 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MLE is minimax optimal for LGC
Oct 02, 2024


We revisit the recently introduced Local Glivenko-Cantelli setting, which studies distribution-dependent uniform convegence rates of the Maximum Likelihood Estimator (MLE). In this work, we investigate generalizations of this setting where arbitrary estimators are allowed rather than just the MLE. Can a strictly larger class of measures be learned? Can better risk decay rates be obtained? We provide exhaustive answers to these questions -- which are both negative, provided the learner is barred from exploiting some infinite-dimensional pathologies. On the other hand, allowing such exploits does lead to a strictly larger class of learnable measures.
QAID: Question Answering Inspired Few-shot Intent Detection
Mar 21, 2023Intent detection with semantically similar fine-grained intents is a challenging task. To address it, we reformulate intent detection as a question-answering retrieval task by treating utterances and intent names as questions and answers. To that end, we utilize a question-answering retrieval architecture and adopt a two stages training schema with batch contrastive loss. In the pre-training stage, we improve query representations through self-supervised training. Then, in the fine-tuning stage, we increase contextualized token-level similarity scores between queries and answers from the same intent. Our results on three few-shot intent detection benchmarks achieve state-of-the-art performance.
Conversational Search with Mixed-Initiative -- Asking Good Clarification Questions backed-up by Passage Retrieval
Dec 14, 2021
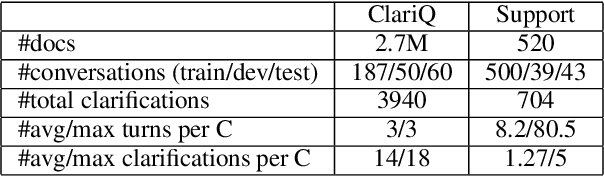
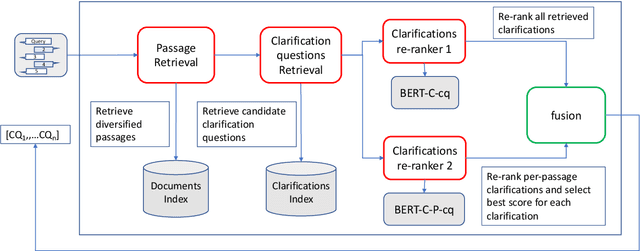
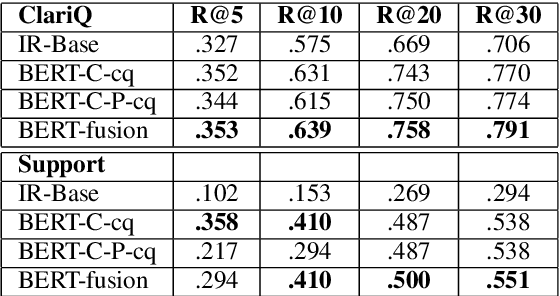
We deal with a scenario of conversational search with mixed-initiative: namely user-asks system-answers, as well as system-asks (clarification questions) and user-answers. We focus on the task of selecting the next clarification question, given conversation context. Our method leverages passage retrieval that is used both for an initial selection of relevant candidate clarification questions, as well as for fine-tuning two deep-learning models for re-ranking these candidates. We evaluated our method on two different use-cases. The first is an open domain conversational search in a large web collection. The second is a task-oriented customer-support setup. We show that our method performs well on both use-cases.
