Structure on L-Band Backscatter
Feb 03, 2024Microwave remote sensing offers a powerful tool for monitoring the growth of short, dense vegetation like soybean. As the plants mature, changes in their biomass and 3-D structure impact the electromagnetic (EM) backscatter signal. This backscatter information holds valuable insights into crop health and yield, prompting the need for a comprehensive understanding of how structural and biophysical properties of soybeans as well as soil characteristics contribute to the overall backscatter signature. In this study, a full-wave model is developed for simulating L-band backscatter from soybean fields. Leveraging the ANSYS High-Frequency Structure Simulator (HFSS) framework, the model solves for the scattering of EM waves from realistic 3-D structural models of soybean, explicitly incorporating the interplant scattering effects. The model estimates of backscatter match well with the field observations from the SMAPVEX16-MicroWEX and SMAPVEX12, with average differences of 1-2 dB for co-pol and less than 4 dB for cross-pol. Furthermore, the model effectively replicates the temporal dynamics of crop backscatter throughout the growing season. The HFSS analysis revealed that the stems and pods are the primary contributors to HH-pol backscatter, while the branches contribute to VV-pol, and leaves impact the cross-pol signatures. In addition, a sensitivity study with 3-D bare soil surface resulted in an average variation of 8 dB in co- and cross-pol, even when the root mean square height and correlation length were held constant.
Effects of Naturalistic Variation in Goal-Oriented Dialog
Oct 05, 2020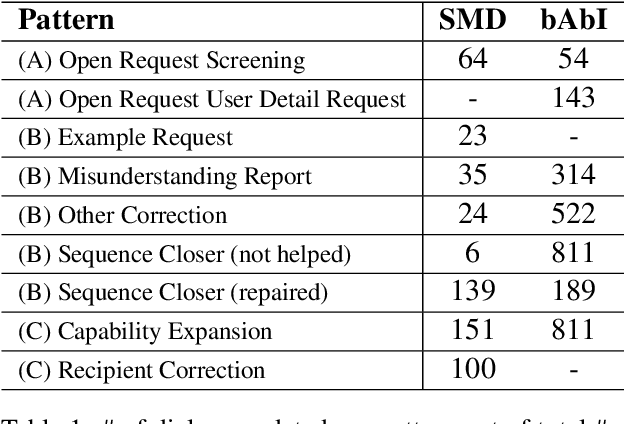
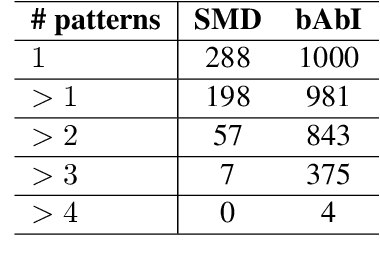
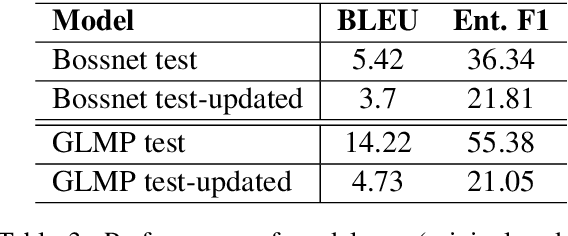
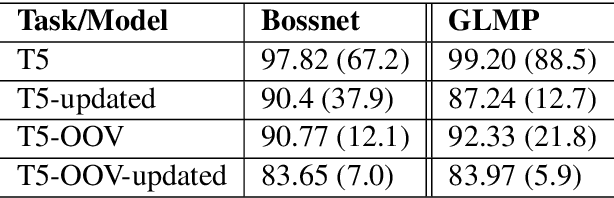
Existing benchmarks used to evaluate the performance of end-to-end neural dialog systems lack a key component: natural variation present in human conversations. Most datasets are constructed through crowdsourcing, where the crowd workers follow a fixed template of instructions while enacting the role of a user/agent. This results in straight-forward, somewhat routine, and mostly trouble-free conversations, as crowd workers do not think to represent the full range of actions that occur naturally with real users. In this work, we investigate the impact of naturalistic variation on two goal-oriented datasets: bAbI dialog task and Stanford Multi-Domain Dataset (SMD). We also propose new and more effective testbeds for both datasets, by introducing naturalistic variation by the user. We observe that there is a significant drop in performance (more than 60% in Ent. F1 on SMD and 85% in per-dialog accuracy on bAbI task) of recent state-of-the-art end-to-end neural methods such as BossNet and GLMP on both datasets.
