 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MLE is minimax optimal for LGC
Oct 02, 2024


We revisit the recently introduced Local Glivenko-Cantelli setting, which studies distribution-dependent uniform convegence rates of the Maximum Likelihood Estimator (MLE). In this work, we investigate generalizations of this setting where arbitrary estimators are allowed rather than just the MLE. Can a strictly larger class of measures be learned? Can better risk decay rates be obtained? We provide exhaustive answers to these questions -- which are both negative, provided the learner is barred from exploiting some infinite-dimensional pathologies. On the other hand, allowing such exploits does lead to a strictly larger class of learnable measures.
Resilience of the quadratic Littlewood-Offord problem
Feb 16, 2024We study the statistical resilience of high-dimensional data. Our results provide estimates as to the effects of adversarial noise over the anti-concentration properties of the quadratic Radamecher chaos $\boldsymbol{\xi}^{\mathsf{T}} M \boldsymbol{\xi}$, where $M$ is a fixed (high-dimensional) matrix and $\boldsymbol{\xi}$ is a conformal Rademacher vector. Specifically, we pursue the question of how many adversarial sign-flips can $\boldsymbol{\xi}$ sustain without "inflating" $\sup_{x\in \mathbb{R}} \mathbb{P} \left\{\boldsymbol{\xi}^{\mathsf{T}} M \boldsymbol{\xi} = x\right\}$ and thus "de-smooth" the original distribution resulting in a more "grainy" and adversarially biased distribution. Our results provide lower bound estimations for the statistical resilience of the quadratic and bilinear Rademacher chaos; these are shown to be asymptotically tight across key regimes.
Weighted Distance Nearest Neighbor Condensing
Oct 24, 2023The problem of nearest neighbor condensing has enjoyed a long history of study, both in its theoretical and practical aspects. In this paper, we introduce the problem of weighted distance nearest neighbor condensing, where one assigns weights to each point of the condensed set, and then new points are labeled based on their weighted distance nearest neighbor in the condensed set. We study the theoretical properties of this new model, and show that it can produce dramatically better condensing than the standard nearest neighbor rule, yet is characterized by generalization bounds almost identical to the latter. We then suggest a condensing heuristic for our new problem. We demonstrate Bayes consistency for this heuristic, and also show promising empirical results.
Leveraging the Triple Exponential Moving Average for Fast-Adaptive Moment Estimation
Jun 02, 2023Network optimization is a crucial step in the field of deep learning, as it directly affects the performance of models in various domains such as computer vision. Despite the numerous optimizers that have been developed over the years, the current methods are still limited in their ability to accurately and quickly identify gradient trends, which can lead to sub-optimal network performance. In this paper, we propose a novel deep optimizer called Fast-Adaptive Moment Estimation (FAME), which for the first time estimates gradient moments using a Triple Exponential Moving Average (TEMA). Incorporating TEMA into the optimization process provides richer and more accurate information on data changes and trends, as compared to the standard Exponential Moving Average used in essentially all current leading adaptive optimization methods. Our proposed FAME optimizer has been extensively validated through a wide range of benchmarks, including CIFAR-10, CIFAR-100, PASCAL-VOC, MS-COCO, and Cityscapes, using 14 different learning architectures, six optimizers, and various vision tasks, including detection, classification and semantic understanding. The results demonstrate that our FAME optimizer outperforms other leading optimizers in terms of both robustness and accuracy.
