 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 3-D Full-Wave Model to Study the Impact of Soybean Components and Structure on L-Band Backscatter
Feb 03, 2024Microwave remote sensing offers a powerful tool for monitoring the growth of short, dense vegetation like soybean. As the plants mature, changes in their biomass and 3-D structure impact the electromagnetic (EM) backscatter signal. This backscatter information holds valuable insights into crop health and yield, prompting the need for a comprehensive understanding of how structural and biophysical properties of soybeans as well as soil characteristics contribute to the overall backscatter signature. In this study, a full-wave model is developed for simulating L-band backscatter from soybean fields. Leveraging the ANSYS High-Frequency Structure Simulator (HFSS) framework, the model solves for the scattering of EM waves from realistic 3-D structural models of soybean, explicitly incorporating the interplant scattering effects. The model estimates of backscatter match well with the field observations from the SMAPVEX16-MicroWEX and SMAPVEX12, with average differences of 1-2 dB for co-pol and less than 4 dB for cross-pol. Furthermore, the model effectively replicates the temporal dynamics of crop backscatter throughout the growing season. The HFSS analysis revealed that the stems and pods are the primary contributors to HH-pol backscatter, while the branches contribute to VV-pol, and leaves impact the cross-pol signatures. In addition, a sensitivity study with 3-D bare soil surface resulted in an average variation of 8 dB in co- and cross-pol, even when the root mean square height and correlation length were held constant.
In-Season Crop Progress in Unsurveyed Regions using Networks Trained on Synthetic Data
Dec 13, 2022Many commodity crops have growth stages during which they are particularly vulnerable to stress-induced yield loss. In-season crop progress information is useful for quantifying crop risk, and satellite remote sensing (RS) can be used to track progress at regional scales. At present, all existing RS-based crop progress estimation (CPE) methods which target crop-specific stages rely on ground truth data for training/calibration. This reliance on ground survey data confines CPE methods to surveyed regions, limiting their utility. In this study, a new method is developed for conducting RS-based in-season CPE in unsurveyed regions by combining data from surveyed regions with synthetic crop progress data generated for an unsurveyed region. Corn-growing zones in Argentina were used as surrogate 'unsurveyed' regions. Existing weather generation, crop growth, and optical radiative transfer models were linked to produce synthetic weather, crop progress, and canopy reflectance data. A neural network (NN) method based upon bi-directional Long Short-Term Memory was trained separately on surveyed data, synthetic data, and two different combinations of surveyed and synthetic data. A stopping criterion was developed which uses the weighted divergence of surveyed and synthetic data validation loss. Net F1 scores across all crop progress stages increased by 8.7% when trained on a combination of surveyed region and synthetic data, and overall performance was only 21% lower than when the NN was trained on surveyed data and applied in the US Midwest. Performance gain from synthetic data was greatest in zones with dual planting windows, while the inclusion of surveyed region data from the US Midwest helped mitigate NN sensitivity to noise in NDVI data. Overall results suggest in-season CPE in other unsurveyed regions may be possible with increased quantity and variety of synthetic crop progress data.