Conversational Document Prediction to Assist Customer Care Agents
Oct 05, 2020
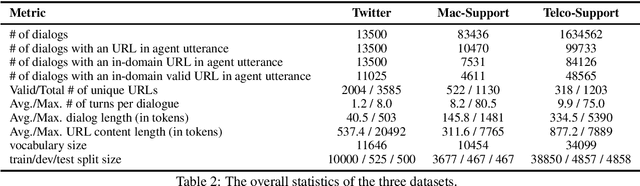

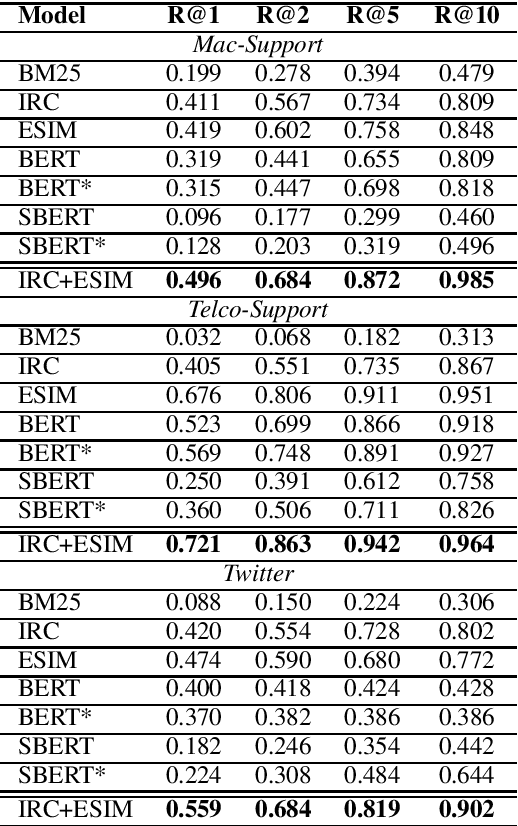
A frequent pattern in customer care conversations is the agents responding with appropriate webpage URLs that address users' needs. We study the task of predicting the documents that customer care agents can use to facilitate users' needs. We also introduce a new public dataset which supports the aforementioned problem. Using this dataset and two others, we investigate state-of-the art deep learning (DL) and information retrieval (IR) models for the task. Additionally, we analyze the practicality of such systems in terms of inference time complexity. Our show that an hybrid IR+DL approach provides the best of both worlds.
A Study of Human Summaries of Scientific Articles
Feb 10, 2020

Researchers and students face an explosion of newly published papers which may be relevant to their work. This led to a trend of sharing human summaries of scientific papers. We analyze the summaries shared in one of these platforms Shortscience.org. The goal is to characterize human summaries of scientific papers, and use some of the insights obtained to improve and adapt existing automatic summarization systems to the domain of scientific papers.
A Summarization System for Scientific Documents
Aug 29, 2019
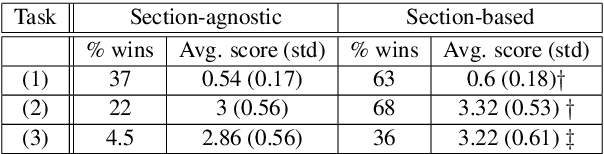

We present a novel system providing summaries for Computer Science publications. Through a qualitative user study, we identified the most valuable scenarios for discovery, exploration and understanding of scientific documents. Based on these findings, we built a system that retrieves and summarizes scientific documents for a given information need, either in form of a free-text query or by choosing categorized values such as scientific tasks, datasets and more. Our system ingested 270,000 papers, and its summarization module aims to generate concise yet detailed summaries. We validated our approach with human experts.