On Error and Compression Rates for Prototype Rules
Jun 16, 2022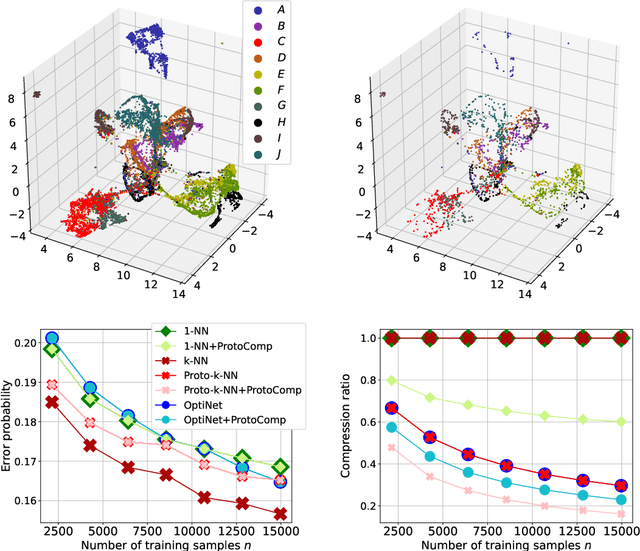

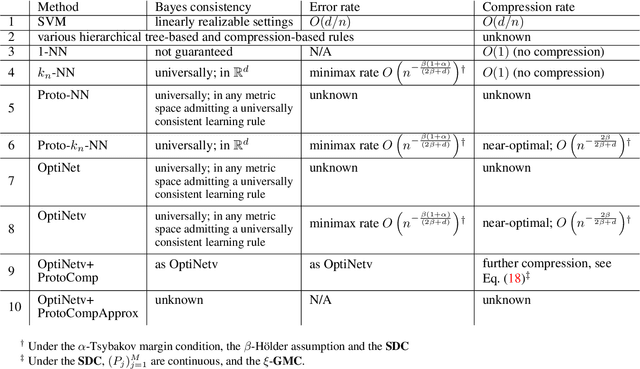
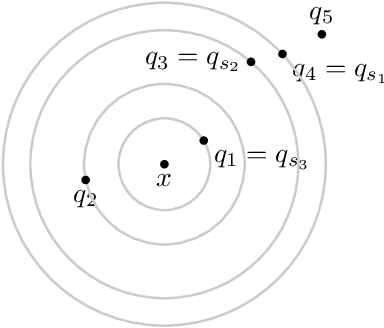
We study the close interplay between error and compression in the non-parametric multiclass classification setting in terms of prototype learning rules. We focus in particular on a close variant of a recently proposed compression-based learning rule termed OptiNet. Beyond its computational merits, this rule has been recently shown to be universally consistent in any metric instance space that admits a universally consistent rule -- the first learning algorithm known to enjoy this property. However, its error and compression rates have been left open. Here we derive such rates in the case where instances reside in Euclidean space under commonly posed smoothness and tail conditions on the data distribution. We first show that OptiNet achieves non-trivial compression rates while enjoying near minimax-optimal error rates. We then proceed to study a novel general compression scheme for further compressing prototype rules that locally adapts to the noise level without sacrificing accuracy. Applying it to OptiNet, we show that under a geometric margin condition, further gain in the compression rate is achieved. Experimental results comparing the performance of the various methods are presented.
Tree density estimation
Nov 25, 2021We study the problem of density estimation for a random vector ${\boldsymbol X}$ in $\mathbb R^d$ with probability density $f(\boldsymbol x)$. For a spanning tree $T$ defined on the vertex set $\{1,\dots ,d\}$, the tree density $f_{T}$ is a product of bivariate conditional densities. The optimal spanning tree $T^*$ is the spanning tree $T$, for which the Kullback-Leibler divergence of $f$ and $f_{T}$ is the smallest. From i.i.d. data we identify the optimal tree $T^*$ and computationally efficiently construct a tree density estimate $f_n$ such that, without any regularity conditions on the density $f$, one has that $\lim_{n\to \infty} \int |f_n(\boldsymbol x)-f_{T^*}(\boldsymbol x)|d\boldsymbol x=0$ a.s. For Lipschitz continuous $f$ with bounded support, $\mathbb E\{ \int |f_n(\boldsymbol x)-f_{T^*}(\boldsymbol x)|d\boldsymbol x\}=O(n^{-1/4})$.
Universal consistency and rates of convergence of multiclass prototype algorithms in metric spaces
Oct 01, 2020We study universal consistency and convergence rates of simple nearest-neighbor prototype rules for the problem of multiclass classification in metric paces. We first show that a novel data-dependent partitioning rule, named Proto-NN, is universally consistent in any metric space that admits a universally consistent rule. Proto-NN is a significant simplification of OptiNet, a recently proposed compression-based algorithm that, to date, was the only algorithm known to be universally consistent in such a general setting. Practically, Proto-NN is simpler to implement and enjoys reduced computational complexity. We then proceed to study convergence rates of the excess error probability. We first obtain rates for the standard $k$-NN rule under a margin condition and a new generalized-Lipschitz condition. The latter is an extension of a recently proposed modified-Lipschitz condition from $\mathbb R^d$ to metric spaces. Similarly to the modified-Lipschitz condition, the new condition avoids any boundness assumptions on the data distribution. While obtaining rates for Proto-NN is left open, we show that a second prototype rule that hybridizes between $k$-NN and Proto-NN achieves the same rates as $k$-NN while enjoying similar computational advantages as Proto-NN. We conjecture however that, as $k$-NN, this hybrid rule is not consistent in general.