A Tool for Collecting Domain Dependent Sortal Constraints From Corpora
Jan 31, 1995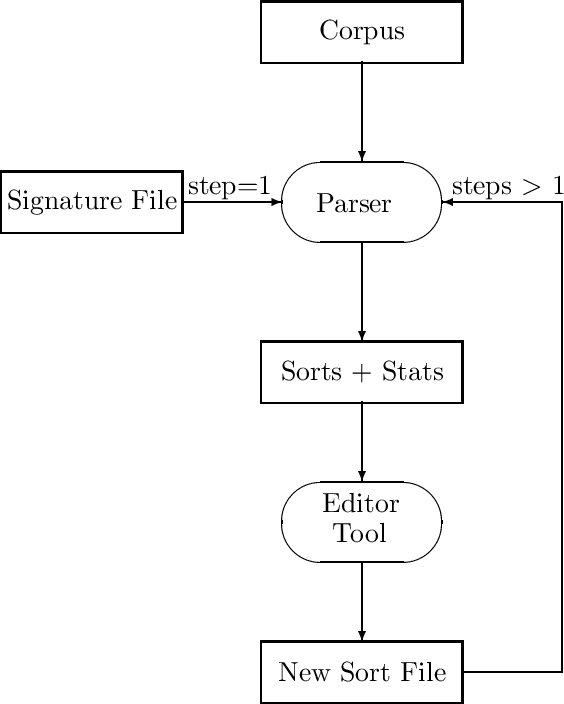
In this paper, we describe a tool designed to generate semi-automatically the sortal constraints specific to a domain to be used in a natural language (NL) understanding system. This tool is evaluated using the SRI Gemini NL understanding system in the ATIS domain.
GEMINI: A Natural Language System for Spoken-Language Understanding
Jul 05, 1994
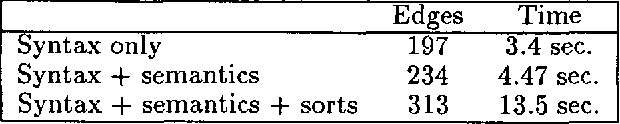
Gemini is a natural language understanding system developed for spoken language applications. The paper describes the architecture of Gemini, paying particular attention to resolving the tension between robustness and overgeneration. Gemini features a broad-coverage unification-based grammar of English, fully interleaved syntactic and semantic processing in an all-paths, bottom-up parser, and an utterance-level parser to find interpretations of sentences that might not be analyzable as complete sentences. Gemini also includes novel components for recognizing and correcting grammatical disfluencies, and for doing parse preferences. This paper presents a component-by-component view of Gemini, providing detailed relevant measurements of size, efficiency, and performance.
* 8 pages, postscript
Interleaving Syntax and Semantics in an Efficient Bottom-Up Parser
Jul 05, 1994
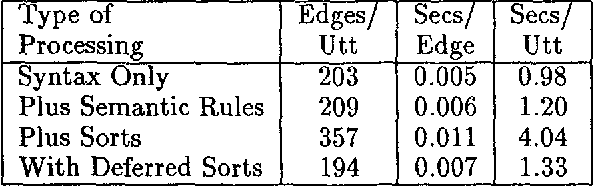
We describe an efficient bottom-up parser that interleaves syntactic and semantic structure building. Two techniques are presented for reducing search by reducing local ambiguity: Limited left-context constraints are used to reduce local syntactic ambiguity, and deferred sortal-constraint application is used to reduce local semantic ambiguity. We experimentally evaluate these techniques, and show dramatic reductions in both number of chart-edges and total parsing time. The robust processing capabilities of the parser are demonstrated in its use in improving the accuracy of a speech recognizer.
* 8 pages, postscript