Domain-guided Machine Learning for Remotely Sensed In-Season Crop Growth Estimation
Jun 24, 2021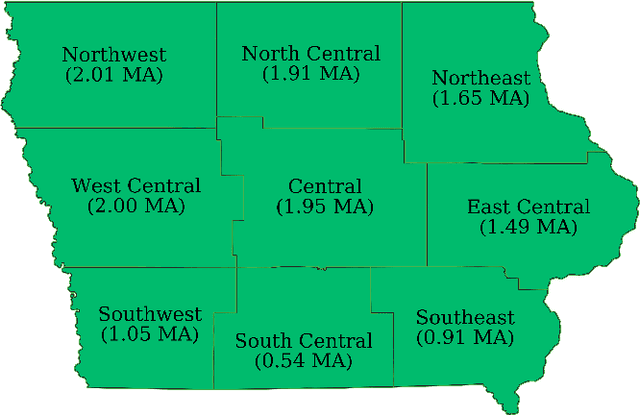
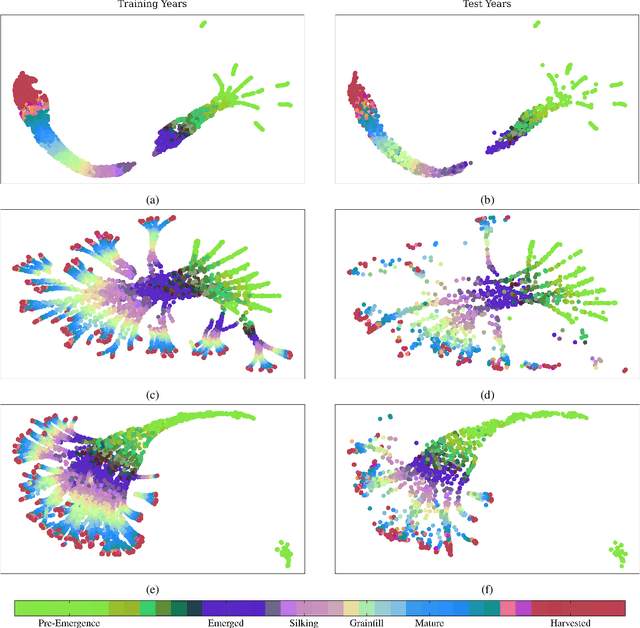
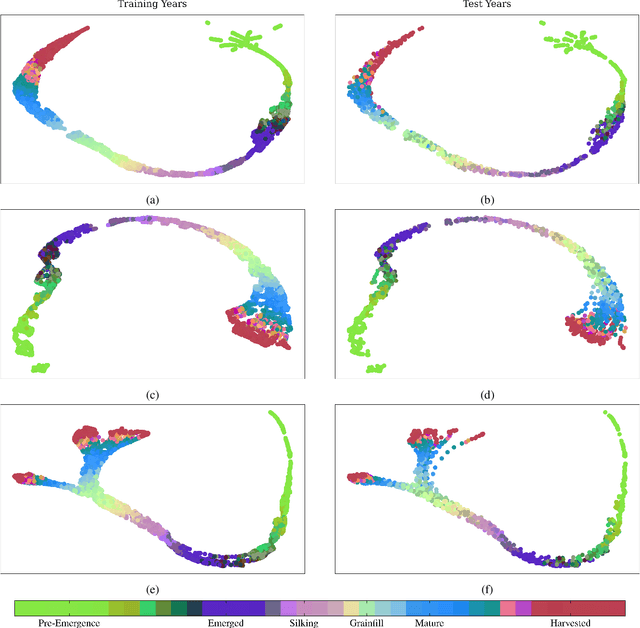
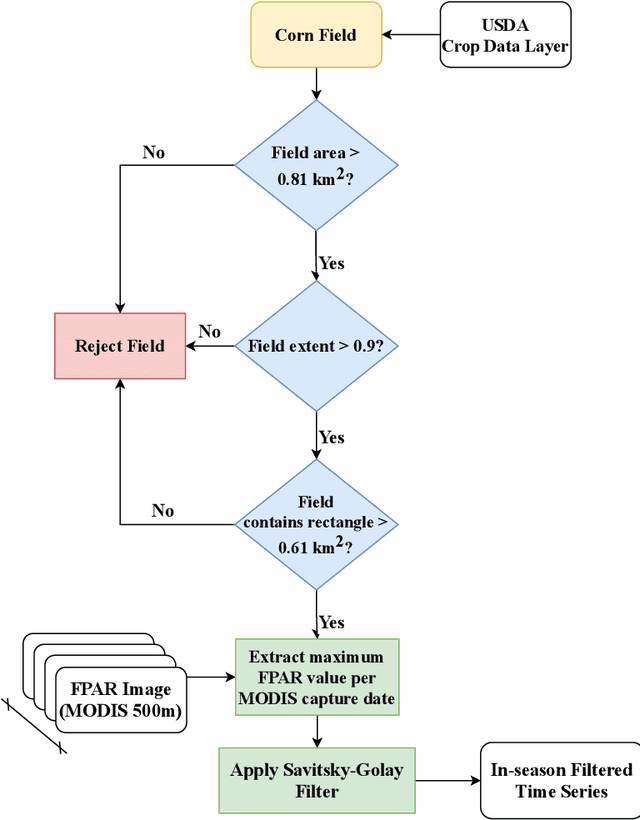
Advanced machine learning techniques have been used in remote sensing (RS) applications such as crop mapping and yield prediction, but remain under-utilized for tracking crop progress. In this study, we demonstrate the use of agronomic knowledge of crop growth drivers in a Long Short-Term Memory-based, Domain-guided neural network (DgNN) for in-season crop progress estimation. The DgNN uses a branched structure and attention to separate independent crop growth drivers and capture their varying importance throughout the growing season. The DgNN is implemented for corn, using RS data in Iowa for the period 2003-2019, with USDA crop progress reports used as ground truth. State-wide DgNN performance shows significant improvement over sequential and dense-only NN structures, and a widely-used Hidden Markov Model method. The DgNN had a 3.5% higher Nash-Sutfliffe efficiency over all growth stages and 33% more weeks with highest cosine similarity than the other NNs during test years. The DgNN and Sequential NN were more robust during periods of abnormal crop progress, though estimating