Universal Bayes consistency in metric spaces
Jun 26, 2019
We show that a recently proposed 1-nearest-neighbor-based multiclass learning algorithm is universally strongly Bayes consistent in all metric spaces where such Bayes consistency is possible, making it an optimistically universal Bayes-consistent learner. This is the first learning algorithm known to enjoy this property; by comparison, $k$-NN and its variants are not generally universally Bayes consistent, except under additional structural assumptions, such as an inner product, a norm, finite doubling dimension, or a Besicovitch-type property. The metric spaces in which universal Bayes consistency is possible are the essentially separable ones --- a new notion that we define, which is more general than standard separability. The existence of metric spaces that are not essentially separable is independent of the ZFC axioms of set theory. We prove that essential separability exactly characterizes the existence of a universal Bayes-consistent learner for the given metric space. In particular, this yields the first impossibility result for universal Bayes consistency. Taken together, these positive and negative results resolve the open problems posed in Kontorovich, Sabato, Weiss (2017).
A Bayes consistent 1-NN classifier
Aug 17, 2018

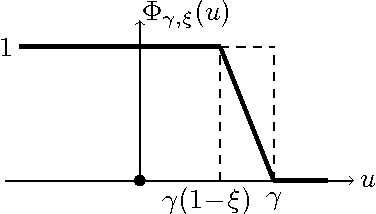
We show that a simple modification of the 1-nearest neighbor classifier yields a strongly Bayes consistent learner. Prior to this work, the only strongly Bayes consistent proximity-based method was the k-nearest neighbor classifier, for k growing appropriately with sample size. We will argue that a margin-regularized 1-NN enjoys considerable statistical and algorithmic advantages over the k-NN classifier. These include user-friendly finite-sample error bounds, as well as time- and memory-efficient learning and test-point evaluation algorithms with a principled speed-accuracy tradeoff. Encouraging empirical results are reported.
Learning Binary Latent Variable Models: A Tensor Eigenpair Approach
Feb 27, 2018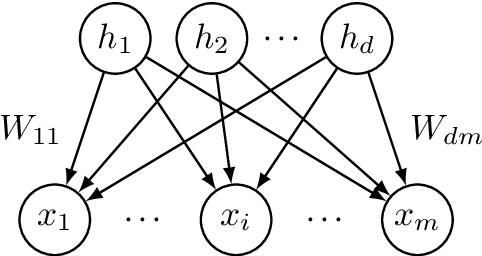
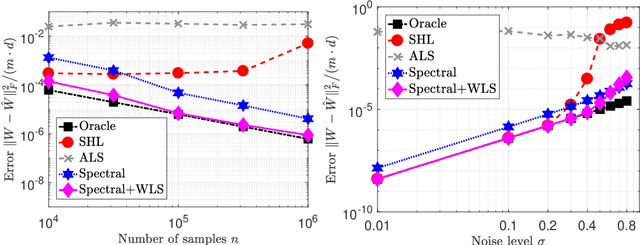
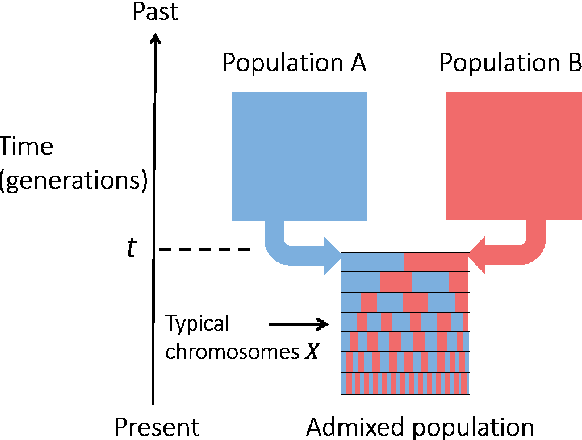
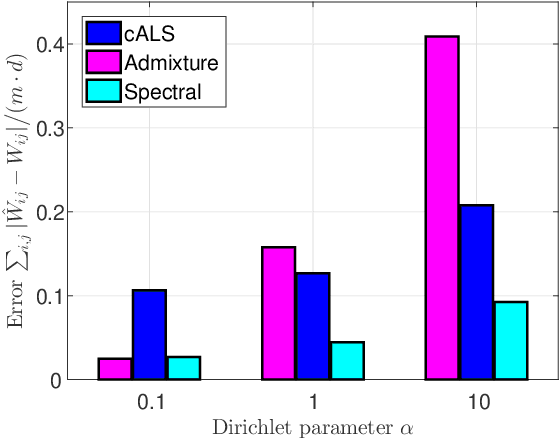
Latent variable models with hidden binary units appear in various applications. Learning such models, in particular in the presence of noise, is a challenging computational problem. In this paper we propose a novel spectral approach to this problem, based on the eigenvectors of both the second order moment matrix and third order moment tensor of the observed data. We prove that under mild non-degeneracy conditions, our method consistently estimates the model parameters at the optimal parametric rate. Our tensor-based method generalizes previous orthogonal tensor decomposition approaches, where the hidden units were assumed to be either statistically independent or mutually exclusive. We illustrate the consistency of our method on simulated data and demonstrate its usefulness in learning a common model for population mixtures in genetics.