 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenie: Achieving Human Parity in Content-Grounded Datasets Generation
Jan 25, 2024The lack of high-quality data for content-grounded generation tasks has been identified as a major obstacle to advancing these tasks. To address this gap, we propose Genie, a novel method for automatically generating high-quality content-grounded data. It consists of three stages: (a) Content Preparation, (b) Generation: creating task-specific examples from the content (e.g., question-answer pairs or summaries). (c) Filtering mechanism aiming to ensure the quality and faithfulness of the generated data. We showcase this methodology by generating three large-scale synthetic data, making wishes, for Long-Form Question-Answering (LFQA), summarization, and information extraction. In a human evaluation, our generated data was found to be natural and of high quality. Furthermore, we compare models trained on our data with models trained on human-written data -- ELI5 and ASQA for LFQA and CNN-DailyMail for Summarization. We show that our models are on par with or outperforming models trained on human-generated data and consistently outperforming them in faithfulness. Finally, we applied our method to create LFQA data within the medical domain and compared a model trained on it with models trained on other domains.
Conversational Document Prediction to Assist Customer Care Agents
Oct 05, 2020
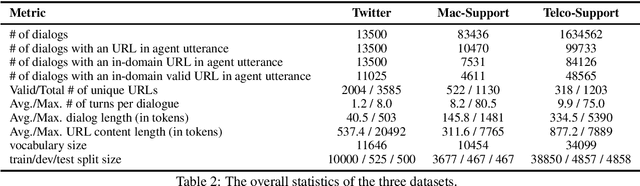

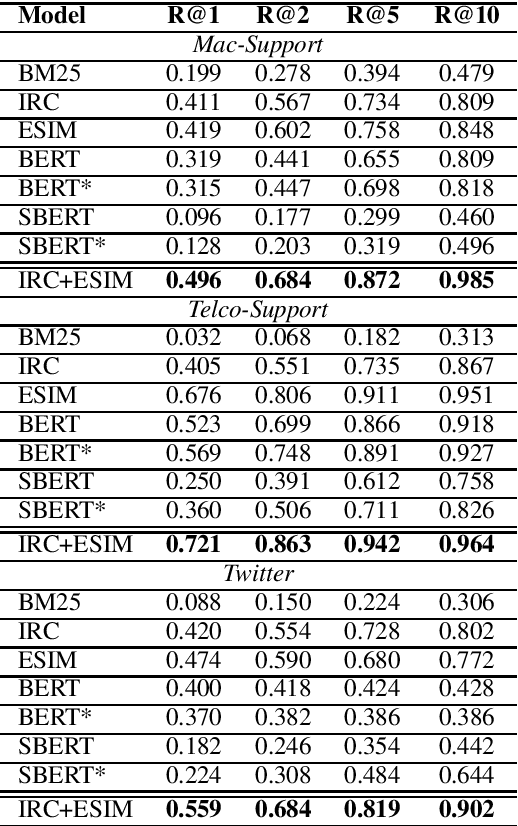
A frequent pattern in customer care conversations is the agents responding with appropriate webpage URLs that address users' needs. We study the task of predicting the documents that customer care agents can use to facilitate users' needs. We also introduce a new public dataset which supports the aforementioned problem. Using this dataset and two others, we investigate state-of-the art deep learning (DL) and information retrieval (IR) models for the task. Additionally, we analyze the practicality of such systems in terms of inference time complexity. Our show that an hybrid IR+DL approach provides the best of both worlds.