Unsupervised Dual-Cascade Learning with Pseudo-Feedback Distillation for Query-based Extractive Summarization
Nov 01, 2018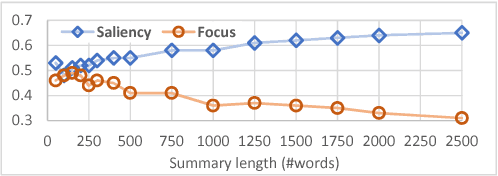
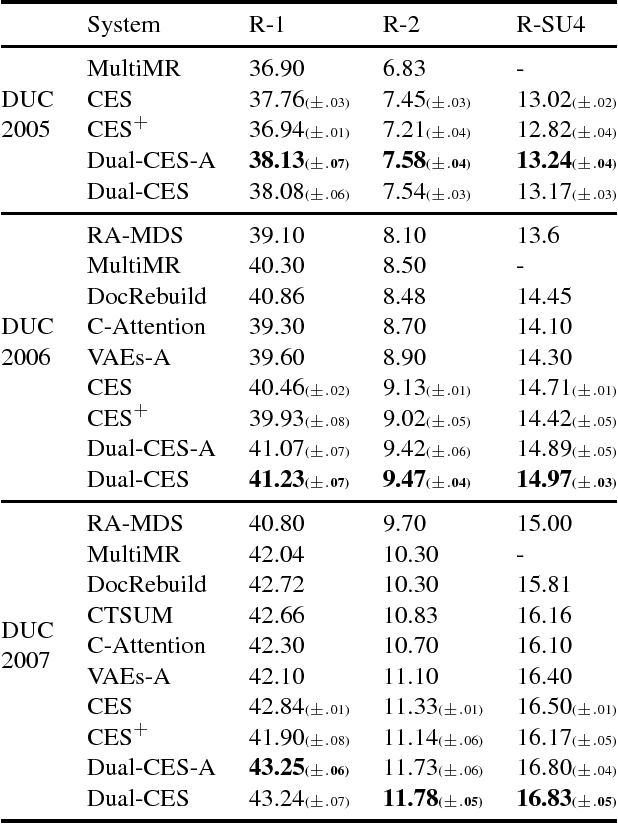
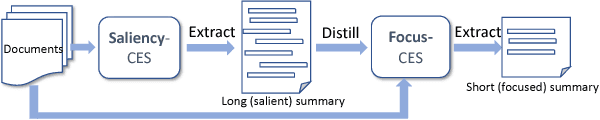
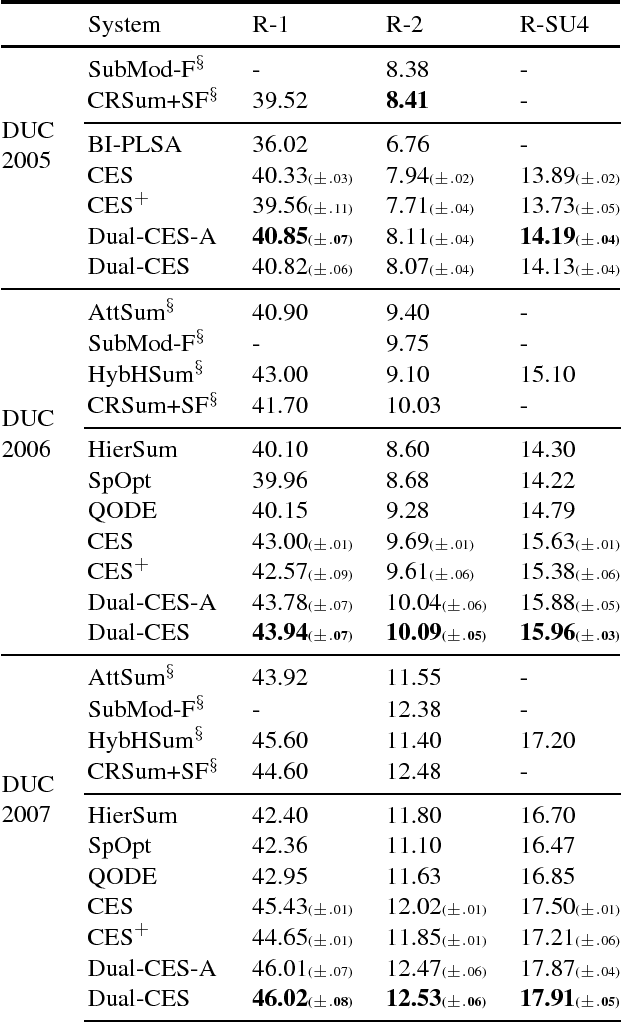
We propose Dual-CES -- a novel unsupervised, query-focused, multi-document extractive summarizer. Dual-CES is designed to better handle the tradeoff between saliency and focus in summarization. To this end, Dual-CES employs a two-step dual-cascade optimization approach with saliency-based pseudo-feedback distillation. Overall, Dual-CES significantly outperforms all other state-of-the-art unsupervised alternatives. Dual-CES is even shown to be able to outperform strong supervised summarizers.