the Silking-Grainfill transition was difficult for all methods. Finally, Uniform Manifold Approximation and Projection visualizations of layer activations showed how LSTM-based NNs separate crop growth time-series differently from a dense-only structure. Results from this study exhibit both the viability of NNs in crop growth stage estimation (CGSE) and the benefits of using domain knowledge. The DgNN methodology presented here can be extended to provide near-real time CGSE of other crops.
Disaggregation of SMAP L3 Brightness Temperatures to 9km using Kernel Machines
Feb 11, 2016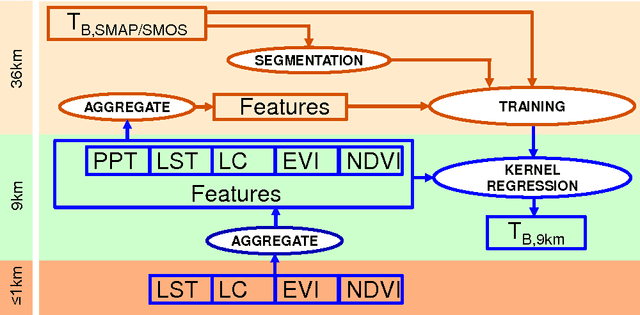
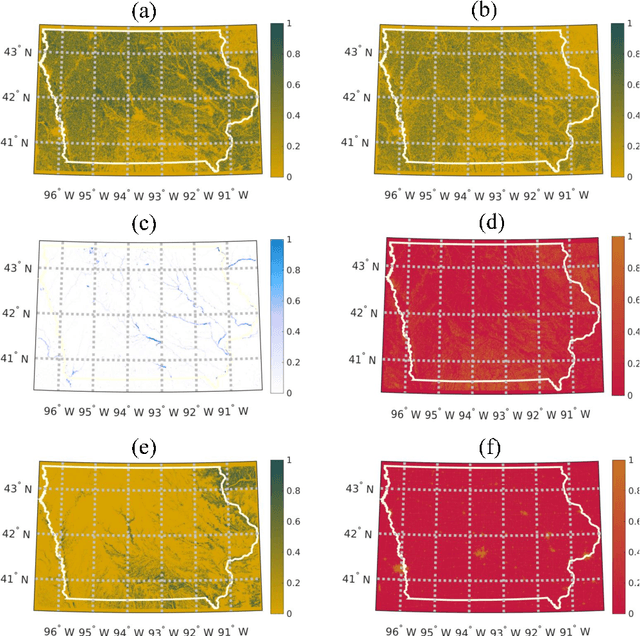
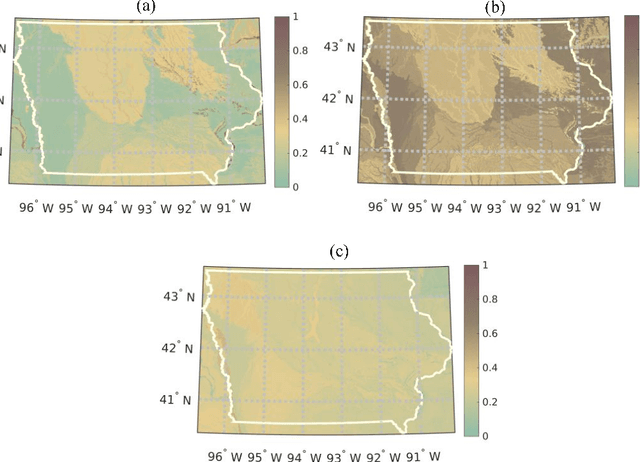
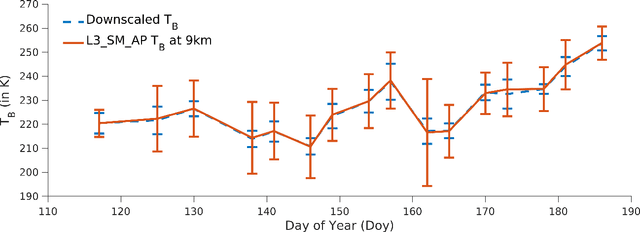
In this study, a machine learning algorithm is used for disaggregation of SMAP brightness temperatures (T$_{\textrm{B}}$) from 36km to 9km. It uses image segmentation to cluster the study region based on meteorological and land cover similarity, followed by a support vector machine based regression that computes the value of the disaggregated T$_{\textrm{B}}$ at all pixels. High resolution remote sensing products such as land surface temperature, normalized difference vegetation index, enhanced vegetation index, precipitation, soil texture, and land-cover were used for disaggregation. The algorithm was implemented in Iowa, United States, from April to July 2015, and compared with the SMAP L3_SM_AP T$_{\textrm{B}}$ product at 9km. It was found that the disaggregated T$_{\textrm{B}}$ were very similar to the SMAP-T$_{\textrm{B}}$ product, even for vegetated areas with a mean difference $\leq$ 5K. However, the standard deviation of the disaggregation was lower by 7K than that of the AP product. The probability density functions of the disaggregated T$_{\textrm{B}}$ were similar to the SMAP-T$_{\textrm{B}}$. The results indicate that this algorithm may be used for disaggregating T$_{\textrm{B}}$ using complex non-linear correlations on a grid.
Spatial Scaling of Satellite Soil Moisture using Temporal Correlations and Ensemble Learning
Jan 21, 2016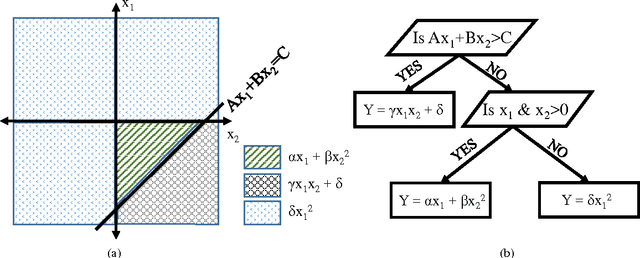
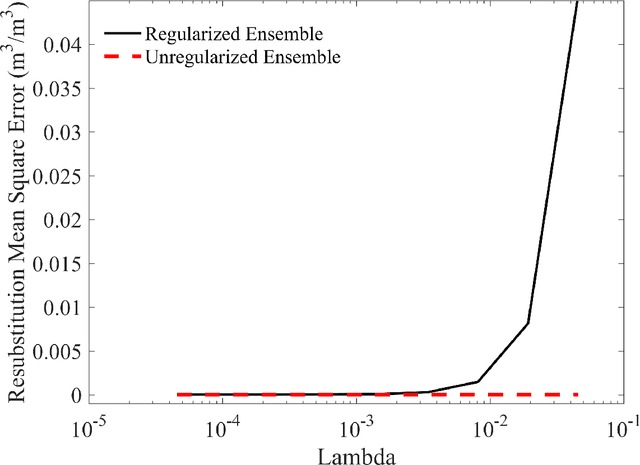
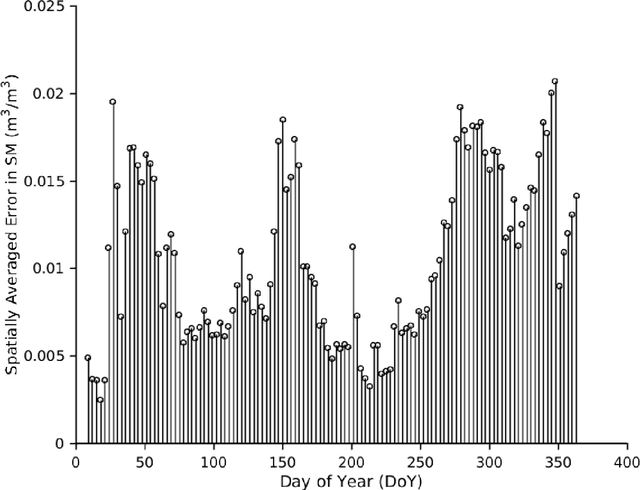
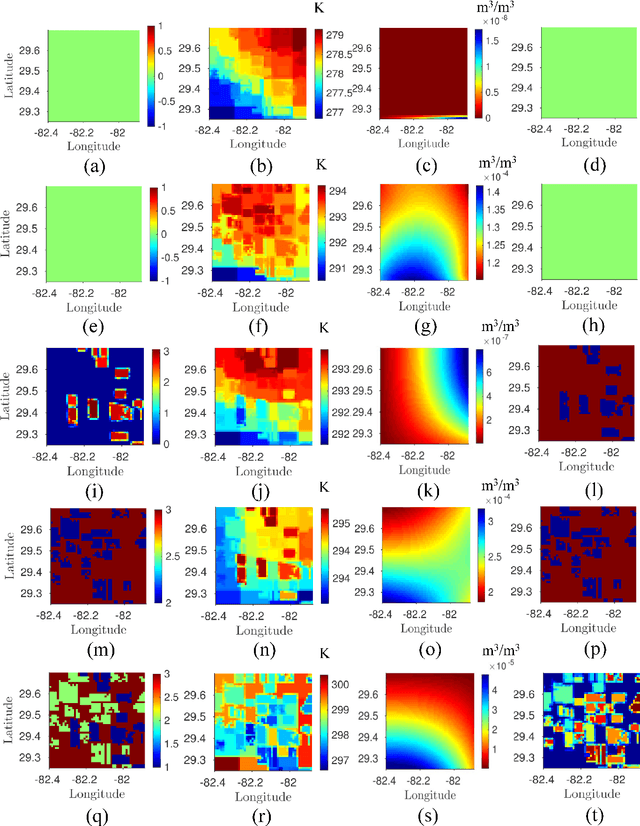
A novel algorithm is developed to downscale soil moisture (SM), obtained at satellite scales of 10-40 km by utilizing its temporal correlations to historical auxiliary data at finer scales. Including such correlations drastically reduces the size of the training set needed, accounts for time-lagged relationships, and enables downscaling even in the presence of short gaps in the auxiliary data. The algorithm is based upon bagged regression trees (BRT) and uses correlations between high-resolution remote sensing products and SM observations. The algorithm trains multiple regression trees and automatically chooses the trees that generate the best downscaled estimates. The algorithm was evaluated using a multi-scale synthetic dataset in north central Florida for two years, including two growing seasons of corn and one growing season of cotton per year. The time-averaged error across the region was found to be 0.01 $\mathrm{m}^3/\mathrm{m}^3$, with a standard deviation of 0.012 $\mathrm{m}^3/\mathrm{m}^3$ when 0.02% of the data were used for training in addition to temporal correlations from the past seven days, and all available data from the past year. The maximum spatially averaged errors obtained using this algorithm in downscaled SM were 0.005 $\mathrm{m}^3/\mathrm{m}^3$, for pixels with cotton land-cover. When land surface temperature~(LST) on the day of downscaling was not included in the algorithm to simulate "data gaps", the spatially averaged error increased minimally by 0.015 $\mathrm{m}^3/\mathrm{m}^3$ when LST is unavailable on the day of downscaling. The results indicate that the BRT-based algorithm provides high accuracy for downscaling SM using complex non-linear spatio-temporal correlations, under heterogeneous micro meteorological conditions.
Disaggregation of Remotely Sensed Soil Moisture in Heterogeneous Landscapes using Holistic Structure based Models
Jan 20, 2016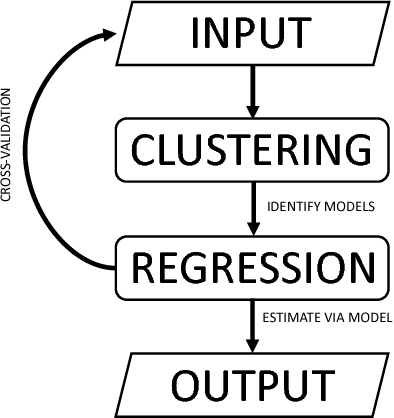
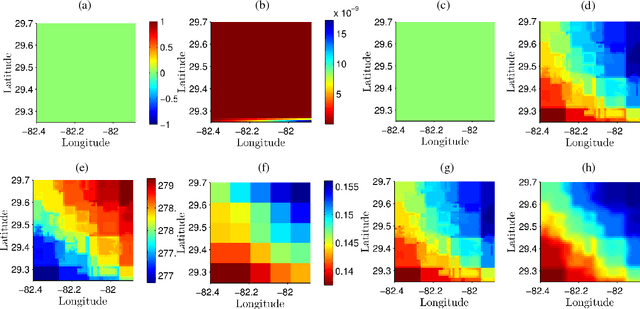
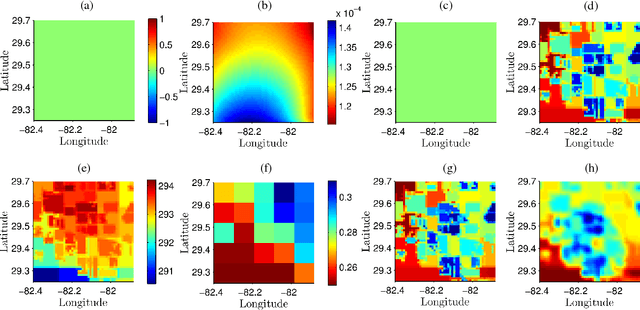
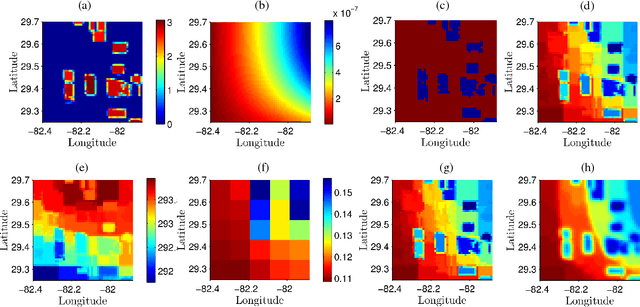
In this study, a novel machine learning algorithm is presented for disaggregation of satellite soil moisture (SM) based on self-regularized regressive models (SRRM) using high-resolution correlated information from auxiliary sources. It includes regularized clustering that assigns soft memberships to each pixel at fine-scale followed by a kernel regression that computes the value of the desired variable at all pixels. Coarse-scale remotely sensed SM were disaggregated from 10km to 1km using land cover, precipitation, land surface temperature, leaf area index, and in-situ observations of SM. This algorithm was evaluated using multi-scale synthetic observations in NC Florida for heterogeneous agricultural land covers. It was found that the root mean square error (RMSE) for 96% of the pixels was less than 0.02 $m^3/m^3$. The clusters generated represented the data well and reduced the RMSE by upto 40% during periods of high heterogeneity in land-cover and meteorological conditions. The Kullback Leibler divergence (KLD) between the true SM and the disaggregated estimates is close to 0, for both vegetated and baresoil landcovers. The disaggregated estimates were compared to those generated by the Principle of Relevant Information (PRI) method. The RMSE for the PRI disaggregated estimates is higher than the RMSE for the SRRM on each day of the season. The KLD of the disaggregated estimates generated by the SRRM is at least four orders of magnitude lower than those for the PRI disaggregated estimates, while the computational time needed was reduced by three times. The results indicate that the SRRM can be used for disaggregating SM with complex non-linear correlations on a grid with high accuracy.
* 28 pages, 14 figures, submitted to IEEE Transactions on Geoscience and Remote Sensing
Downscaling Microwave Brightness Temperatures Using Self Regularized Regressive Models
Jan 30, 2015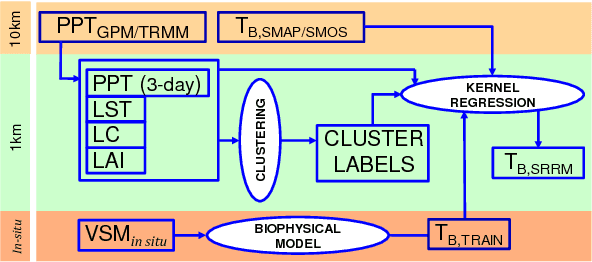
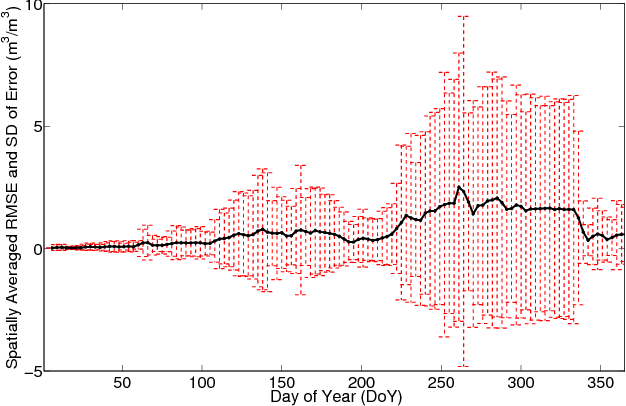
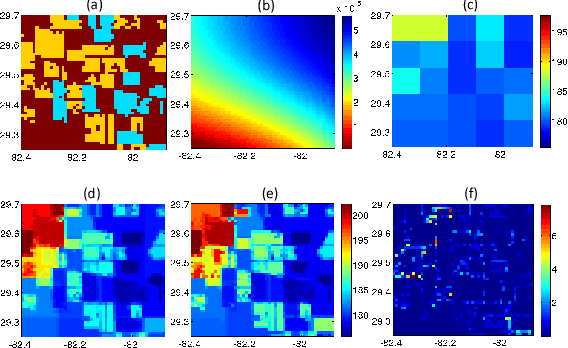
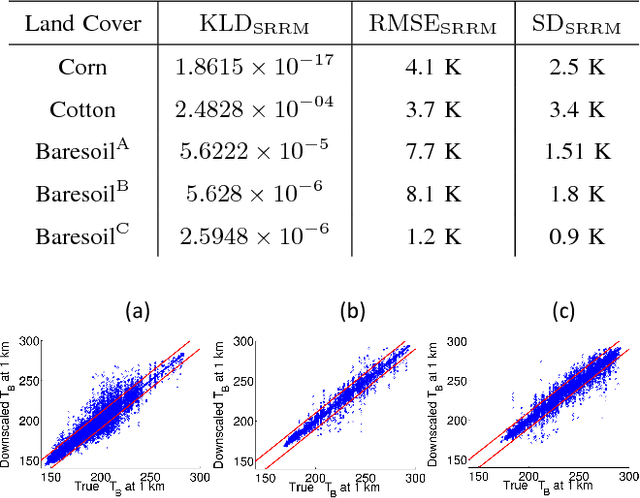
A novel algorithm is proposed to downscale microwave brightness temperatures ($\mathrm{T_B}$), at scales of 10-40 km such as those from the Soil Moisture Active Passive mission to a resolution meaningful for hydrological and agricultural applications. This algorithm, called Self-Regularized Regressive Models (SRRM), uses auxiliary variables correlated to $\mathrm{T_B}$ along-with a limited set of \textit{in-situ} SM observations, which are converted to high resolution $\mathrm{T_B}$ observations using biophysical models. It includes an information-theoretic clustering step based on all auxiliary variables to identify areas of similarity, followed by a kernel regression step that produces downscaled $\mathrm{T_B}$. This was implemented on a multi-scale synthetic data-set over NC-Florida for one year. An RMSE of 5.76~K with standard deviation of 2.8~k was achieved during the vegetated season and an RMSE of 1.2~K with a standard deviation of 0.9~K during periods of no vegetation.